 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStacked U-Nets: A No-Frills Approach to Natural Image Segmentation
Paper and Code
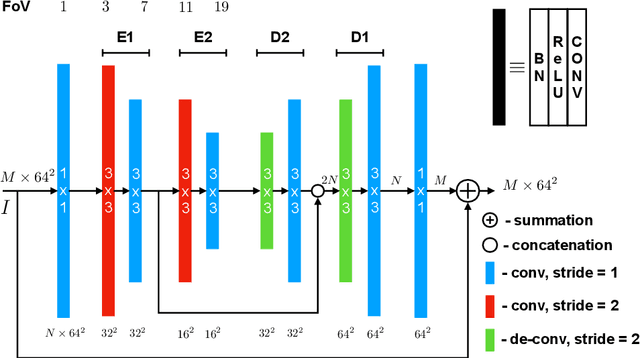
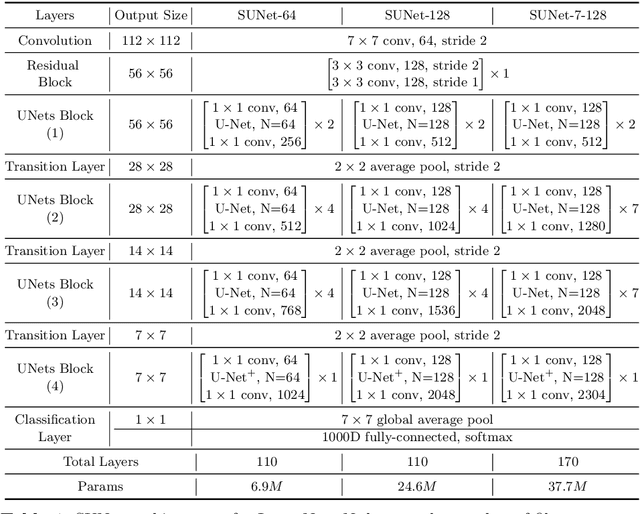
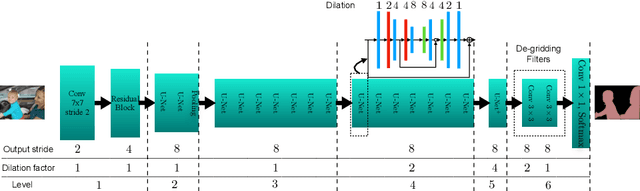
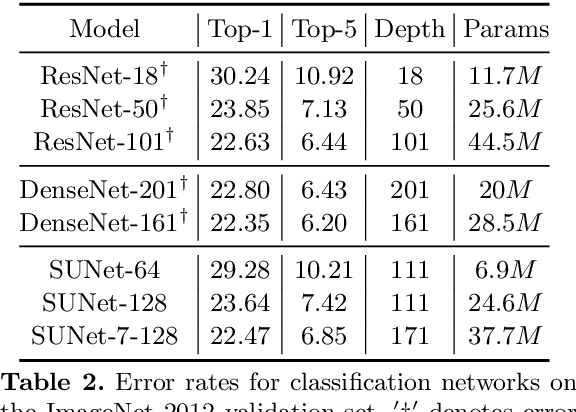
Many imaging tasks require global information about all pixels in an image. Conventional bottom-up classification networks globalize information by decreasing resolution; features are pooled and downsampled into a single output. But for semantic segmentation and object detection tasks, a network must provide higher-resolution pixel-level outputs. To globalize information while preserving resolution, many researchers propose the inclusion of sophisticated auxiliary blocks, but these come at the cost of a considerable increase in network size and computational cost. This paper proposes stacked u-nets (SUNets), which iteratively combine features from different resolution scales while maintaining resolution. SUNets leverage the information globalization power of u-nets in a deeper network architectures that is capable of handling the complexity of natural images. SUNets perform extremely well on semantic segmentation tasks using a small number of parameters.