 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA LoRA is Worth a Thousand Pictures
Dec 16, 2024Recent advances in diffusion models and parameter-efficient fine-tuning (PEFT) have made text-to-image generation and customization widely accessible, with Low Rank Adaptation (LoRA) able to replicate an artist's style or subject using minimal data and computation. In this paper, we examine the relationship between LoRA weights and artistic styles, demonstrating that LoRA weights alone can serve as an effective descriptor of style, without the need for additional image generation or knowledge of the original training set. Our findings show that LoRA weights yield better performance in clustering of artistic styles compared to traditional pre-trained features, such as CLIP and DINO, with strong structural similarities between LoRA-based and conventional image-based embeddings observed both qualitatively and quantitatively. We identify various retrieval scenarios for the growing collection of customized models and show that our approach enables more accurate retrieval in real-world settings where knowledge of the training images is unavailable and additional generation is required. We conclude with a discussion on potential future applications, such as zero-shot LoRA fine-tuning and model attribution.
Lagrangian Hashing for Compressed Neural Field Representations
Sep 09, 2024



We present Lagrangian Hashing, a representation for neural fields combining the characteristics of fast training NeRF methods that rely on Eulerian grids (i.e.~InstantNGP), with those that employ points equipped with features as a way to represent information (e.g. 3D Gaussian Splatting or PointNeRF). We achieve this by incorporating a point-based representation into the high-resolution layers of the hierarchical hash tables of an InstantNGP representation. As our points are equipped with a field of influence, our representation can be interpreted as a mixture of Gaussians stored within the hash table. We propose a loss that encourages the movement of our Gaussians towards regions that require more representation budget to be sufficiently well represented. Our main finding is that our representation allows the reconstruction of signals using a more compact representation without compromising quality.
