 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenCA: A Text-conditioned Generative Model for Realistic and Drivable Codec Avatars
Aug 24, 2024

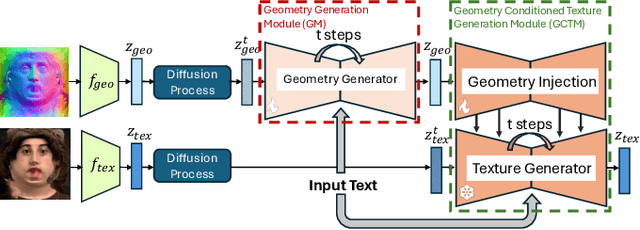
Photo-realistic and controllable 3D avatars are crucial for various applications such as virtual and mixed reality (VR/MR), telepresence, gaming, and film production. Traditional methods for avatar creation often involve time-consuming scanning and reconstruction processes for each avatar, which limits their scalability. Furthermore, these methods do not offer the flexibility to sample new identities or modify existing ones. On the other hand, by learning a strong prior from data, generative models provide a promising alternative to traditional reconstruction methods, easing the time constraints for both data capture and processing. Additionally, generative methods enable downstream applications beyond reconstruction, such as editing and stylization. Nonetheless, the research on generative 3D avatars is still in its infancy, and therefore current methods still have limitations such as creating static avatars, lacking photo-realism, having incomplete facial details, or having limited drivability. To address this, we propose a text-conditioned generative model that can generate photo-realistic facial avatars of diverse identities, with more complete details like hair, eyes and mouth interior, and which can be driven through a powerful non-parametric latent expression space. Specifically, we integrate the generative and editing capabilities of latent diffusion models with a strong prior model for avatar expression driving. Our model can generate and control high-fidelity avatars, even those out-of-distribution. We also highlight its potential for downstream applications, including avatar editing and single-shot avatar reconstruction.
Rethinking Video-Text Understanding: Retrieval from Counterfactually Augmented Data
Jul 18, 2024Recent video-text foundation models have demonstrated strong performance on a wide variety of downstream video understanding tasks. Can these video-text models genuinely understand the contents of natural videos? Standard video-text evaluations could be misleading as many questions can be inferred merely from the objects and contexts in a single frame or biases inherent in the datasets. In this paper, we aim to better assess the capabilities of current video-text models and understand their limitations. We propose a novel evaluation task for video-text understanding, namely retrieval from counterfactually augmented data (RCAD), and a new Feint6K dataset. To succeed on our new evaluation task, models must derive a comprehensive understanding of the video from cross-frame reasoning. Analyses show that previous video-text foundation models can be easily fooled by counterfactually augmented data and are far behind human-level performance. In order to narrow the gap between video-text models and human performance on RCAD, we identify a key limitation of current contrastive approaches on video-text data and introduce LLM-teacher, a more effective approach to learn action semantics by leveraging knowledge obtained from a pretrained large language model. Experiments and analyses show that our approach successfully learn more discriminative action embeddings and improves results on Feint6K when applied to multiple video-text models. Our Feint6K dataset and project page is available at https://feint6k.github.io.
RTMV: A Ray-Traced Multi-View Synthetic Dataset for Novel View Synthesis
May 14, 2022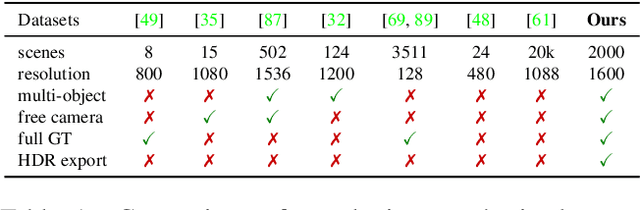


