 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtensible Motion-based Identification of XR Users with Non-Specific Motion
Feb 15, 2023Recently emerged solutions demonstrate that the movements of users interacting with extended reality (XR) applications carry identifying information and can be leveraged for identification. While such solutions can identify XR users within a few seconds, current systems require one or the other trade-off: either they apply simple distance-based approaches that can only be used for specific predetermined motions. Or they use classification-based approaches that use more powerful machine learning models and thus also work for arbitrary motions, but require full retraining to enroll new users, which can be prohibitively expensive. In this paper, we propose to combine the strengths of both approaches by using an embedding-based approach that leverages deep metric learning. We train the model on a dataset of users playing the VR game "Half-Life: Alyx" and conduct multiple experiments and analyses. The results show that the embedding-based method 1) is able to identify new users from non-specific movements using only a few minutes of reference data, 2) can enroll new users within seconds, while retraining a comparable classification-based approach takes almost a day, 3) is more reliable than a baseline classification-based approach when only little reference data is available, 4) can be used to identify new users from another dataset recorded with different VR devices. Altogether, our solution is a foundation for easily extensible XR user identification systems, applicable even to non-specific movements. It also paves the way for production-ready models that could be used by XR practitioners without the requirements of expertise, hardware, or data for training deep learning models.
InDiReCT: Language-Guided Zero-Shot Deep Metric Learning for Images
Nov 23, 2022Common Deep Metric Learning (DML) datasets specify only one notion of similarity, e.g., two images in the Cars196 dataset are deemed similar if they show the same car model. We argue that depending on the application, users of image retrieval systems have different and changing similarity notions that should be incorporated as easily as possible. Therefore, we present Language-Guided Zero-Shot Deep Metric Learning (LanZ-DML) as a new DML setting in which users control the properties that should be important for image representations without training data by only using natural language. To this end, we propose InDiReCT (Image representations using Dimensionality Reduction on CLIP embedded Texts), a model for LanZ-DML on images that exclusively uses a few text prompts for training. InDiReCT utilizes CLIP as a fixed feature extractor for images and texts and transfers the variation in text prompt embeddings to the image embedding space. Extensive experiments on five datasets and overall thirteen similarity notions show that, despite not seeing any images during training, InDiReCT performs better than strong baselines and approaches the performance of fully-supervised models. An analysis reveals that InDiReCT learns to focus on regions of the image that correlate with the desired similarity notion, which makes it a fast to train and easy to use method to create custom embedding spaces only using natural language.
On Background Bias in Deep Metric Learning
Oct 04, 2022
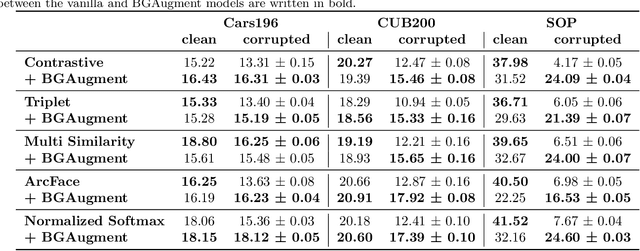

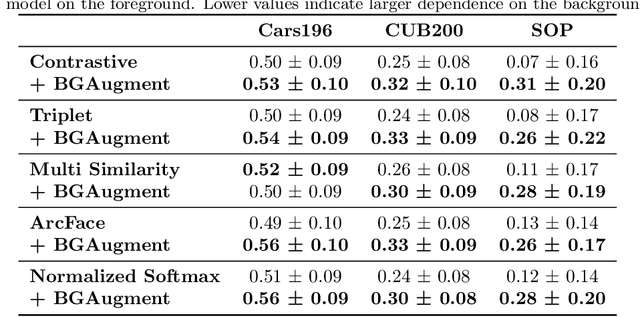
Deep Metric Learning trains a neural network to map input images to a lower-dimensional embedding space such that similar images are closer together than dissimilar images. When used for item retrieval, a query image is embedded using the trained model and the closest items from a database storing their respective embeddings are returned as the most similar items for the query. Especially in product retrieval, where a user searches for a certain product by taking a photo of it, the image background is usually not important and thus should not influence the embedding process. Ideally, the retrieval process always returns fitting items for the photographed object, regardless of the environment the photo was taken in. In this paper, we analyze the influence of the image background on Deep Metric Learning models by utilizing five common loss functions and three common datasets. We find that Deep Metric Learning networks are prone to so-called background bias, which can lead to a severe decrease in retrieval performance when changing the image background during inference. We also show that replacing the background of images during training with random background images alleviates this issue. Since we use an automatic background removal method to do this background replacement, no additional manual labeling work and model changes are required while inference time stays the same. Qualitative and quantitative analyses, for which we introduce a new evaluation metric, confirm that models trained with replaced backgrounds attend more to the main object in the image, benefitting item retrieval systems.
