 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplex-Valued 2D Gaussian Representation for Computer-Generated Holography
Nov 19, 2025
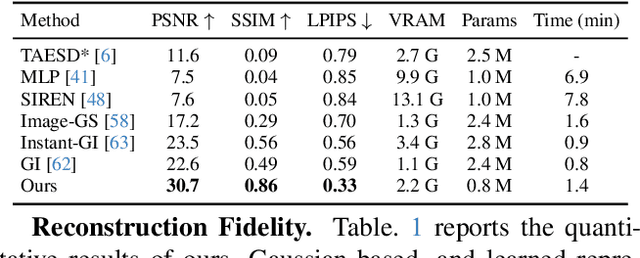

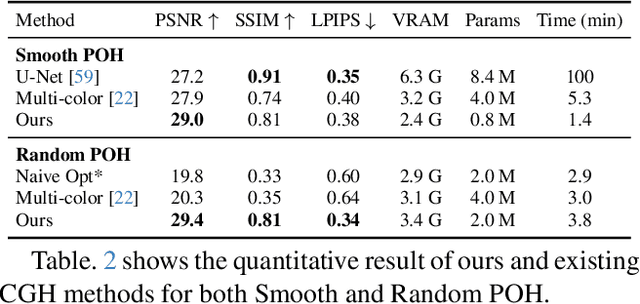
We propose a new hologram representation based on structured complex-valued 2D Gaussian primitives, which replaces per-pixel information storage and reduces the parameter search space by up to 10:1. To enable end-to-end training, we develop a differentiable rasterizer for our representation, integrated with a GPU-optimized light propagation kernel in free space. Our extensive experiments show that our method achieves up to 2.5x lower VRAM usage and 50% faster optimization while producing higher-fidelity reconstructions than existing methods. We further introduce a conversion procedure that adapts our representation to practical hologram formats, including smooth and random phase-only holograms. Our experiments show that this procedure can effectively suppress noise artifacts observed in previous methods. By reducing the hologram parameter search space, our representation enables a more scalable hologram estimation in the next-generation computer-generated holography systems.
Efficient Proxy Raytracer for Optical Systems using Implicit Neural Representations
Jul 28, 2025Ray tracing is a widely used technique for modeling optical systems, involving sequential surface-by-surface computations, which can be computationally intensive. We propose Ray2Ray, a novel method that leverages implicit neural representations to model optical systems with greater efficiency, eliminating the need for surface-by-surface computations in a single pass end-to-end model. Ray2Ray learns the mapping between rays emitted from a given source and their corresponding rays after passing through a given optical system in a physically accurate manner. We train Ray2Ray on nine off-the-shelf optical systems, achieving positional errors on the order of 1{\mu}m and angular deviations on the order 0.01 degrees in the estimated output rays. Our work highlights the potential of neural representations as a proxy for optical raytracer.
Complex-Valued Holographic Radiance Fields
Jun 10, 2025Modeling the full properties of light, including both amplitude and phase, in 3D representations is crucial for advancing physically plausible rendering, particularly in holographic displays. To support these features, we propose a novel representation that optimizes 3D scenes without relying on intensity-based intermediaries. We reformulate 3D Gaussian splatting with complex-valued Gaussian primitives, expanding support for rendering with light waves. By leveraging RGBD multi-view images, our method directly optimizes complex-valued Gaussians as a 3D holographic scene representation. This eliminates the need for computationally expensive hologram re-optimization. Compared with state-of-the-art methods, our method achieves 30x-10,000x speed improvements while maintaining on-par image quality, representing a first step towards geometrically aligned, physically plausible holographic scene representations.
