 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformed, but Not Always Improved: Challenging the Benefit of Background Knowledge in GNNs
May 16, 2025In complex and low-data domains such as biomedical research, incorporating background knowledge (BK) graphs, such as protein-protein interaction (PPI) networks, into graph-based machine learning pipelines is a promising research direction. However, while BK is often assumed to improve model performance, its actual contribution and the impact of imperfect knowledge remain poorly understood. In this work, we investigate the role of BK in an important real-world task: cancer subtype classification. Surprisingly, we find that (i) state-of-the-art GNNs using BK perform no better than uninformed models like linear regression, and (ii) their performance remains largely unchanged even when the BK graph is heavily perturbed. To understand these unexpected results, we introduce an evaluation framework, which employs (i) a synthetic setting where the BK is clearly informative and (ii) a set of perturbations that simulate various imperfections in BK graphs. With this, we test the robustness of BK-aware models in both synthetic and real-world biomedical settings. Our findings reveal that careful alignment of GNN architectures and BK characteristics is necessary but holds the potential for significant performance improvements.
SubROC: AUC-Based Discovery of Exceptional Subgroup Performance for Binary Classifiers
May 16, 2025Machine learning (ML) is increasingly employed in real-world applications like medicine or economics, thus, potentially affecting large populations. However, ML models often do not perform homogeneously across such populations resulting in subgroups of the population (e.g., sex=female AND marital_status=married) where the model underperforms or, conversely, is particularly accurate. Identifying and describing such subgroups can support practical decisions on which subpopulation a model is safe to deploy or where more training data is required. The potential of identifying and analyzing such subgroups has been recognized, however, an efficient and coherent framework for effective search is missing. Consequently, we introduce SubROC, an open-source, easy-to-use framework based on Exceptional Model Mining for reliably and efficiently finding strengths and weaknesses of classification models in the form of interpretable population subgroups. SubROC incorporates common evaluation measures (ROC and PR AUC), efficient search space pruning for fast exhaustive subgroup search, control for class imbalance, adjustment for redundant patterns, and significance testing. We illustrate the practical benefits of SubROC in case studies as well as in comparative analyses across multiple datasets.
Evolving Markov Chains: Unsupervised Mode Discovery and Recognition from Data Streams
Nov 26, 2024

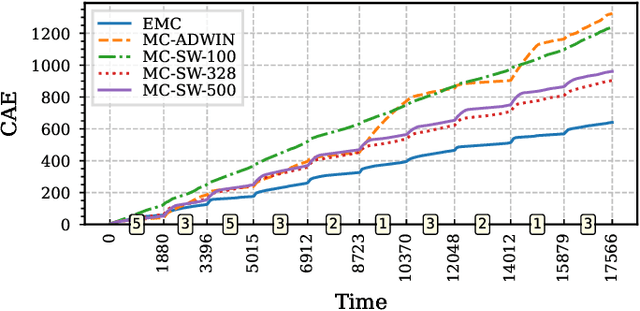

Markov chains are simple yet powerful mathematical structures to model temporally dependent processes. They generally assume stationary data, i.e., fixed transition probabilities between observations/states. However, live, real-world processes, like in the context of activity tracking, biological time series, or industrial monitoring, often switch behavior over time. Such behavior switches can be modeled as transitions between higher-level \emph{modes} (e.g., running, walking, etc.). Yet all modes are usually not previously known, often exhibit vastly differing transition probabilities, and can switch unpredictably. Thus, to track behavior changes of live, real-world processes, this study proposes an online and efficient method to construct Evolving Markov chains (EMCs). EMCs adaptively track transition probabilities, automatically discover modes, and detect mode switches in an online manner. In contrast to previous work, EMCs are of arbitrary order, the proposed update scheme does not rely on tracking windows, only updates the relevant region of the probability tensor, and enjoys geometric convergence of the expected estimates. Our evaluation of synthetic data and real-world applications on human activity recognition, electric motor condition monitoring, and eye-state recognition from electroencephalography (EEG) measurements illustrates the versatility of the approach and points to the potential of EMCs to efficiently track, model, and understand live, real-world processes.