Do Different Deep Metric Learning Losses Lead to Similar Learned Features?
May 05, 2022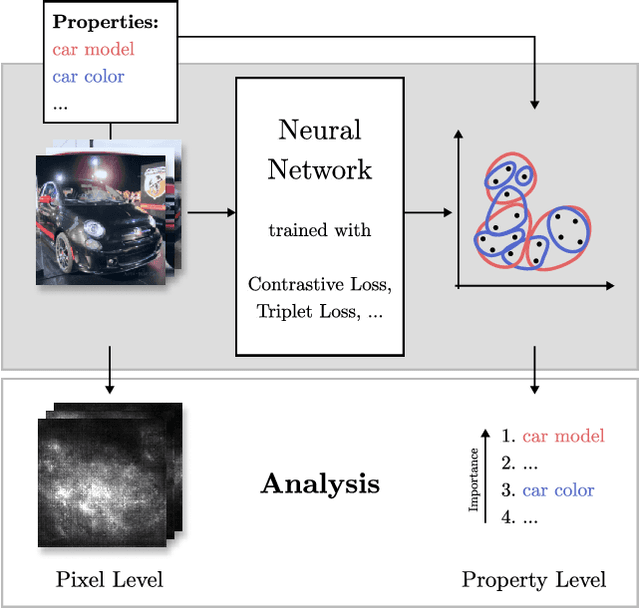
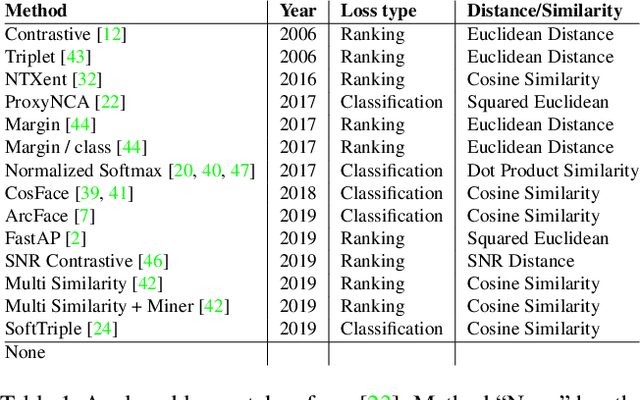
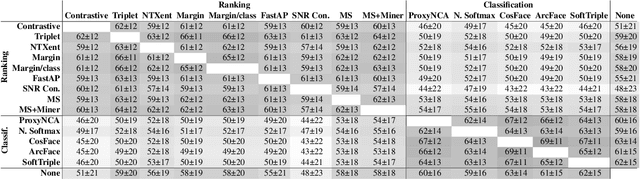

Recent studies have shown that many deep metric learning loss functions perform very similarly under the same experimental conditions. One potential reason for this unexpected result is that all losses let the network focus on similar image regions or properties. In this paper, we investigate this by conducting a two-step analysis to extract and compare the learned visual features of the same model architecture trained with different loss functions: First, we compare the learned features on the pixel level by correlating saliency maps of the same input images. Second, we compare the clustering of embeddings for several image properties, e.g. object color or illumination. To provide independent control over these properties, photo-realistic 3D car renders similar to images in the Cars196 dataset are generated. In our analysis, we compare 14 pretrained models from a recent study and find that, even though all models perform similarly, different loss functions can guide the model to learn different features. We especially find differences between classification and ranking based losses. Our analysis also shows that some seemingly irrelevant properties can have significant influence on the resulting embedding. We encourage researchers from the deep metric learning community to use our methods to get insights into the features learned by their proposed methods.
