 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDGS-LRM: Real-Time Deformable 3D Gaussian Reconstruction From Monocular Videos
Jun 11, 2025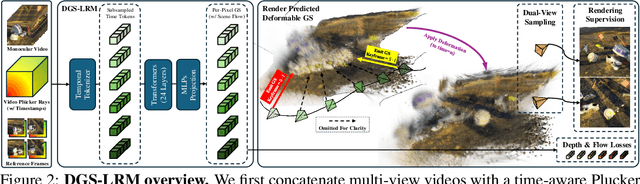
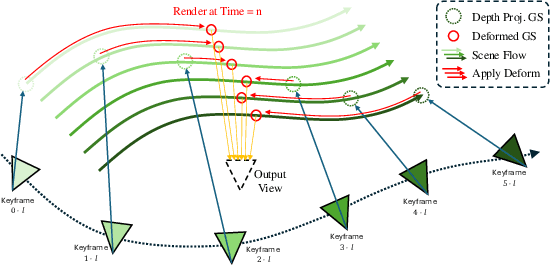
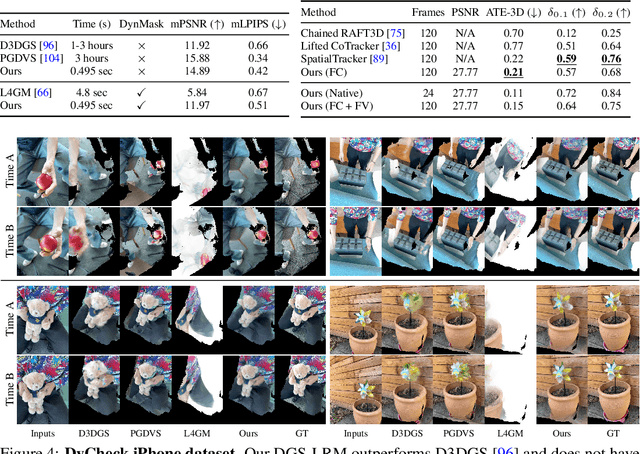

We introduce the Deformable Gaussian Splats Large Reconstruction Model (DGS-LRM), the first feed-forward method predicting deformable 3D Gaussian splats from a monocular posed video of any dynamic scene. Feed-forward scene reconstruction has gained significant attention for its ability to rapidly create digital replicas of real-world environments. However, most existing models are limited to static scenes and fail to reconstruct the motion of moving objects. Developing a feed-forward model for dynamic scene reconstruction poses significant challenges, including the scarcity of training data and the need for appropriate 3D representations and training paradigms. To address these challenges, we introduce several key technical contributions: an enhanced large-scale synthetic dataset with ground-truth multi-view videos and dense 3D scene flow supervision; a per-pixel deformable 3D Gaussian representation that is easy to learn, supports high-quality dynamic view synthesis, and enables long-range 3D tracking; and a large transformer network that achieves real-time, generalizable dynamic scene reconstruction. Extensive qualitative and quantitative experiments demonstrate that DGS-LRM achieves dynamic scene reconstruction quality comparable to optimization-based methods, while significantly outperforming the state-of-the-art predictive dynamic reconstruction method on real-world examples. Its predicted physically grounded 3D deformation is accurate and can readily adapt for long-range 3D tracking tasks, achieving performance on par with state-of-the-art monocular video 3D tracking methods.