SpecTrack: Learned Multi-Rotation Tracking via Speckle Imaging
Oct 08, 2024
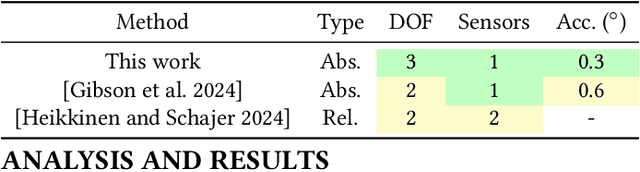
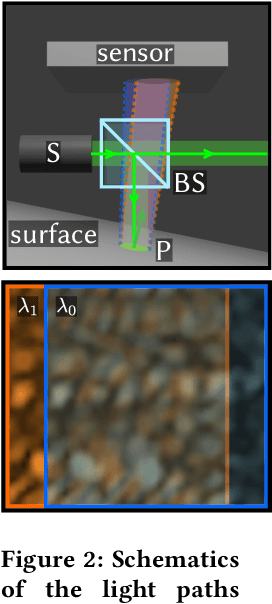
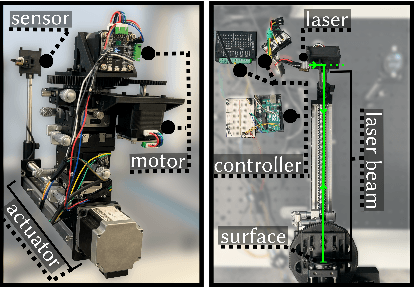
Precision pose detection is increasingly demanded in fields such as personal fabrication, Virtual Reality (VR), and robotics due to its critical role in ensuring accurate positioning information. However, conventional vision-based systems used in these systems often struggle with achieving high precision and accuracy, particularly when dealing with complex environments or fast-moving objects. To address these limitations, we investigate Laser Speckle Imaging (LSI), an emerging optical tracking method that offers promising potential for improving pose estimation accuracy. Specifically, our proposed LSI-Based Tracking (SpecTrack) leverages the captures from a lensless camera and a retro-reflector marker with a coded aperture to achieve multi-axis rotational pose estimation with high precision. Our extensive trials using our in-house built testbed have shown that SpecTrack achieves an accuracy of 0.31{\deg} (std=0.43{\deg}), significantly outperforming state-of-the-art approaches and improving accuracy up to 200%.
Learned Single-Pass Multitasking Perceptual Graphics for Immersive Displays
Jul 31, 2024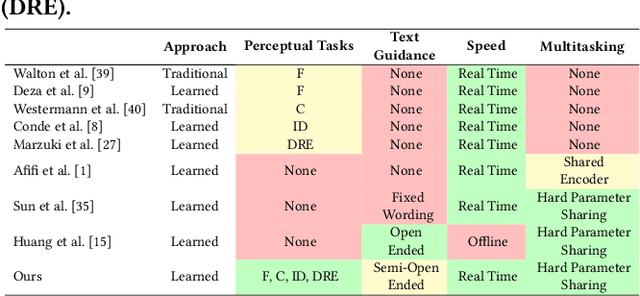
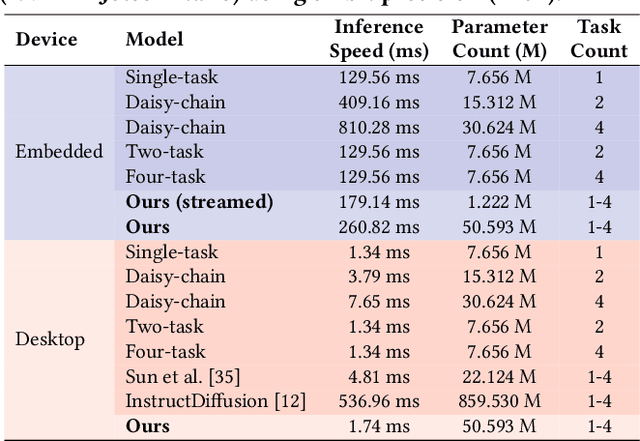
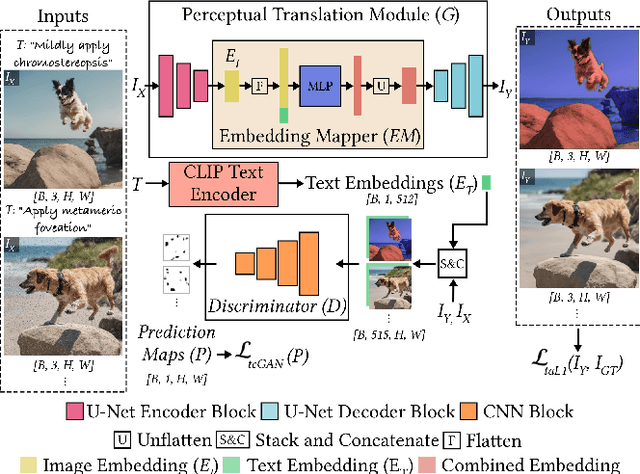
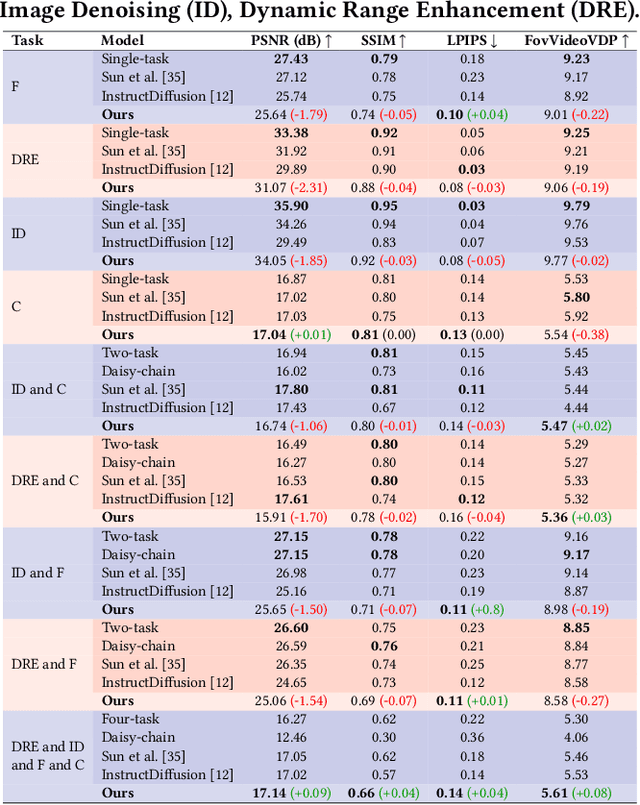
Immersive displays are advancing rapidly in terms of delivering perceptually realistic images by utilizing emerging perceptual graphics methods such as foveated rendering. In practice, multiple such methods need to be performed sequentially for enhanced perceived quality. However, the limited power and computational resources of the devices that drive immersive displays make it challenging to deploy multiple perceptual models simultaneously. We address this challenge by proposing a computationally-lightweight, text-guided, learned multitasking perceptual graphics model. Given RGB input images, our model outputs perceptually enhanced images by performing one or more perceptual tasks described by the provided text prompts. Our model supports a variety of perceptual tasks, including foveated rendering, dynamic range enhancement, image denoising, and chromostereopsis, through multitask learning. Uniquely, a