NICER: Aesthetic Image Enhancement with Humans in the Loop
Dec 03, 2020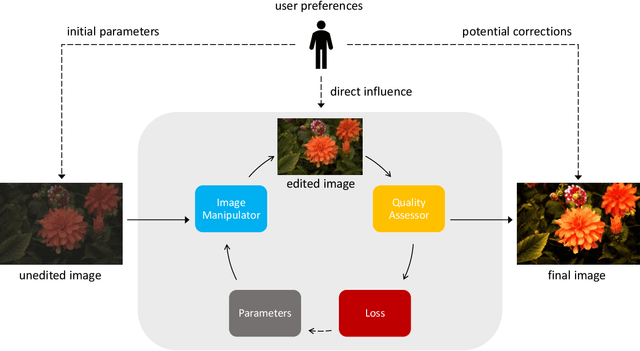
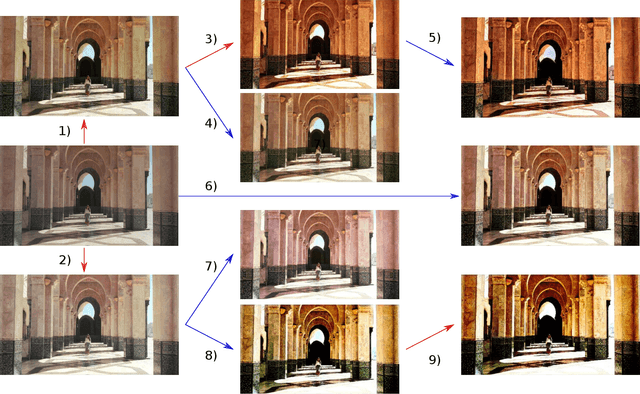
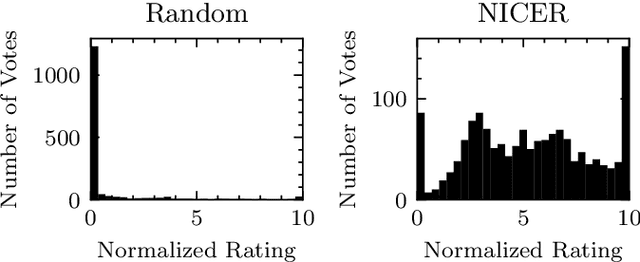

Fully- or semi-automatic image enhancement software helps users to increase the visual appeal of photos and does not require in-depth knowledge of manual image editing. However, fully-automatic approaches usually enhance the image in a black-box manner that does not give the user any control over the optimization process, possibly leading to edited images that do not subjectively appeal to the user. Semi-automatic methods mostly allow for controlling which pre-defined editing step is taken, which restricts the users in their creativity and ability to make detailed adjustments, such as brightness or contrast. We argue that incorporating user preferences by guiding an automated enhancement method simplifies image editing and increases the enhancement's focus on the user. This work thus proposes the Neural Image Correction & Enhancement Routine (NICER), a neural network based approach to no-reference image enhancement in a fully-, semi-automatic or fully manual process that is interactive and user-centered. NICER iteratively adjusts image editing parameters in order to maximize an aesthetic score based on image style and content. Users can modify these parameters at any time and guide the optimization process towards a desired direction. This interactive workflow is a novelty in the field of human-computer interaction for image enhancement tasks. In a user study, we show that NICER can improve image aesthetics without user interaction and that allowing user interaction leads to diverse enhancement outcomes that are strongly preferred over the unedited image. We make our code publicly available to facilitate further research in this direction.
* The code can be found at https://github.com/mr-Mojo/NICER
Anomaly Detection in Beehives using Deep Recurrent Autoencoders
Mar 10, 2020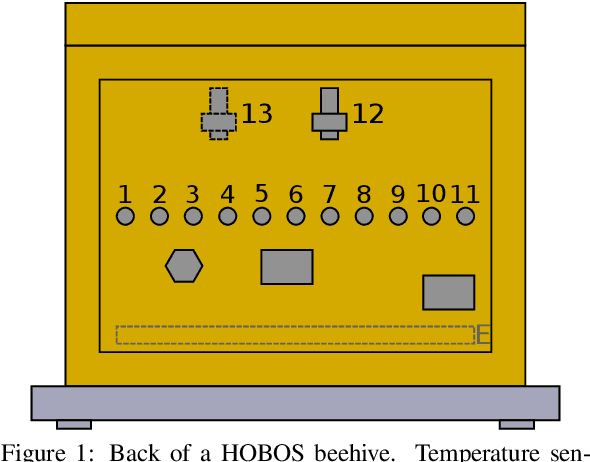