Redescription Model Mining
Jul 09, 2021
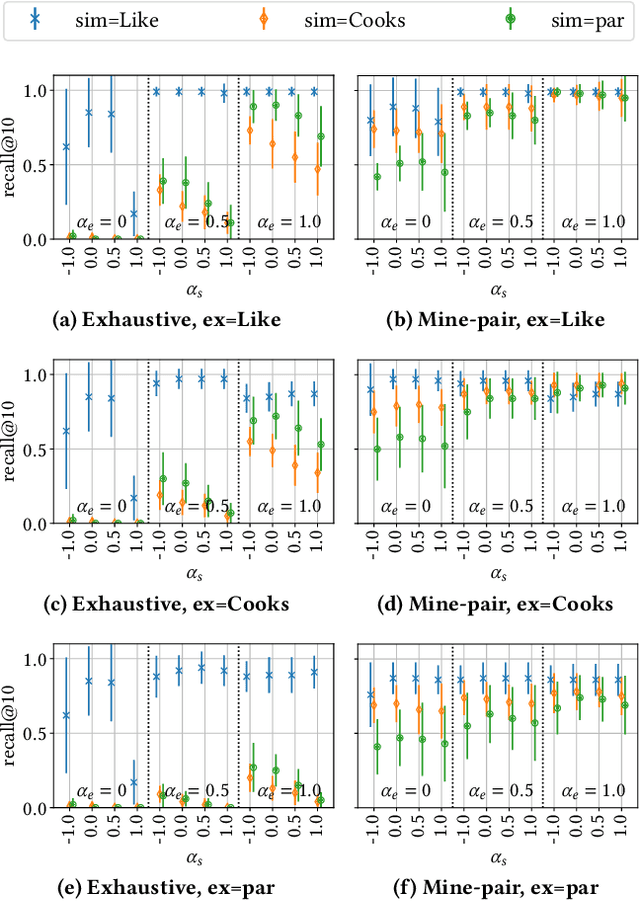
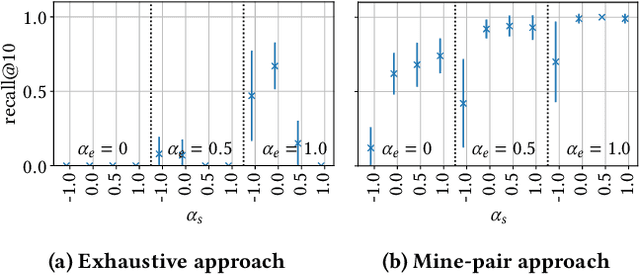
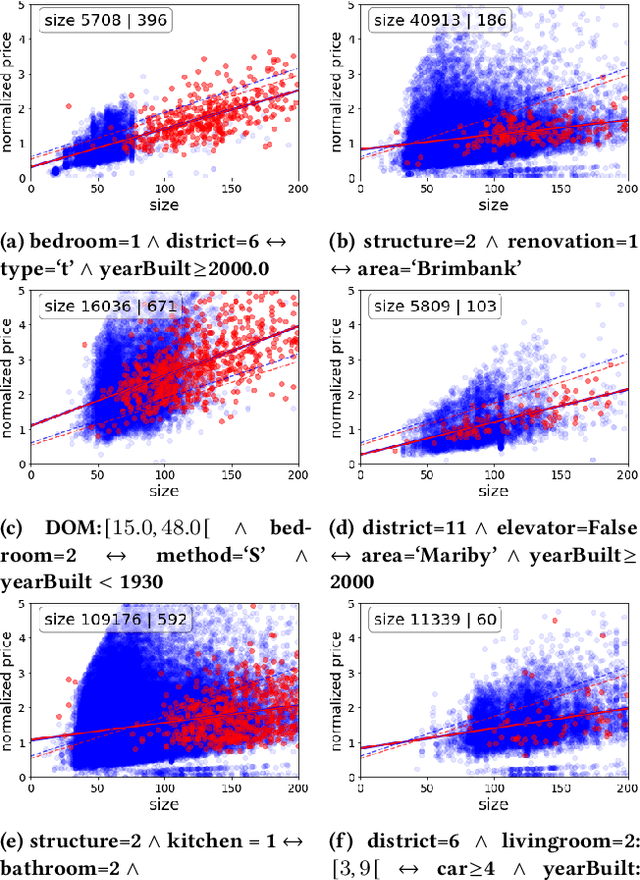
This paper introduces Redescription Model Mining, a novel approach to identify interpretable patterns across two datasets that share only a subset of attributes and have no common instances. In particular, Redescription Model Mining aims to find pairs of describable data subsets -- one for each dataset -- that induce similar exceptional models with respect to a prespecified model class. To achieve this, we combine two previously separate research areas: Exceptional Model Mining and Redescription Mining. For this new problem setting, we develop interestingness measures to select promising patterns, propose efficient algorithms, and demonstrate their potential on synthetic and real-world data. Uncovered patterns can hint at common underlying phenomena that manifest themselves across datasets, enabling the discovery of possible associations between (combinations of) attributes that do not appear in the same dataset.