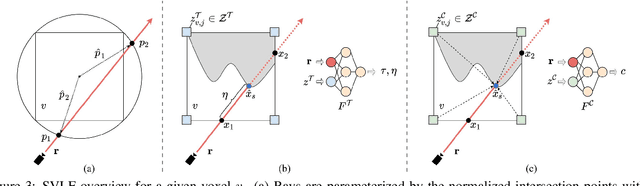
We present a large-scale synthetic dataset for novel view synthesis consisting of ~300k images rendered from nearly 2000 complex scenes using high-quality ray tracing at high resolution (1600 x 1600 pixels). The dataset is orders of magnitude larger than existing synthetic datasets for novel view synthesis, thus providing a large unified benchmark for both training and evaluation. Using 4 distinct sources of high-quality 3D meshes, the scenes of our dataset exhibit challenging variations in camera views, lighting, shape, materials, and textures. Because our dataset is too large for existing methods to process, we propose Sparse Voxel Light Field (SVLF), an efficient voxel-based light field approach for novel view synthesis that achieves comparable performance to NeRF on synthetic data, while being an order of magnitude faster to train and two orders of magnitude faster to render. SVLF achieves this speed by relying on a sparse voxel octree, careful voxel sampling (requiring only a handful of queries per ray), and reduced network structure; as well as ground truth depth maps at training time. Our dataset is generated by NViSII, a Python-based ray tracing renderer, which is designed to be simple for non-experts to use and share, flexible and powerful through its use of scripting, and able to create high-quality and physically-based rendered images. Experiments with a subset of our dataset allow us to compare standard methods like NeRF and mip-NeRF for single-scene modeling, and pixelNeRF for category-level modeling, pointing toward the need for future improvements in this area.
Learned Spatial Representations for Few-shot Talking-Head Synthesis
Apr 29, 2021
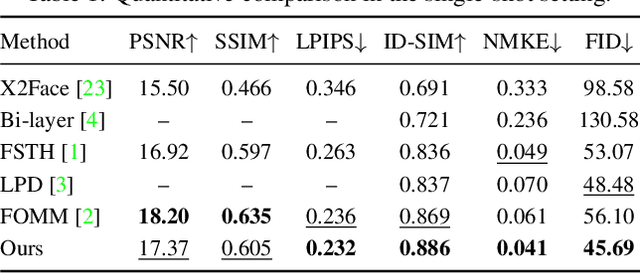
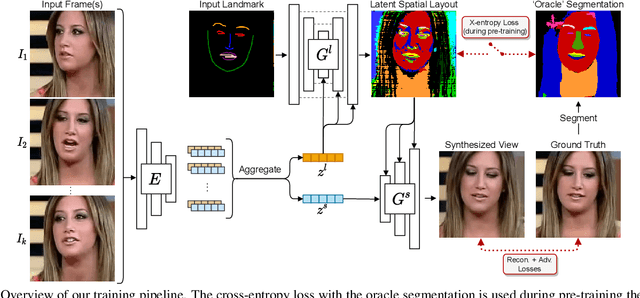
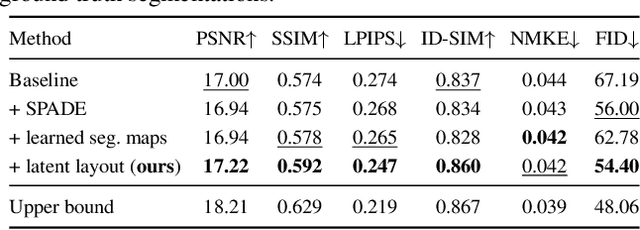
We propose a novel approach for few-shot talking-head synthesis. While recent works in neural talking heads have produced promising results, they can still produce images that do not preserve the identity of the subject in source images. We posit this is a result of the entangled representation of each subject in a single latent code that models 3D shape information, identity cues, colors, lighting and even background details. In contrast, we propose to factorize the representation of a subject into its spatial and style components. Our method generates a target frame in two steps. First, it predicts a dense spatial layout for the target image. Second, an image generator utilizes the predicted layout for spatial denormalization and synthesizes the target frame. We experimentally show that this disentangled representation leads to a significant improvement over previous methods, both quantitatively and qualitatively.
StEP: Style-based Encoder Pre-training for Multi-modal Image Synthesis
Apr 14, 2021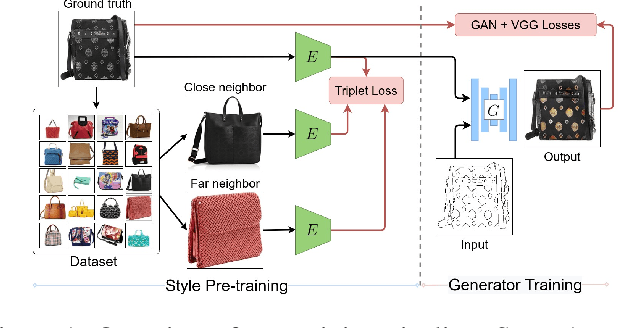
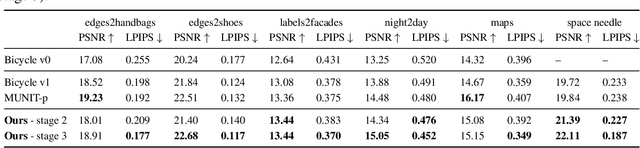

