 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheory, Analysis, and Best Practices for Sigmoid Self-Attention
Sep 06, 2024



Attention is a key part of the transformer architecture. It is a sequence-to-sequence mapping that transforms each sequence element into a weighted sum of values. The weights are typically obtained as the softmax of dot products between keys and queries. Recent work has explored alternatives to softmax attention in transformers, such as ReLU and sigmoid activations. In this work, we revisit sigmoid attention and conduct an in-depth theoretical and empirical analysis. Theoretically, we prove that transformers with sigmoid attention are universal function approximators and benefit from improved regularity compared to softmax attention. Through detailed empirical analysis, we identify stabilization of large initial attention norms during the early stages of training as a crucial factor for the successful training of models with sigmoid attention, outperforming prior attempts. We also introduce FLASHSIGMOID, a hardware-aware and memory-efficient implementation of sigmoid attention yielding a 17% inference kernel speed-up over FLASHATTENTION2 on H100 GPUs. Experiments across language, vision, and speech show that properly normalized sigmoid attention matches the strong performance of softmax attention on a wide range of domains and scales, which previous attempts at sigmoid attention were unable to fully achieve. Our work unifies prior art and establishes best practices for sigmoid attention as a drop-in softmax replacement in transformers.
All-optical image denoising using a diffractive visual processor
Sep 17, 2023Image denoising, one of the essential inverse problems, targets to remove noise/artifacts from input images. In general, digital image denoising algorithms, executed on computers, present latency due to several iterations implemented in, e.g., graphics processing units (GPUs). While deep learning-enabled methods can operate non-iteratively, they also introduce latency and impose a significant computational burden, leading to increased power consumption. Here, we introduce an analog diffractive image denoiser to all-optically and non-iteratively clean various forms of noise and artifacts from input images - implemented at the speed of light propagation within a thin diffractive visual processor. This all-optical image denoiser comprises passive transmissive layers optimized using deep learning to physically scatter the optical modes that represent various noise features, causing them to miss the output image Field-of-View (FoV) while retaining the object features of interest. Our results show that these diffractive denoisers can efficiently remove salt and pepper noise and image rendering-related spatial artifacts from input phase or intensity images while achieving an output power efficiency of ~30-40%. We experimentally demonstrated the effectiveness of this analog denoiser architecture using a 3D-printed diffractive visual processor operating at the terahertz spectrum. Owing to their speed, power-efficiency, and minimal computational overhead, all-optical diffractive denoisers can be transformative for various image display and projection systems, including, e.g., holographic displays.
A Framework for Discovering Optimal Solutions in Photonic Inverse Design
Jun 03, 2021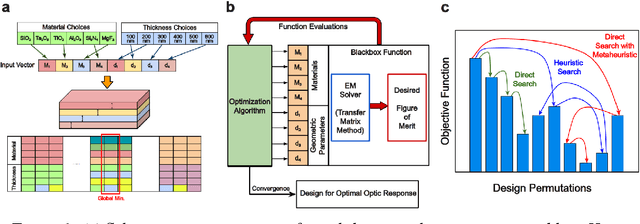
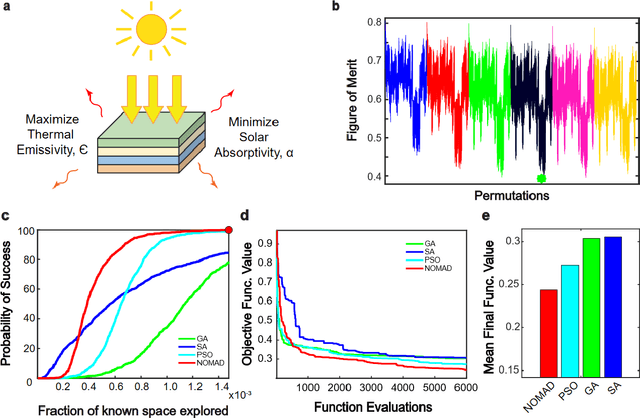
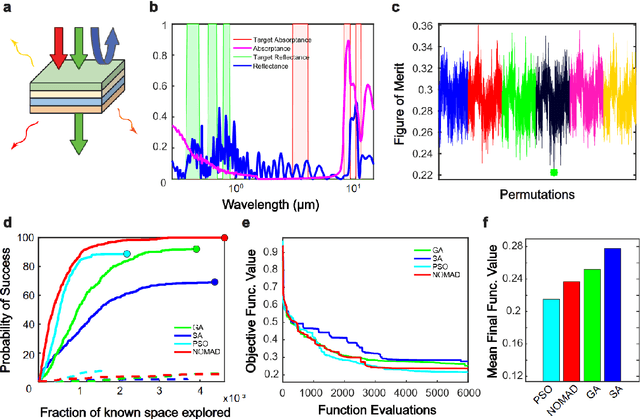
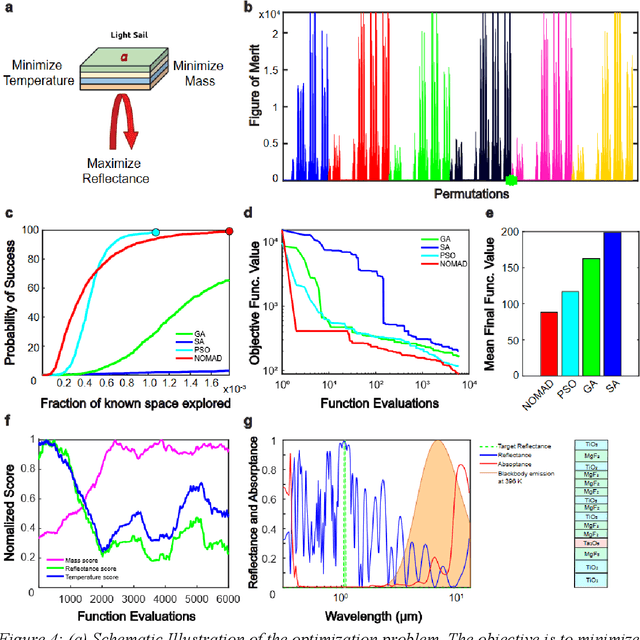
Photonic inverse design has emerged as an indispensable engineering tool for complex optical systems. In many instances it is important to optimize for both material and geometry configurations, which results in complex non-smooth search spaces with multiple local minima. Finding solutions approaching global optimum may present a computationally intractable task. Here, we develop a framework that allows expediting the search of solutions close to global optimum on complex optimization spaces. We study the way representative black box optimization algorithms work, including genetic algorithm (GA), particle swarm optimization (PSO), simulated annealing (SA), and mesh adaptive direct search (NOMAD). We then propose and utilize a two-step approach that identifies best performance algorithms on arbitrarily complex search spaces. We reveal a connection between the search space complexity and algorithm performance and find that PSO and NOMAD consistently deliver better performance for mixed integer problems encountered in photonic inverse design, particularly with the account of material combinations. Our results differ from a commonly anticipated advantage of GA. Our findings will foster more efficient design of photonic systems with optimal performance.