Geometry-guided Online 3D Video Synthesis with Multi-View Temporal Consistency
May 25, 2025


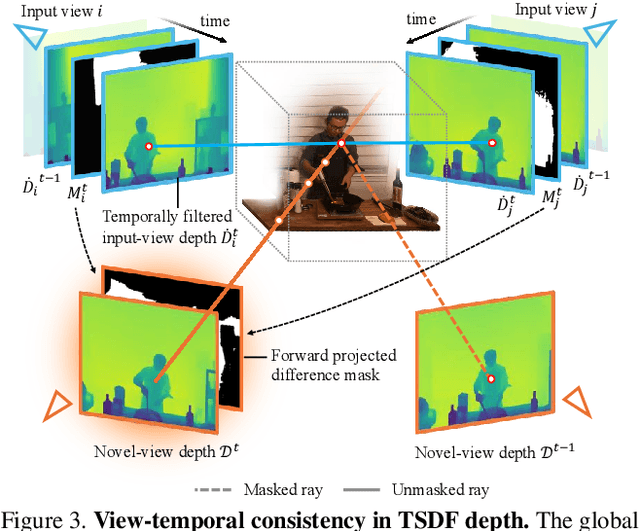
We introduce a novel geometry-guided online video view synthesis method with enhanced view and temporal consistency. Traditional approaches achieve high-quality synthesis from dense multi-view camera setups but require significant computational resources. In contrast, selective-input methods reduce this cost but often compromise quality, leading to multi-view and temporal inconsistencies such as flickering artifacts. Our method addresses this challenge to deliver efficient, high-quality novel-view synthesis with view and temporal consistency. The key innovation of our approach lies in using global geometry to guide an image-based rendering pipeline. To accomplish this, we progressively refine depth maps using color difference masks across time. These depth maps are then accumulated through truncated signed distance fields in the synthesized view's image space. This depth representation is view and temporally consistent, and is used to guide a pre-trained blending network that fuses multiple forward-rendered input-view images. Thus, the network is encouraged to output geometrically consistent synthesis results across multiple views and time. Our approach achieves consistent, high-quality video synthesis, while running efficiently in an online manner.
LIRM: Large Inverse Rendering Model for Progressive Reconstruction of Shape, Materials and View-dependent Radiance Fields
Apr 28, 2025We present Large Inverse Rendering Model (LIRM), a transformer architecture that jointly reconstructs high-quality shape, materials, and radiance fields with view-dependent effects in less than a second. Our model builds upon the recent Large Reconstruction Models (LRMs) that achieve state-of-the-art sparse-view reconstruction quality. However, existing LRMs struggle to reconstruct unseen parts accurately and cannot recover glossy appearance or generate relightable 3D contents that can be consumed by standard Graphics engines. To address these limitations, we make three key technical contributions to build a more practical multi-view 3D reconstruction framework. First, we introduce an update model that allows us to progressively add more input views to improve our reconstruction. Second, we propose a hexa-plane neural SDF representation to better recover detailed textures, geometry and material parameters. Third, we develop a novel neural directional-embedding mechanism to handle view-dependent effects. Trained on a large-scale shape and material dataset with a tailored coarse-to-fine training scheme, our model achieves compelling results. It compares favorably to optimization-based dense-view inverse rendering methods in terms of geometry and relighting accuracy, while requiring only a fraction of the inference time.
GenCA: A Text-conditioned Generative Model for Realistic and Drivable Codec Avatars
Aug 24, 2024

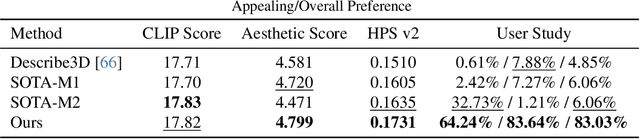
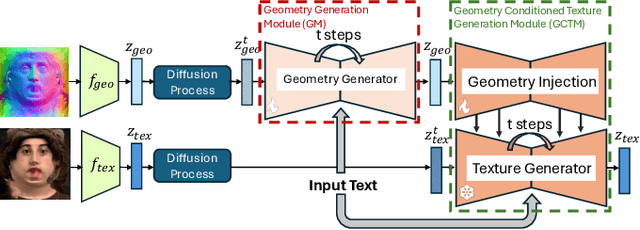
Photo-realistic and controllable 3D avatars are crucial for various applications such as virtual and mixed reality (VR/MR), telepresence, gaming, and film production. Traditional methods for avatar creation often involve time-consuming scanning and reconstruction processes for each avatar, which limits their scalability. Furthermore, these methods do not offer the flexibility to sample new identities or modify existing ones. On the other hand, by learning a strong prior from data, generative models provide a promising alternative to traditional reconstruction methods, easing the time constraints for both data capture and processing. Additionally, generative methods enable downstream applications beyond reconstruction, such as editing and stylization. Nonetheless, the research on generative 3D avatars is still in its infancy, and therefore current methods still have limitations such as creating static avatars, lacking photo-realism, having incomplete facial details, or having limited drivability. To address this, we propose a text-conditioned generative model that can generate photo-realistic facial avatars of diverse identities, with more complete details like hair, eyes and mouth interior, and which can be driven through a powerful non-parametric latent expression space. Specifically, we integrate the generative and editing capabilities of latent diffusion models with a strong prior model for avatar expression driving. Our model can generate and control high-fidelity avatars, even those out-of-distribution. We also highlight its potential for downstream applications, including avatar editing and single-shot avatar reconstruction.