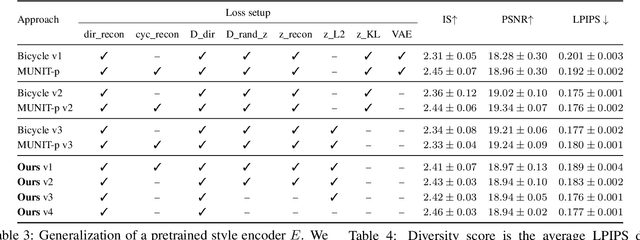
We propose a novel approach for multi-modal Image-to-image (I2I) translation. To tackle the one-to-many relationship between input and output domains, previous works use complex training objectives to learn a latent embedding, jointly with the generator, that models the variability of the output domain. In contrast, we directly model the style variability of images, independent of the image synthesis task. Specifically, we pre-train a generic style encoder using a novel proxy task to learn an embedding of images, from arbitrary domains, into a low-dimensional style latent space. The learned latent space introduces several advantages over previous traditional approaches to multi-modal I2I translation. First, it is not dependent on the target dataset, and generalizes well across multiple domains. Second, it learns a more powerful and expressive latent space, which improves the fidelity of style capture and transfer. The proposed style pre-training also simplifies the training objective and speeds up the training significantly. Furthermore, we provide a detailed study of the contribution of different loss terms to the task of multi-modal I2I translation, and propose a simple alternative to VAEs to enable sampling from unconstrained latent spaces. Finally, we achieve state-of-the-art results on six challenging benchmarks with a simple training objective that includes only a GAN loss and a reconstruction loss.
Neural Rerendering in the Wild
Apr 08, 2019
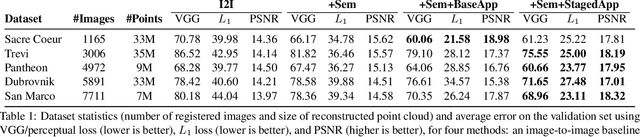

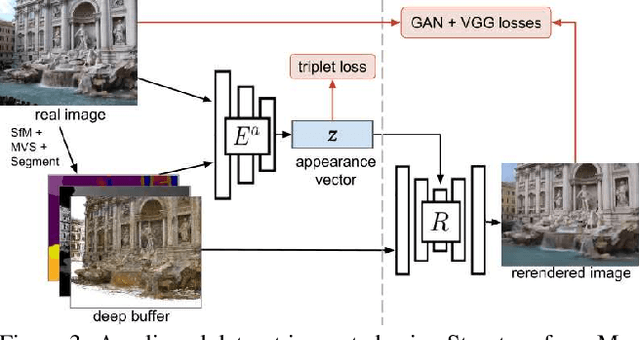
We explore total scene capture -- recording, modeling, and rerendering a scene under varying appearance such as season and time of day. Starting from internet photos of a tourist landmark, we apply traditional 3D reconstruction to register the photos and approximate the scene as a point cloud. For each photo, we render the scene points into a deep framebuffer, and train a neural network to learn the mapping of these initial renderings to the actual photos. This rerendering network also takes as input a latent appearance vector and a semantic mask indicating the location of transient objects like pedestrians. The model is evaluated on several datasets of publicly available images spanning a broad range of illumination conditions. We create short videos demonstrating realistic manipulation of the image viewpoint, appearance, and semantic labeling. We also compare results with prior work on scene reconstruction from internet photos.
Two Stream Self-Supervised Learning for Action Recognition
Jun 16, 2018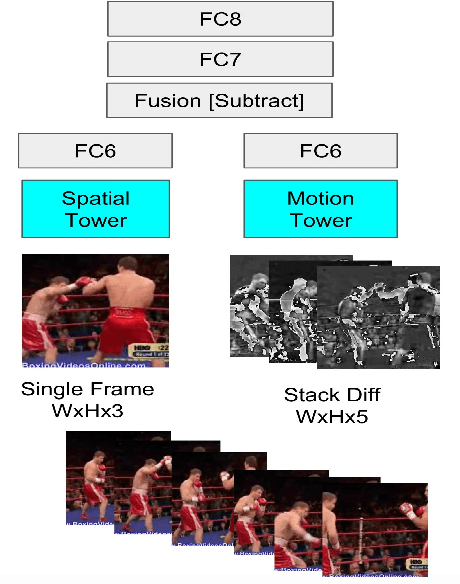
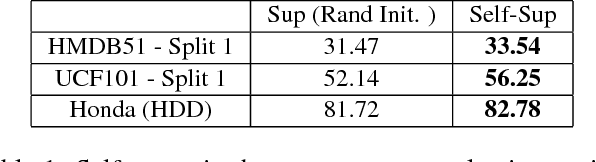