Learned Single-Pass Multitasking Perceptual Graphics for Immersive Displays
Jul 31, 2024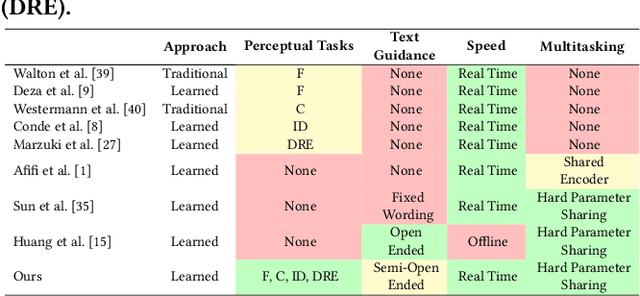
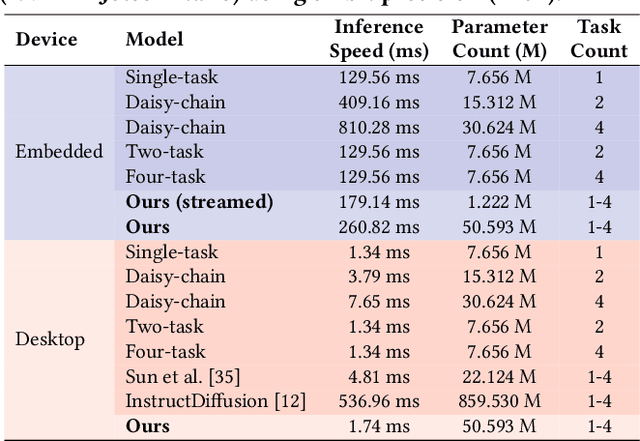
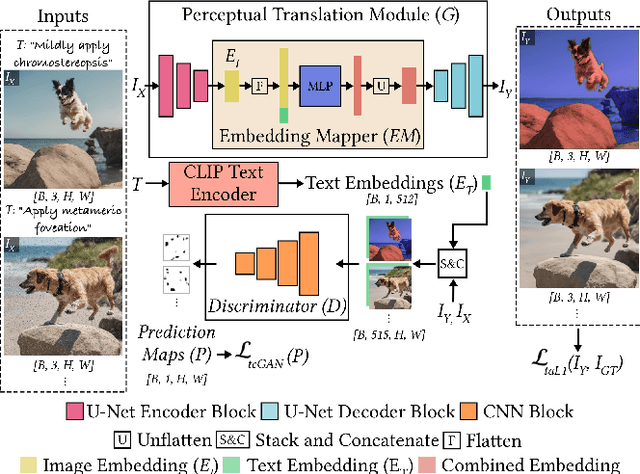
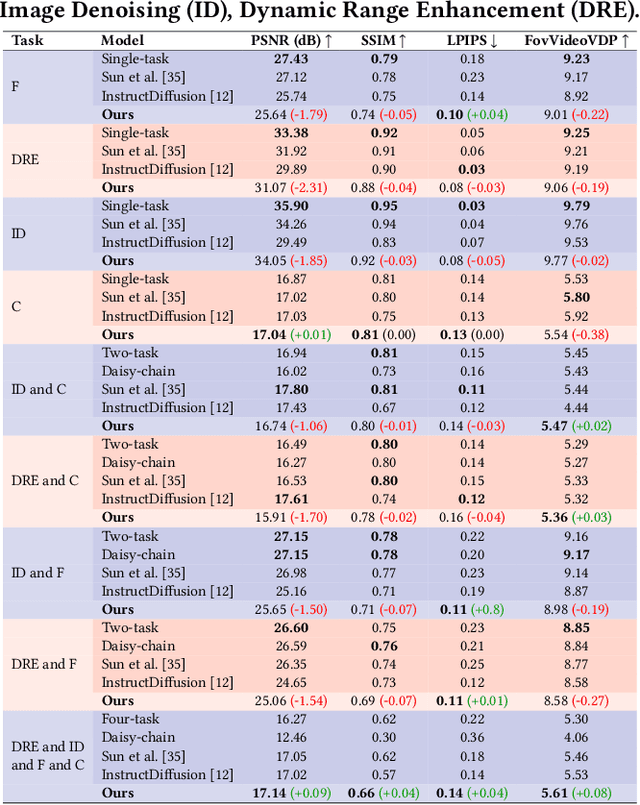
Immersive displays are advancing rapidly in terms of delivering perceptually realistic images by utilizing emerging perceptual graphics methods such as foveated rendering. In practice, multiple such methods need to be performed sequentially for enhanced perceived quality. However, the limited power and computational resources of the devices that drive immersive displays make it challenging to deploy multiple perceptual models simultaneously. We address this challenge by proposing a computationally-lightweight, text-guided, learned multitasking perceptual graphics model. Given RGB input images, our model outputs perceptually enhanced images by performing one or more perceptual tasks described by the provided text prompts. Our model supports a variety of perceptual tasks, including foveated rendering, dynamic range enhancement, image denoising, and chromostereopsis, through multitask learning. Uniquely, a single inference step of our model supports different permutations of these perceptual tasks at different prompted rates (i.e., mildly, lightly), eliminating the need for daisy-chaining multiple models to get the desired perceptual effect. We train our model on our new dataset of source and perceptually enhanced images, and their corresponding text prompts. We evaluate our model's performance on embedded platforms and validate the perceptual quality of our model through a user study. Our method achieves on-par quality with the state-of-the-art task-specific methods using a single inference step, while offering faster inference speeds and flexibility to blend effects at various intensities.