NeRF Analogies: Example-Based Visual Attribute Transfer for NeRFs
Feb 13, 2024



A Neural Radiance Field (NeRF) encodes the specific relation of 3D geometry and appearance of a scene. We here ask the question whether we can transfer the appearance from a source NeRF onto a target 3D geometry in a semantically meaningful way, such that the resulting new NeRF retains the target geometry but has an appearance that is an analogy to the source NeRF. To this end, we generalize classic image analogies from 2D images to NeRFs. We leverage correspondence transfer along semantic affinity that is driven by semantic features from large, pre-trained 2D image models to achieve multi-view consistent appearance transfer. Our method allows exploring the mix-and-match product space of 3D geometry and appearance. We show that our method outperforms traditional stylization-based methods and that a large majority of users prefer our method over several typical baselines.
ReplaceAnything3D:Text-Guided 3D Scene Editing with Compositional Neural Radiance Fields
Jan 31, 2024We introduce ReplaceAnything3D model (RAM3D), a novel text-guided 3D scene editing method that enables the replacement of specific objects within a scene. Given multi-view images of a scene, a text prompt describing the object to replace, and a text prompt describing the new object, our Erase-and-Replace approach can effectively swap objects in the scene with newly generated content while maintaining 3D consistency across multiple viewpoints. We demonstrate the versatility of ReplaceAnything3D by applying it to various realistic 3D scenes, showcasing results of modified foreground objects that are well-integrated with the rest of the scene without affecting its overall integrity.
TextureDreamer: Image-guided Texture Synthesis through Geometry-aware Diffusion
Jan 17, 2024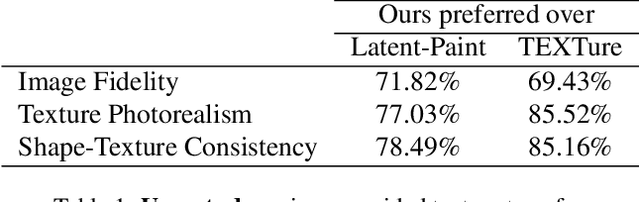


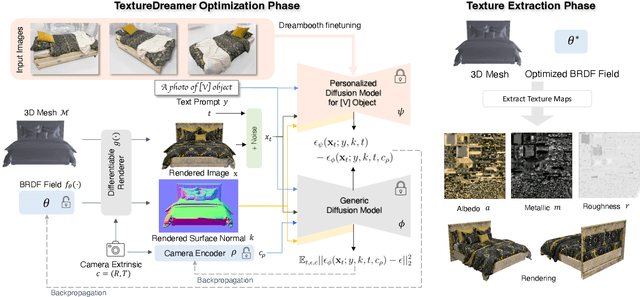
We present TextureDreamer, a novel image-guided texture synthesis method to transfer relightable textures from a small number of input images (3 to 5) to target 3D shapes across arbitrary categories. Texture creation is a pivotal challenge in vision and graphics. Industrial companies hire experienced artists to manually craft textures for 3D assets. Classical methods require densely sampled views and accurately aligned geometry, while learning-based methods are confined to category-specific shapes within the dataset. In contrast, TextureDreamer can transfer highly detailed, intricate textures from real-world environments to arbitrary objects with only a few casually captured images, potentially significantly democratizing texture creation. Our core idea, personalized geometry-aware score distillation (PGSD), draws inspiration from recent advancements in diffuse models, including personalized modeling for texture information extraction, variational score distillation for detailed appearance synthesis, and explicit geometry guidance with ControlNet. Our integration and several essential modifications substantially improve the texture quality. Experiments on real images spanning different categories show that TextureDreamer can successfully transfer highly realistic, semantic meaningful texture to arbitrary objects, surpassing the visual quality of previous state-of-the-art.