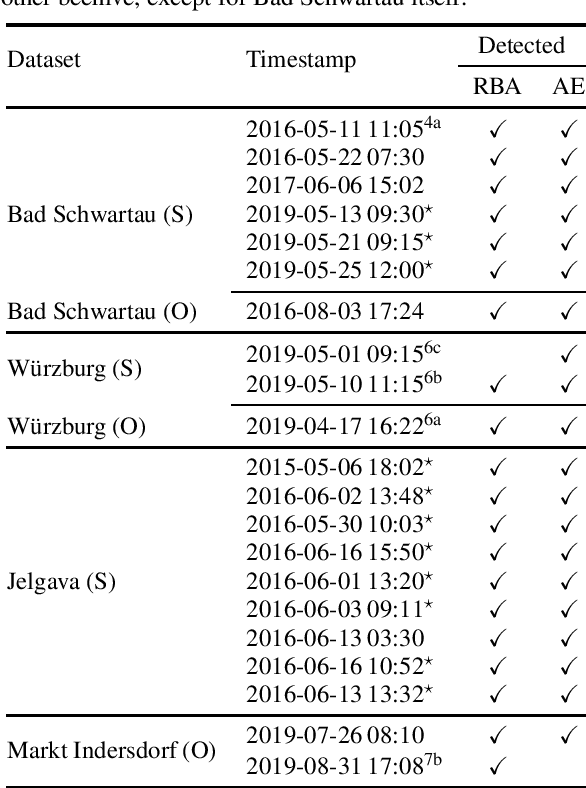
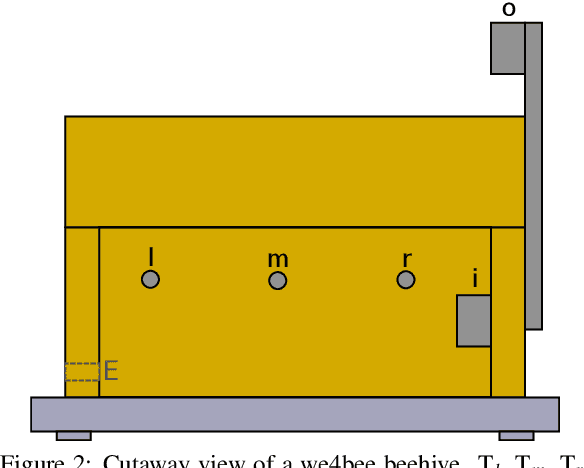
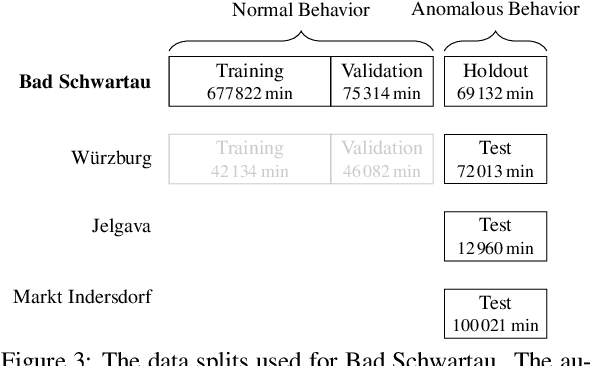
Precision beekeeping allows to monitor bees' living conditions by equipping beehives with sensors. The data recorded by these hives can be analyzed by machine learning models to learn behavioral patterns of or search for unusual events in bee colonies. One typical target is the early detection of bee swarming as apiarists want to avoid this due to economical reasons. Advanced methods should be able to detect any other unusual or abnormal behavior arising from illness of bees or from technical reasons, e.g. sensor failure. In this position paper we present an autoencoder, a deep learning model, which detects any type of anomaly in data independent of its origin. Our model is able to reveal the same swarms as a simple rule-based swarm detection algorithm but is also triggered by any other anomaly. We evaluated our model on real world data sets that were collected on different hives and with different sensor setups.
SimLoss: Class Similarities in Cross Entropy
Mar 06, 2020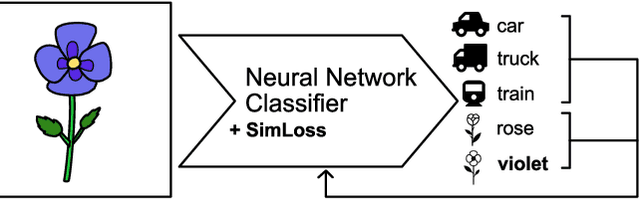
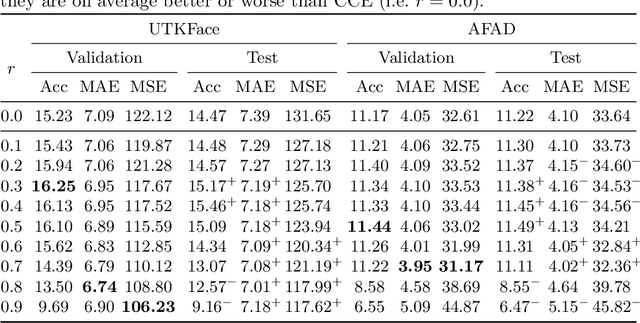
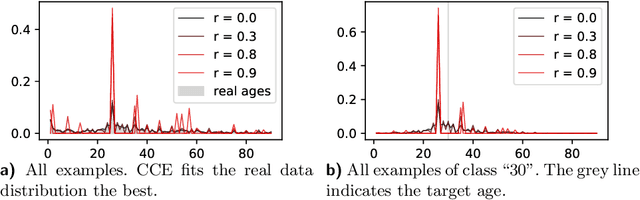
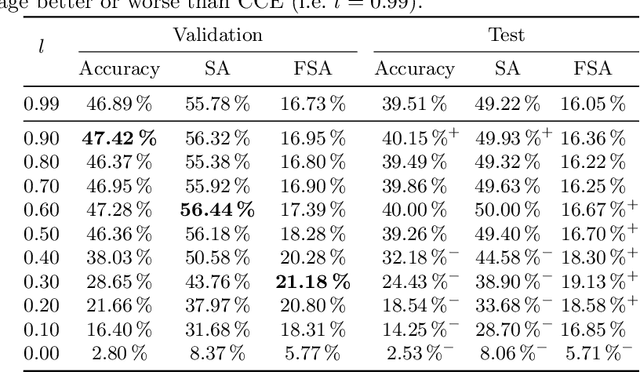
One common loss function in neural network classification tasks is Categorical Cross Entropy (CCE), which punishes all misclassifications equally. However, classes often have an inherent structure. For instance, classifying an image of a rose as "violet" is better than as "truck". We introduce SimLoss, a drop-in replacement for CCE that incorporates class similarities along with two techniques to construct such matrices from task-specific knowledge. We test SimLoss on Age Estimation and Image Classification and find that it brings significant improvements over CCE on several metrics. SimLoss therefore allows for explicit modeling of background knowledge by simply exchanging the loss function, while keeping the neural network architecture the same. Code and additional resources can be found at https://github.com/konstantinkobs/SimLoss.