single inference step of our model supports different permutations of these perceptual tasks at different prompted rates (i.e., mildly, lightly), eliminating the need for daisy-chaining multiple models to get the desired perceptual effect. We train our model on our new dataset of source and perceptually enhanced images, and their corresponding text prompts. We evaluate our model's performance on embedded platforms and validate the perceptual quality of our model through a user study. Our method achieves on-par quality with the state-of-the-art task-specific methods using a single inference step, while offering faster inference speeds and flexibility to blend effects at various intensities.
All-optical image denoising using a diffractive visual processor
Sep 17, 2023Image denoising, one of the essential inverse problems, targets to remove noise/artifacts from input images. In general, digital image denoising algorithms, executed on computers, present latency due to several iterations implemented in, e.g., graphics processing units (GPUs). While deep learning-enabled methods can operate non-iteratively, they also introduce latency and impose a significant computational burden, leading to increased power consumption. Here, we introduce an analog diffractive image denoiser to all-optically and non-iteratively clean various forms of noise and artifacts from input images - implemented at the speed of light propagation within a thin diffractive visual processor. This all-optical image denoiser comprises passive transmissive layers optimized using deep learning to physically scatter the optical modes that represent various noise features, causing them to miss the output image Field-of-View (FoV) while retaining the object features of interest. Our results show that these diffractive denoisers can efficiently remove salt and pepper noise and image rendering-related spatial artifacts from input phase or intensity images while achieving an output power efficiency of ~30-40%. We experimentally demonstrated the effectiveness of this analog denoiser architecture using a 3D-printed diffractive visual processor operating at the terahertz spectrum. Owing to their speed, power-efficiency, and minimal computational overhead, all-optical diffractive denoisers can be transformative for various image display and projection systems, including, e.g., holographic displays.