GauFRe: Gaussian Deformation Fields for Real-time Dynamic Novel View Synthesis
Dec 18, 2023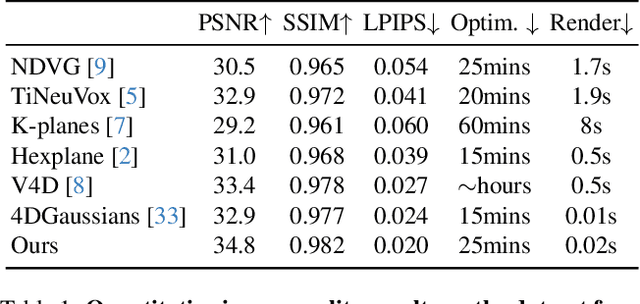
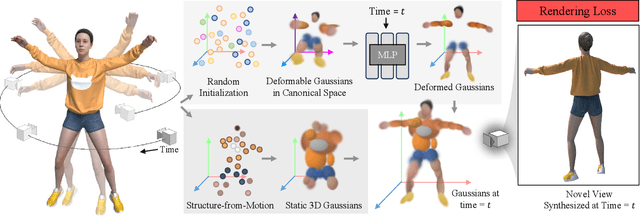
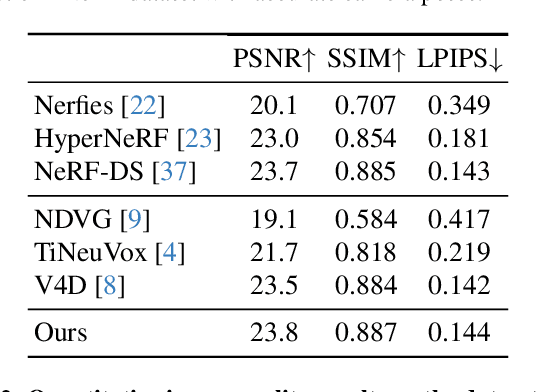
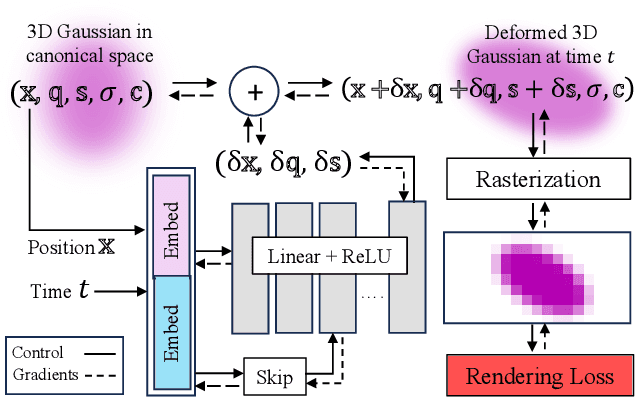
We propose a method for dynamic scene reconstruction using deformable 3D Gaussians that is tailored for monocular video. Building upon the efficiency of Gaussian splatting, our approach extends the representation to accommodate dynamic elements via a deformable set of Gaussians residing in a canonical space, and a time-dependent deformation field defined by a multi-layer perceptron (MLP). Moreover, under the assumption that most natural scenes have large regions that remain static, we allow the MLP to focus its representational power by additionally including a static Gaussian point cloud. The concatenated dynamic and static point clouds form the input for the Gaussian Splatting rasterizer, enabling real-time rendering. The differentiable pipeline is optimized end-to-end with a self-supervised rendering loss. Our method achieves results that are comparable to state-of-the-art dynamic neural radiance field methods while allowing much faster optimization and rendering. Project website: https://lynl7130.github.io/gaufre/index.html
AlteredAvatar: Stylizing Dynamic 3D Avatars with Fast Style Adaptation
May 30, 2023This paper presents a method that can quickly adapt dynamic 3D avatars to arbitrary text descriptions of novel styles. Among existing approaches for avatar stylization, direct optimization methods can produce excellent results for arbitrary styles but they are unpleasantly slow. Furthermore, they require redoing the optimization process from scratch for every new input. Fast approximation methods using feed-forward networks trained on a large dataset of style images can generate results for new inputs quickly, but tend not to generalize well to novel styles and fall short in quality. We therefore investigate a new approach, AlteredAvatar, that