What You See is What You GAN: Rendering Every Pixel for High-Fidelity Geometry in 3D GANs
Jan 04, 2024



3D-aware Generative Adversarial Networks (GANs) have shown remarkable progress in learning to generate multi-view-consistent images and 3D geometries of scenes from collections of 2D images via neural volume rendering. Yet, the significant memory and computational costs of dense sampling in volume rendering have forced 3D GANs to adopt patch-based training or employ low-resolution rendering with post-processing 2D super resolution, which sacrifices multiview consistency and the quality of resolved geometry. Consequently, 3D GANs have not yet been able to fully resolve the rich 3D geometry present in 2D images. In this work, we propose techniques to scale neural volume rendering to the much higher resolution of native 2D images, thereby resolving fine-grained 3D geometry with unprecedented detail. Our approach employs learning-based samplers for accelerating neural rendering for 3D GAN training using up to 5 times fewer depth samples. This enables us to explicitly "render every pixel" of the full-resolution image during training and inference without post-processing superresolution in 2D. Together with our strategy to learn high-quality surface geometry, our method synthesizes high-resolution 3D geometry and strictly view-consistent images while maintaining image quality on par with baselines relying on post-processing super resolution. We demonstrate state-of-the-art 3D gemetric quality on FFHQ and AFHQ, setting a new standard for unsupervised learning of 3D shapes in 3D GANs.
Compact Neural Graphics Primitives with Learned Hash Probing
Dec 28, 2023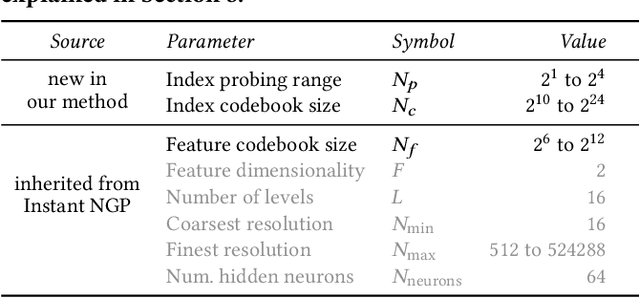



Neural graphics primitives are faster and achieve higher quality when their neural networks are augmented by spatial data structures that hold trainable features arranged in a grid. However, existing feature grids either come with a large memory footprint (dense or factorized grids, trees, and hash tables) or slow performance (index learning and vector quantization). In this paper, we show that a hash table with learned probes has neither disadvantage, resulting in a favorable combination of size and speed. Inference is faster than unprobed hash tables at equal quality while training is only 1.2-2.6x slower, significantly outperforming prior index learning approaches. We arrive at this formulation by casting all feature grids into a common framework: they each correspond to a lookup function that indexes into a table of feature vectors. In this framework, the lookup functions of existing data structures can be combined by simple arithmetic combinations of their indices, resulting in Pareto optimal compression and speed.
ATT3D: Amortized Text-to-3D Object Synthesis
Jun 06, 2023



Text-to-3D modelling has seen exciting progress by combining generative text-to-image models with image-to-3D methods like Neural Radiance Fields. DreamFusion recently achieved high-quality results but requires a lengthy, per-prompt optimization to create 3D objects. To address this, we amortize optimization over text prompts by training on many prompts simultaneously with a unified model, instead of separately. With this, we share computation across a prompt set, training in less time than per-prompt optimization. Our framework - Amortized text-to-3D (ATT3D) - enables knowledge-sharing between prompts to generalize to unseen setups and smooth interpolations between text for novel assets and simple animations.
Magic3D: High-Resolution Text-to-3D Content Creation
Nov 18, 2022



DreamFusion has recently demonstrated the utility of a pre-trained text-to-image diffusion model to optimize Neural Radiance Fields (NeRF), achieving remarkable text-to-3D synthesis results. However, the method has two inherent limitations: (a) extremely slow optimization of NeRF and (b) low-resolution image space supervision on NeRF, leading to low-quality 3D models with a long processing time. In this paper, we address these limitations by utilizing a two-stage optimization framework. First, we obtain a coarse model using a low-resolution diffusion prior and accelerate with a sparse 3D hash grid structure. Using the coarse representation as the initialization, we further optimize a textured 3D mesh model with an efficient differentiable renderer interacting with a high-resolution latent diffusion model. Our method, dubbed Magic3D, can create high quality 3D mesh models in 40 minutes, which is 2x faster than DreamFusion (reportedly taking 1.5 hours on average), while also achieving higher resolution. User studies show 61.7% raters to prefer our approach over DreamFusion. Together with the image-conditioned generation capabilities, we provide users with new ways to control 3D synthesis, opening up new avenues to various creative applications.
