 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStEP: Style-based Encoder Pre-training for Multi-modal Image Synthesis
Apr 14, 2021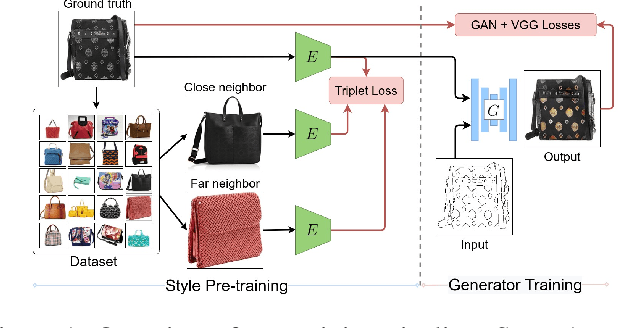
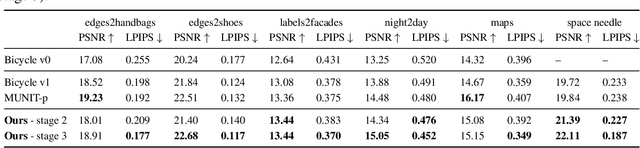

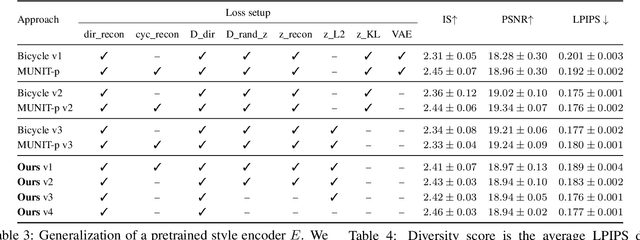
We propose a novel approach for multi-modal Image-to-image (I2I) translation. To tackle the one-to-many relationship between input and output domains, previous works use complex training objectives to learn a latent embedding, jointly with the generator, that models the variability of the output domain. In contrast, we directly model the style variability of images, independent of the image synthesis task. Specifically, we pre-train a generic style encoder using a novel proxy task to learn an embedding of images, from arbitrary domains, into a low-dimensional style latent space. The learned latent space introduces several advantages over previous traditional approaches to multi-modal I2I translation. First, it is not dependent on the target dataset, and generalizes well across multiple domains. Second, it learns a more powerful and expressive latent space, which improves the fidelity of style capture and transfer. The proposed style pre-training also simplifies the training objective and speeds up the training significantly. Furthermore, we provide a detailed study of the contribution of different loss terms to the task of multi-modal I2I translation, and propose a simple alternative to VAEs to enable sampling from unconstrained latent spaces. Finally, we achieve state-of-the-art results on six challenging benchmarks with a simple training objective that includes only a GAN loss and a reconstruction loss.
Stacked U-Nets: A No-Frills Approach to Natural Image Segmentation
Apr 27, 2018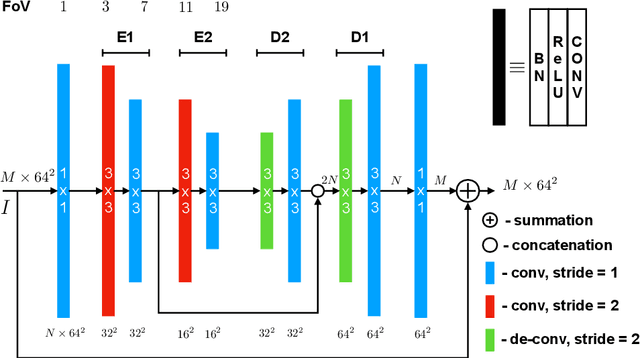
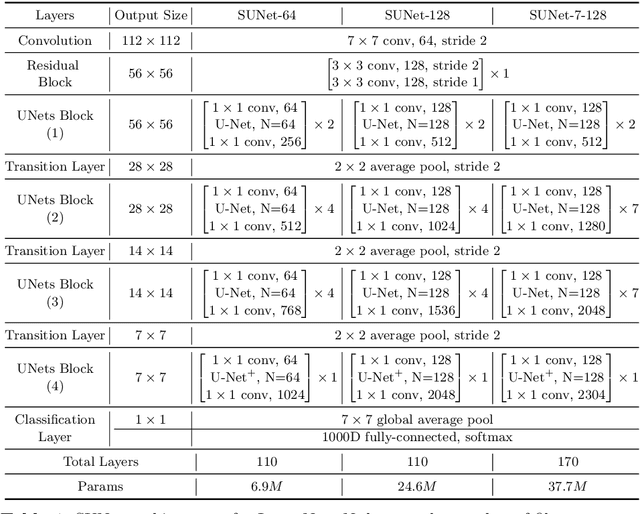
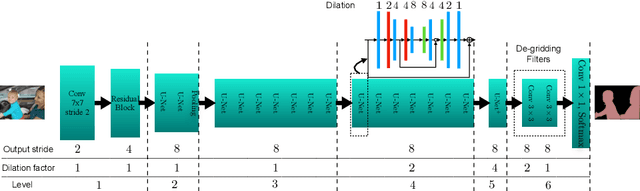
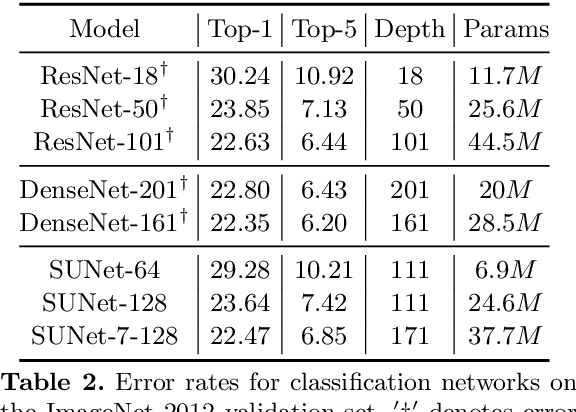
Many imaging tasks require global information about all pixels in an image. Conventional bottom-up classification networks globalize information by decreasing resolution; features are pooled and downsampled into a single output. But for semantic segmentation and object detection tasks, a network must provide higher-resolution pixel-level outputs. To globalize information while preserving resolution, many researchers propose the inclusion of sophisticated auxiliary blocks, but these come at the cost of a considerable increase in network size and computational cost. This paper proposes stacked u-nets (SUNets), which iteratively combine features from different resolution scales while maintaining resolution. SUNets leverage the information globalization power of u-nets in a deeper network architectures that is capable of handling the complexity of natural images. SUNets perform extremely well on semantic segmentation tasks using a small number of parameters.