AutoColor: Learned Light Power Control for Multi-Color Holograms
May 02, 2023Multi-color holograms rely on simultaneous illumination from multiple light sources. These multi-color holograms could utilize light sources better than conventional single-color holograms and can improve the dynamic range of holographic displays. In this letter, we introduce \projectname, the first learned method for estimating the optimal light source powers required for illuminating multi-color holograms. For this purpose, we establish the first multi-color hologram dataset using synthetic images and their depth information. We generate these synthetic images using a trending pipeline combining generative, large language, and monocular depth estimation models. Finally, we train our learned model using our dataset and experimentally demonstrate that \projectname significantly decreases the number of steps required to optimize multi-color holograms from $>1000$ to $70$ iteration steps without compromising image quality.
ChromaCorrect: Prescription Correction in Virtual Reality Headsets through Perceptual Guidance
Dec 08, 2022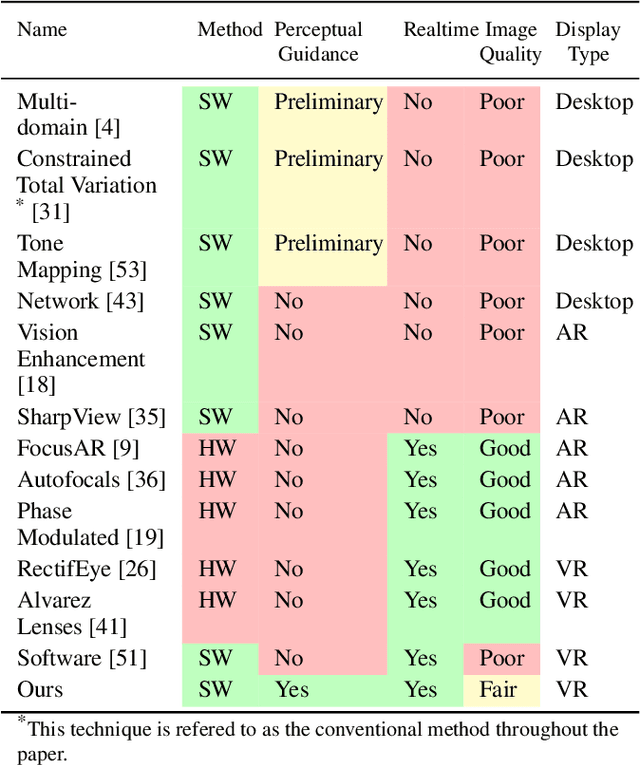

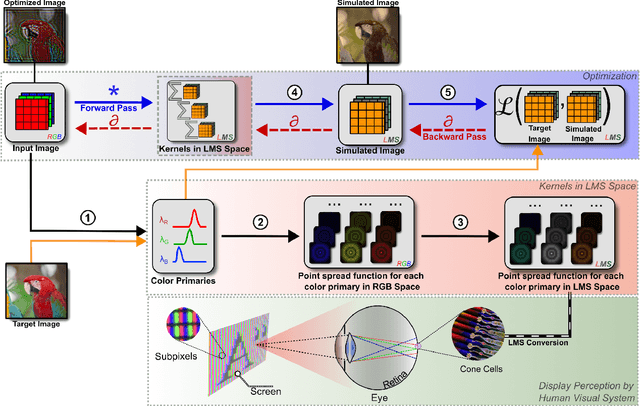

A large portion of today's world population suffer from vision impairments and wear prescription eyeglasses. However, eyeglasses causes additional bulk and discomfort when used with augmented and virtual reality headsets, thereby negatively impacting the viewer's visual experience. In this work, we remedy the usage of prescription eyeglasses in Virtual Reality (VR) headsets by shifting the optical complexity completely into software and propose a prescription-aware rendering approach for providing sharper and immersive VR imagery. To this end, we develop a differentiable display and visual perception model encapsulating display-specific parameters, color and visual acuity of human visual system and the user-specific refractive errors. Using this differentiable visual perception model, we optimize the rendered imagery in the display using stochastic gradient-descent solvers. This way, we provide prescription glasses-free sharper images for a person with vision impairments. We evaluate our approach on various displays, including desktops and VR headsets, and show significant quality and contrast improvements for users with vision impairments.