Variable Bitrate Neural Fields
Jun 15, 2022
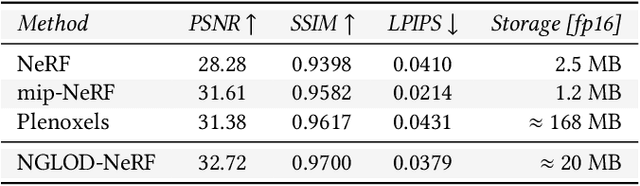

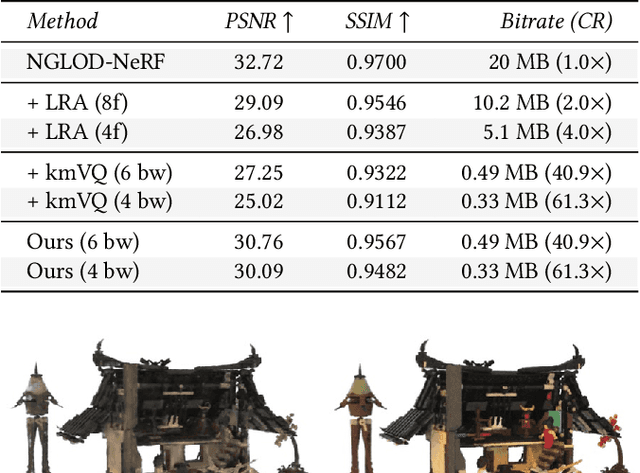
Neural approximations of scalar and vector fields, such as signed distance functions and radiance fields, have emerged as accurate, high-quality representations. State-of-the-art results are obtained by conditioning a neural approximation with a lookup from trainable feature grids that take on part of the learning task and allow for smaller, more efficient neural networks. Unfortunately, these feature grids usually come at the cost of significantly increased memory consumption compared to stand-alone neural network models. We present a dictionary method for compressing such feature grids, reducing their memory consumption by up to 100x and permitting a multiresolution representation which can be useful for out-of-core streaming. We formulate the dictionary optimization as a vector-quantized auto-decoder problem which lets us learn end-to-end discrete neural representations in a space where no direct supervision is available and with dynamic topology and structure. Our source code will be available at https://github.com/nv-tlabs/vqad.
RTMV: A Ray-Traced Multi-View Synthetic Dataset for Novel View Synthesis
May 14, 2022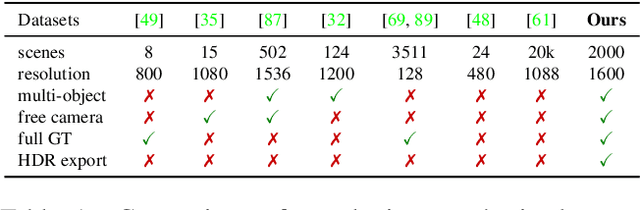


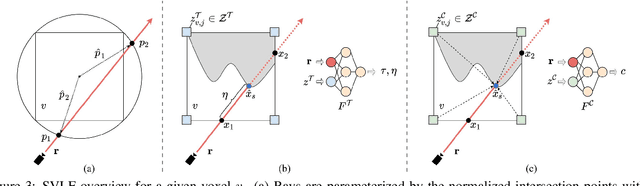
We present a large-scale synthetic dataset for novel view synthesis consisting of ~300k images rendered from nearly 2000 complex scenes using high-quality ray tracing at high resolution (1600 x 1600 pixels). The dataset is orders of magnitude larger than existing synthetic datasets for novel view synthesis, thus providing a large unified benchmark for both training and evaluation. Using 4 distinct sources of high-quality 3D meshes, the scenes of our dataset exhibit challenging variations in camera views, lighting, shape, materials, and textures. Because our dataset is too large for existing methods to process, we propose Sparse Voxel Light Field (SVLF), an efficient voxel-based light field approach for novel view synthesis that achieves comparable performance to NeRF on synthetic data, while being an order of magnitude faster to train and two orders of magnitude faster to render. SVLF achieves this speed by relying on a sparse voxel octree, careful voxel sampling (requiring only a handful of queries per ray), and reduced network structure; as well as ground truth depth maps at training time. Our dataset is generated by NViSII, a Python-based ray tracing renderer, which is designed to be simple for non-experts to use and share, flexible and powerful through its use of scripting, and able to create high-quality and physically-based rendered images. Experiments with a subset of our dataset allow us to compare standard methods like NeRF and mip-NeRF for single-scene modeling, and pixelNeRF for category-level modeling, pointing toward the need for future improvements in this area.