combines those two approaches using the meta-learning framework. In the inner loop, the model learns to optimize to match a single target style well; while in the outer loop, the model learns to stylize efficiently across many styles. After training, AlteredAvatar learns an initialization that can quickly adapt within a small number of update steps to a novel style, which can be given using texts, a reference image, or a combination of both. We show that AlteredAvatar can achieve a good balance between speed, flexibility and quality, while maintaining consistency across a wide range of novel views and facial expressions.
SNeRF: Stylized Neural Implicit Representations for 3D Scenes
Jul 05, 2022
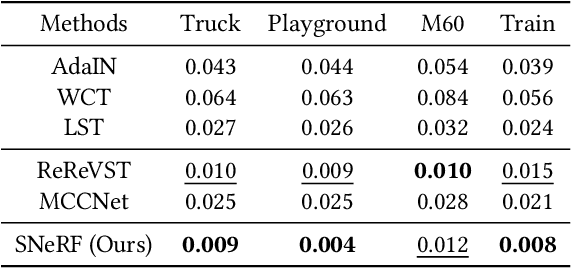
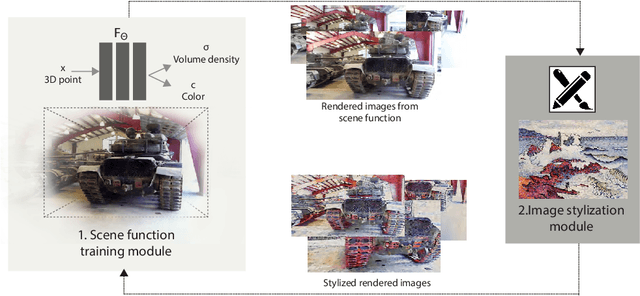

This paper presents a stylized novel view synthesis method. Applying state-of-the-art stylization methods to novel views frame by frame often causes jittering artifacts due to the lack of cross-view consistency. Therefore, this paper investigates 3D scene stylization that provides a strong inductive bias for consistent novel view synthesis. Specifically, we adopt the emerging neural radiance fields (NeRF) as our choice of 3D scene representation for their capability to render high-quality novel views for a variety of scenes. However, as rendering a novel view from a NeRF requires a large number of samples, training a stylized NeRF requires a large amount of GPU memory that goes beyond an off-the-shelf GPU capacity. We introduce a new training method to address this problem by alternating the NeRF and stylization optimization steps. Such a method enables us to make full use of our hardware memory capacity to both generate images at higher resolution and adopt more expressive image style transfer methods. Our experiments show that our method produces stylized NeRFs for a wide range of content, including indoor, outdoor and dynamic scenes, and synthesizes high-quality novel views with cross-view consistency.