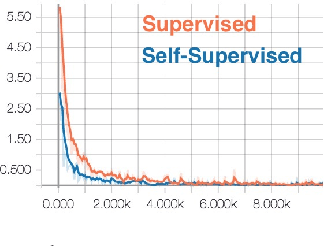
We present a self-supervised approach using spatio-temporal signals between video frames for action recognition. A two-stream architecture is leveraged to tangle spatial and temporal representation learning. Our task is formulated as both a sequence verification and spatio-temporal alignment tasks. The former task requires motion temporal structure understanding while the latter couples the learned motion with the spatial representation. The self-supervised pre-trained weights effectiveness is validated on the action recognition task. Quantitative evaluation shows the self-supervised approach competence on three datasets: HMDB51, UCF101, and Honda driving dataset (HDD). Further investigations to boost performance and generalize validity are still required.
Texture Synthesis with Recurrent Variational Auto-Encoder
Dec 23, 2017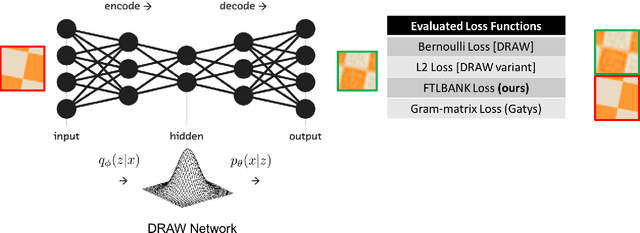


We propose a recurrent variational auto-encoder for texture synthesis. A novel loss function, FLTBNK, is used for training the texture synthesizer. It is rotational and partially color invariant loss function. Unlike L2 loss, FLTBNK explicitly models the correlation of color intensity between pixels. Our texture synthesizer generates neighboring tiles to expand a sample texture and is evaluated using various texture patterns from Describable Textures Dataset (DTD). We perform both quantitative and qualitative experiments with various loss functions to evaluate the performance of our proposed loss function (FLTBNK) --- a mini-human subject study is used for the qualitative evaluation.
Linear-time Online Action Detection From 3D Skeletal Data Using Bags of Gesturelets
Dec 28, 2015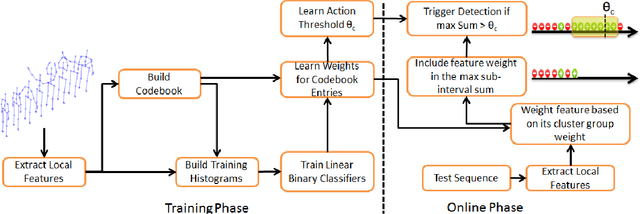
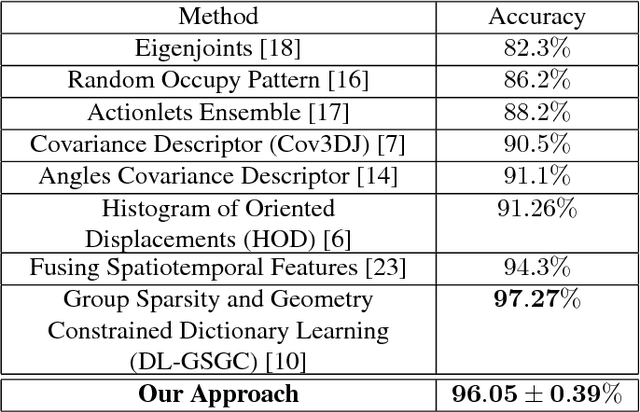
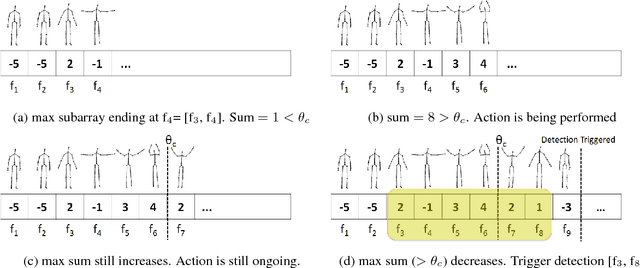

Sliding window is one direct way to extend a successful recognition system to handle the more challenging detection problem. While action recognition decides only whether or not an action is present in a pre-segmented video sequence, action detection identifies the time interval where the action occurred in an unsegmented video stream. Sliding window approaches for action detection can however be slow as they maximize a classifier score over all possible sub-intervals. Even though new schemes utilize dynamic programming to speed up the search for the optimal sub-interval, they require offline processing on the whole video sequence. In this paper, we propose a novel approach for online action detection based on 3D skeleton sequences extracted from depth data. It identifies the sub-interval with the maximum classifier score in linear time. Furthermore, it is invariant to temporal scale variations and is suitable for real-time applications with low latency.