Neural Fields in Visual Computing and Beyond
Nov 29, 2021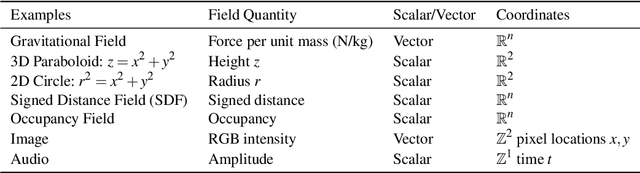
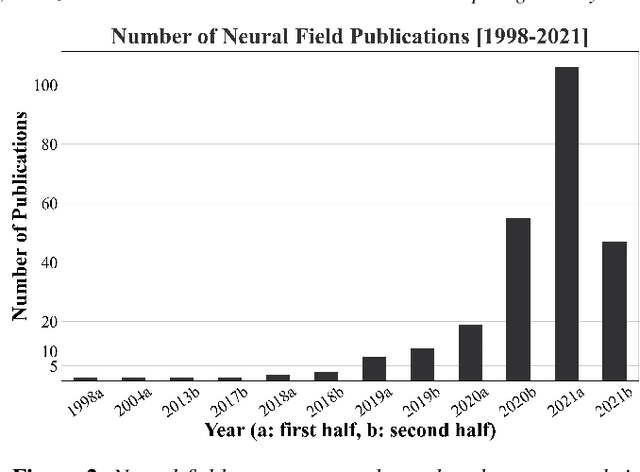

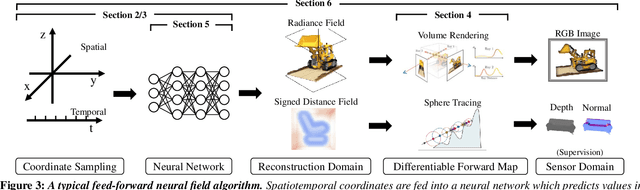
Recent advances in machine learning have created increasing interest in solving visual computing problems using a class of coordinate-based neural networks that parametrize physical properties of scenes or objects across space and time. These methods, which we call neural fields, have seen successful application in the synthesis of 3D shapes and image, animation of human bodies, 3D reconstruction, and pose estimation. However, due to rapid progress in a short time, many papers exist but a comprehensive review and formulation of the problem has not yet emerged. In this report, we address this limitation by providing context, mathematical grounding, and an extensive review of literature on neural fields. This report covers research along two dimensions. In Part I, we focus on techniques in neural fields by identifying common components of neural field methods, including different representations, architectures, forward mapping, and generalization methods. In Part II, we focus on applications of neural fields to different problems in visual computing, and beyond (e.g., robotics, audio). Our review shows the breadth of topics already covered in visual computing, both historically and in current incarnations, demonstrating the improved quality, flexibility, and capability brought by neural fields methods. Finally, we present a companion website that contributes a living version of this review that can be continually updated by the community.