 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearned Single-Pass Multitasking Perceptual Graphics for Immersive Displays
Paper and Code
Jul 31, 2024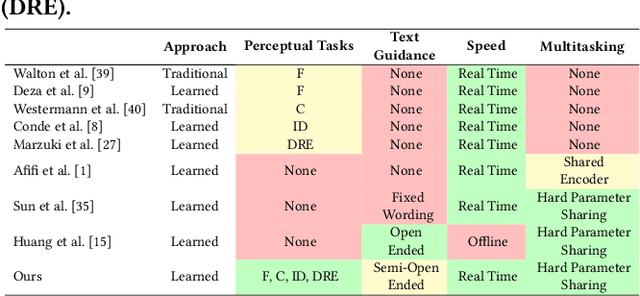
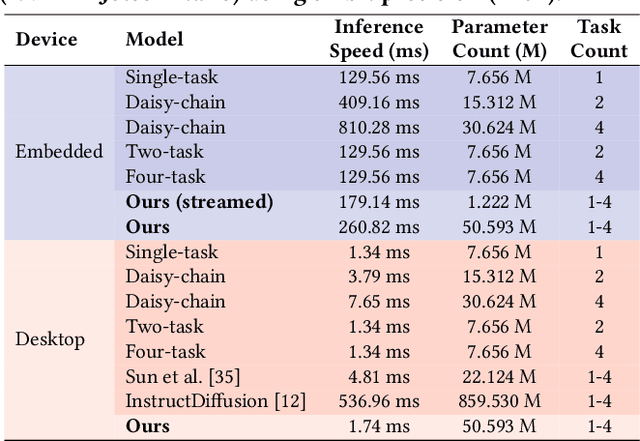
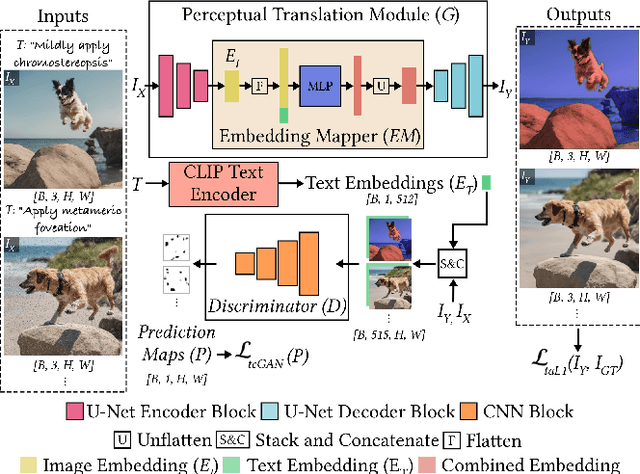
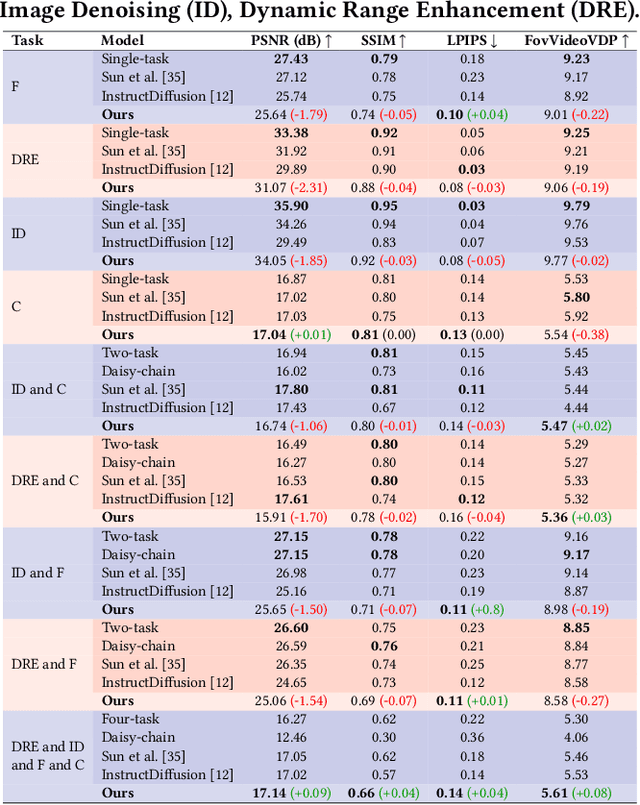
Immersive displays are advancing rapidly in terms of delivering perceptually realistic images by utilizing emerging perceptual graphics methods such as foveated rendering. In practice, multiple such methods need to be performed sequentially for enhanced perceived quality. However, the limited power and computational resources of the devices that drive immersive displays make it challenging to deploy multiple perceptual models simultaneously. We address this challenge by proposing a computationally-lightweight, text-guided, learned multitasking perceptual graphics model. Given RGB input images, our model outputs perceptually enhanced images by performing one or more perceptual tasks described by the provided text prompts. Our model supports a variety of perceptual tasks, including foveated rendering, dynamic range enhancement, image denoising, and chromostereopsis, through multitask learning. Uniquely, a single inference step of our model supports different permutations of these perceptual tasks at different prompted rates (i.e., mildly, lightly), eliminating the need for daisy-chaining multiple models to get the desired perceptual effect. We train our model on our new dataset of source and perceptually enhanced images, and their corresponding text prompts. We evaluate our model's performance on embedded platforms and validate the perceptual quality of our model through a user study. Our method achieves on-par quality with the state-of-the-art task-specific methods using a single inference step, while offering faster inference speeds and flexibility to blend effects at various intensities.