MapLUR: Exploring a new Paradigm for Estimating Air Pollution using Deep Learning on Map Images
Feb 18, 2020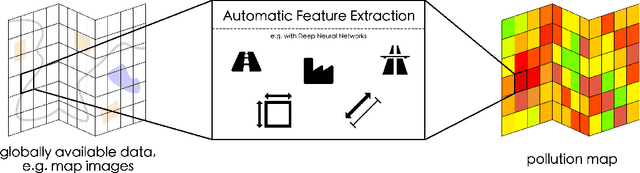
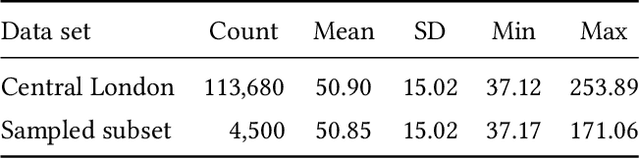
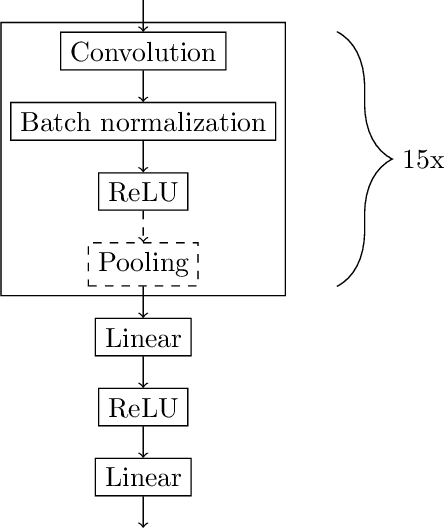

Land-use regression (LUR) models are important for the assessment of air pollution concentrations in areas without measurement stations. While many such models exist, they often use manually constructed features based on restricted, locally available data. Thus, they are typically hard to reproduce and challenging to adapt to areas beyond those they have been developed for. In this paper, we advocate a paradigm shift for LUR models: We propose the Data-driven, Open, Global (DOG) paradigm that entails models based on purely data-driven approaches using only openly and globally available data. Progress within this paradigm will alleviate the need for experts to adapt models to the local characteristics of the available data sources and thus facilitate the generalizability of air pollution models to new areas on a global scale. In order to illustrate the feasibility of the DOG paradigm for LUR, we introduce a deep learning model called MapLUR. It is based on a convolutional neural network architecture and is trained exclusively on globally and openly available map data without requiring manual feature engineering. We compare our model to state-of-the-art baselines like linear regression, random forests and multi-layer perceptrons using a large data set of modeled $\text{NO}_2$ concentrations in Central London. Our results show that MapLUR significantly outperforms these approaches even though they are provided with manually tailored features. Furthermore, we illustrate that the automatic feature extraction inherent to models based on the DOG paradigm can learn features that are readily interpretable and closely resemble those commonly used in traditional LUR approaches.