MapLUR: Exploring a new Paradigm for Estimating Air Pollution using Deep Learning on Map Images
Feb 18, 2020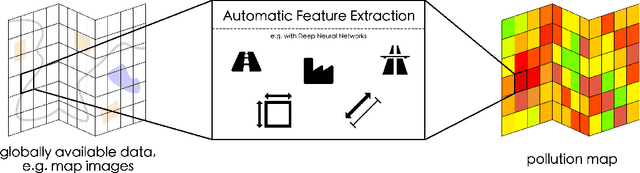
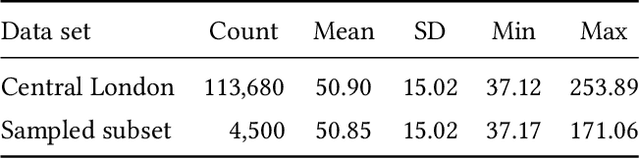
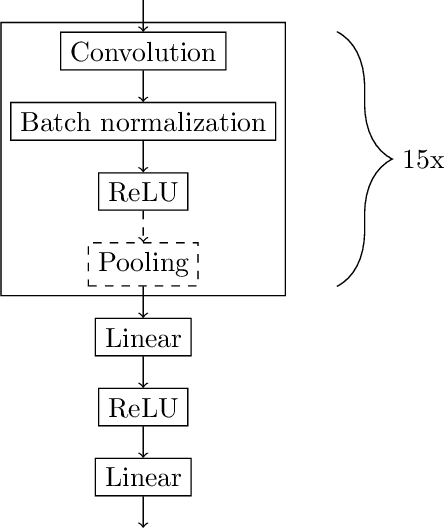

Land-use regression (LUR) models are important for the assessment of air pollution concentrations in areas without measurement stations. While many such models exist, they often use manually constructed features based on restricted, locally available data. Thus, they are typically hard to reproduce and challenging to adapt to areas beyond those they have been developed for. In this paper, we advocate a paradigm shift for LUR models: We propose the Data-driven, Open, Global (DOG) paradigm that entails models based on purely data-driven approaches using only openly and globally available data. Progress within this paradigm will alleviate the need for experts to adapt models to the local characteristics of the available data sources and thus facilitate the generalizability of air pollution models to new areas on a global scale. In order to illustrate the feasibility of the DOG paradigm for LUR, we introduce a deep learning model called MapLUR. It is based on a convolutional neural network architecture and is trained exclusively on globally and openly available map data without requiring manual feature engineering. We compare our model to state-of-the-art baselines like linear regression, random forests and multi-layer perceptrons using a large data set of modeled $\text{NO}_2$ concentrations in Central London. Our results show that MapLUR significantly outperforms these approaches even though they are provided with manually tailored features. Furthermore, we illustrate that the automatic feature extraction inherent to models based on the DOG paradigm can learn features that are readily interpretable and closely resemble those commonly used in traditional LUR approaches.