 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBibSonomy Meets ChatLLMs for Publication Management: From Chat to Publication Management: Organizing your related work using BibSonomy & LLMs
Jan 17, 2024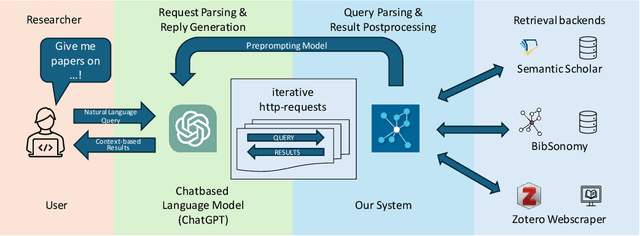



The ever-growing corpus of scientific literature presents significant challenges for researchers with respect to discovery, management, and annotation of relevant publications. Traditional platforms like Semantic Scholar, BibSonomy, and Zotero offer tools for literature management, but largely require manual laborious and error-prone input of tags and metadata. Here, we introduce a novel retrieval augmented generation system that leverages chat-based large language models (LLMs) to streamline and enhance the process of publication management. It provides a unified chat-based interface, enabling intuitive interactions with various backends, including Semantic Scholar, BibSonomy, and the Zotero Webscraper. It supports two main use-cases: (1) Explorative Search & Retrieval - leveraging LLMs to search for and retrieve both specific and general scientific publications, while addressing the challenges of content hallucination and data obsolescence; and (2) Cataloguing & Management - aiding in the organization of personal publication libraries, in this case BibSonomy, by automating the addition of metadata and tags, while facilitating manual edits and updates. We compare our system to different LLM models in three different settings, including a user study, and we can show its advantages in different metrics.
Higher-Order DeepTrails: Unified Approach to *Trails
Oct 06, 2023Analyzing, understanding, and describing human behavior is advantageous in different settings, such as web browsing or traffic navigation. Understanding human behavior naturally helps to improve and optimize the underlying infrastructure or user interfaces. Typically, human navigation is represented by sequences of transitions between states. Previous work suggests to use hypotheses, representing different intuitions about the navigation to analyze these transitions. To mathematically grasp this setting, first-order Markov chains are used to capture the behavior, consequently allowing to apply different kinds of graph comparisons, but comes with the inherent drawback of losing information about higher-order dependencies within the sequences. To this end, we propose to analyze entire sequences using autoregressive language models, as they are traditionally used to model higher-order dependencies in sequences. We show that our approach can be easily adapted to model different settings introduced in previous work, namely HypTrails, MixedTrails and even SubTrails, while at the same time bringing unique advantages: 1. Modeling higher-order dependencies between state transitions, while 2. being able to identify short comings in proposed hypotheses, and 3. naturally introducing a unified approach to model all settings. To show the expressiveness of our approach, we evaluate our approach on different synthetic datasets and conclude with an exemplary analysis of a real-world dataset, examining the behavior of users who interact with voice assistants.