Adaptive kNN using Expected Accuracy for Classification of Geo-Spatial Data
Dec 14, 2017

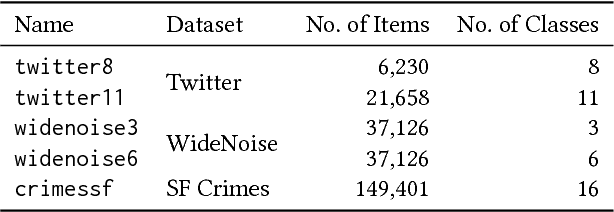
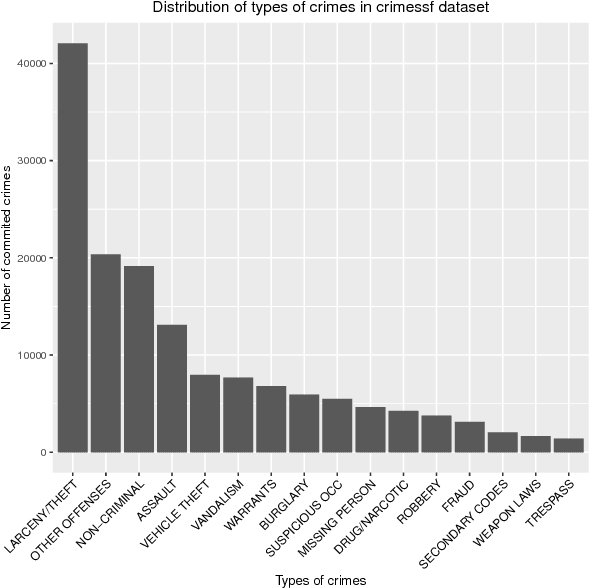
The k-Nearest Neighbor (kNN) classification approach is conceptually simple - yet widely applied since it often performs well in practical applications. However, using a global constant k does not always provide an optimal solution, e.g., for datasets with an irregular density distribution of data points. This paper proposes an adaptive kNN classifier where k is chosen dynamically for each instance (point) to be classified, such that the expected accuracy of classification is maximized. We define the expected accuracy as the accuracy of a set of structurally similar observations. An arbitrary similarity function can be used to find these observations. We introduce and evaluate different similarity functions. For the evaluation, we use five different classification tasks based on geo-spatial data. Each classification task consists of (tens of) thousands of items. We demonstrate, that the presented expected accuracy measures can be a good estimator for kNN performance, and the proposed adaptive kNN classifier outperforms common kNN and previously introduced adaptive kNN algorithms. Also, we show that the range of considered k can be significantly reduced to speed up the algorithm without negative influence on classification accuracy.
Learning Semantic Relatedness From Human Feedback Using Metric Learning
May 24, 2017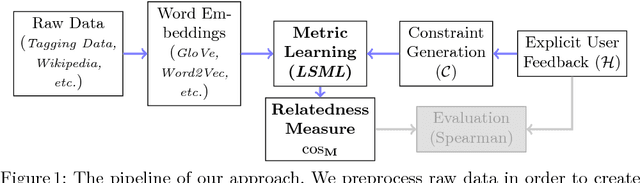
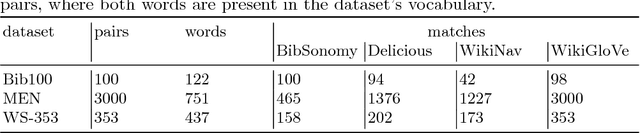
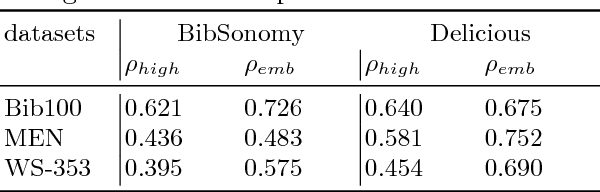
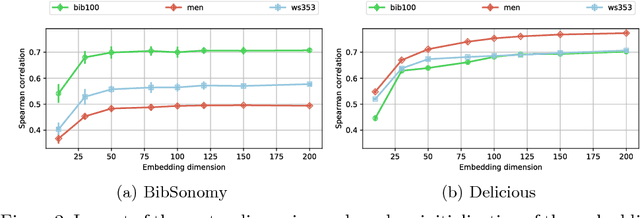
Assessing the degree of semantic relatedness between words is an important task with a variety of semantic applications, such as ontology learning for the Semantic Web, semantic search or query expansion. To accomplish this in an automated fashion, many relatedness measures have been proposed. However, most of these metrics only encode information contained in the underlying corpus and thus do not directly model human intuition. To solve this, we propose to utilize a metric learning approach to improve existing semantic relatedness measures by learning from additional information, such as explicit human feedback. For this, we argue to use word embeddings instead of traditional high-dimensional vector representations in order to leverage their semantic density and to reduce computational cost. We rigorously test our approach on several domains including tagging data as well as publicly available embeddings based on Wikipedia texts and navigation. Human feedback about semantic relatedness for learning and evaluation is extracted from publicly available datasets such as MEN or WS-353. We find that our method can significantly improve semantic relatedness measures by learning from additional information, such as explicit human feedback. For tagging data, we are the first to generate and study embeddings. Our results are of special interest for ontology and recommendation engineers, but also for any other researchers and practitioners of Semantic Web techniques.