Realistic Defocus Blur for Multiplane Computer-Generated Holography
May 14, 2022

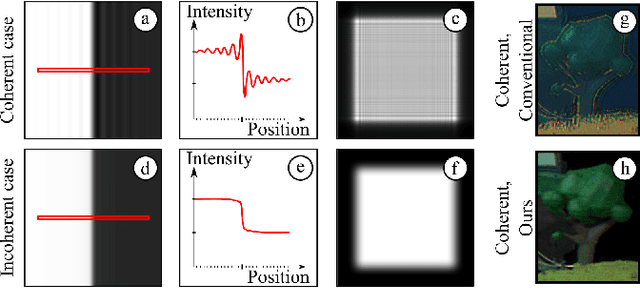

This paper introduces a new multiplane CGH computation method to reconstruct artefact-free high-quality holograms with natural-looking defocus blur. Our method introduces a new targeting scheme and a new loss function. While the targeting scheme accounts for defocused parts of the scene at each depth plane, the new loss function analyzes focused and defocused parts separately in reconstructed images. Our method support phase-only CGH calculations using various iterative (e.g., Gerchberg-Saxton, Gradient Descent) and non-iterative (e.g., Double Phase) CGH techniques. We achieve our best image quality using a modified gradient descent-based optimization recipe where we introduce a constraint inspired by the double phase method. We validate our method experimentally using our proof-of-concept holographic display, comparing various algorithms, including multi-depth scenes with sparse and dense contents.
Unrolled Primal-Dual Networks for Lensless Cameras
Mar 08, 2022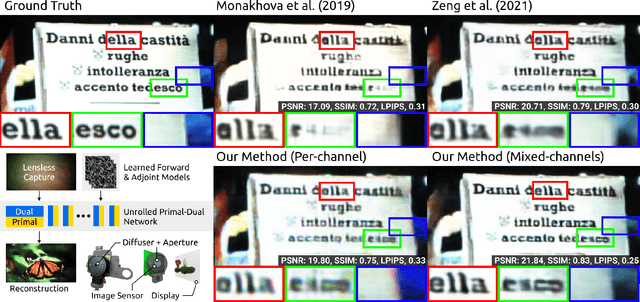
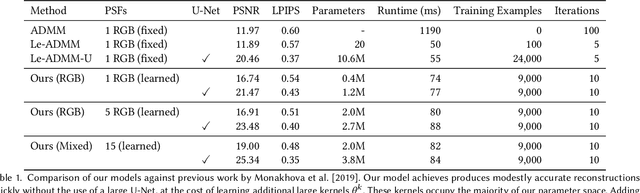
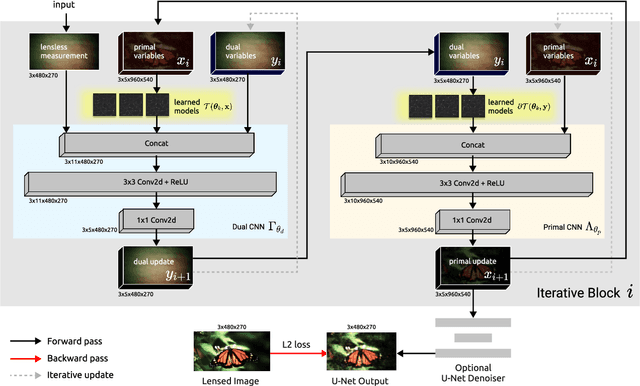

Conventional image reconstruction models for lensless cameras often assume that each measurement results from convolving a given scene with a single experimentally measured point-spread function. These image reconstruction models fall short in simulating lensless cameras truthfully as these models are not sophisticated enough to account for optical aberrations or scenes with depth variations. Our work shows that learning a supervised primal-dual reconstruction method results in image quality matching state of the art in the literature without demanding a large network capacity. This improvement stems from our primary finding that embedding learnable forward and adjoint models in a learned primal-dual optimization framework can even improve the quality of reconstructed images (+5dB PSNR) compared to works that do not correct for the model error. In addition, we built a proof-of-concept lensless camera prototype that uses a pseudo-random phase mask to demonstrate our point. Finally, we share the extensive evaluation of our learned model based on an open dataset and a dataset from our proof-of-concept lensless camera prototype.