Analyzing Features for the Detection of Happy Endings in German Novels
Nov 28, 2016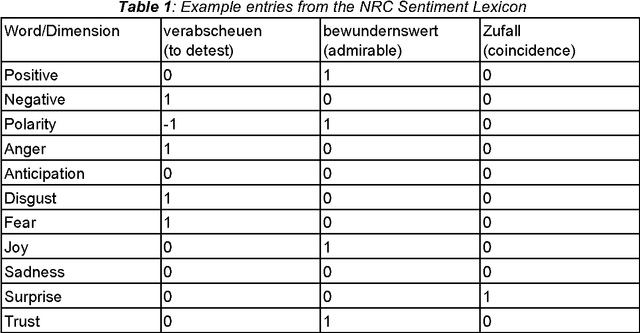
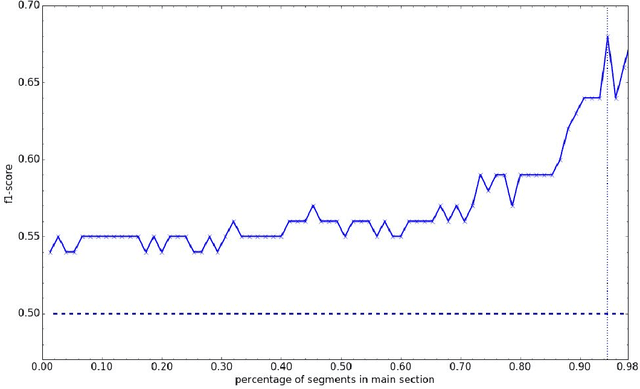
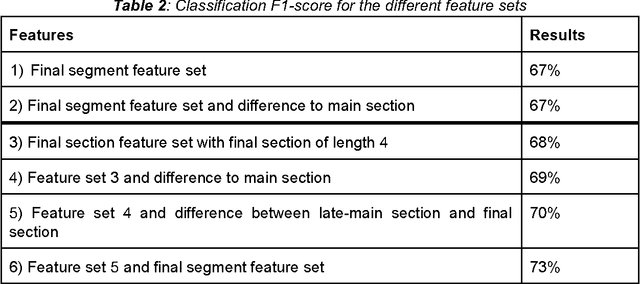
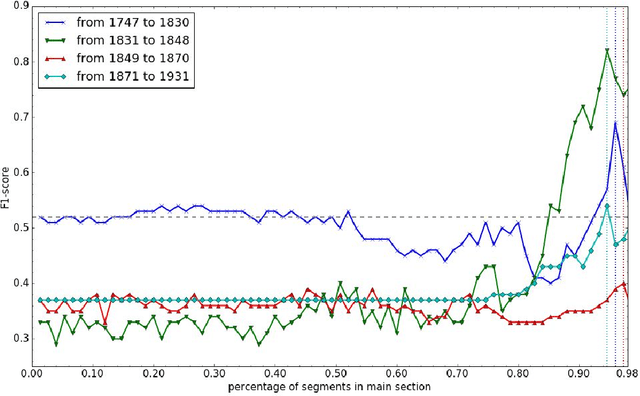
With regard to a computational representation of literary plot, this paper looks at the use of sentiment analysis for happy ending detection in German novels. Its focus lies on the investigation of previously proposed sentiment features in order to gain insight about the relevance of specific features on the one hand and the implications of their performance on the other hand. Therefore, we study various partitionings of novels, considering the highly variable concept of "ending". We also show that our approach, even though still rather simple, can potentially lead to substantial findings relevant to literary studies.