 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenCtrl -- A Formal Controllability Toolkit for Generative Models
Jan 09, 2026As generative models become ubiquitous, there is a critical need for fine-grained control over the generation process. Yet, while controlled generation methods from prompting to fine-tuning proliferate, a fundamental question remains unanswered: are these models truly controllable in the first place? In this work, we provide a theoretical framework to formally answer this question. Framing human-model interaction as a control process, we propose a novel algorithm to estimate the controllable sets of models in a dialogue setting. Notably, we provide formal guarantees on the estimation error as a function of sample complexity: we derive probably-approximately correct bounds for controllable set estimates that are distribution-free, employ no assumptions except for output boundedness, and work for any black-box nonlinear control system (i.e., any generative model). We empirically demonstrate the theoretical framework on different tasks in controlling dialogue processes, for both language models and text-to-image generation. Our results show that model controllability is surprisingly fragile and highly dependent on the experimental setting. This highlights the need for rigorous controllability analysis, shifting the focus from simply attempting control to first understanding its fundamental limits.
ParaRNN: Unlocking Parallel Training of Nonlinear RNNs for Large Language Models
Oct 24, 2025Recurrent Neural Networks (RNNs) laid the foundation for sequence modeling, but their intrinsic sequential nature restricts parallel computation, creating a fundamental barrier to scaling. This has led to the dominance of parallelizable architectures like Transformers and, more recently, State Space Models (SSMs). While SSMs achieve efficient parallelization through structured linear recurrences, this linearity constraint limits their expressive power and precludes modeling complex, nonlinear sequence-wise dependencies. To address this, we present ParaRNN, a framework that breaks the sequence-parallelization barrier for nonlinear RNNs. Building on prior work, we cast the sequence of nonlinear recurrence relationships as a single system of equations, which we solve in parallel using Newton's iterations combined with custom parallel reductions. Our implementation achieves speedups of up to 665x over naive sequential application, allowing training nonlinear RNNs at unprecedented scales. To showcase this, we apply ParaRNN to adaptations of LSTM and GRU architectures, successfully training models of 7B parameters that attain perplexity comparable to similarly-sized Transformers and Mamba2 architectures. To accelerate research in efficient sequence modeling, we release the ParaRNN codebase as an open-source framework for automatic training-parallelization of nonlinear RNNs, enabling researchers and practitioners to explore new nonlinear RNN models at scale.
Understanding Input Selectivity in Mamba: Impact on Approximation Power, Memorization, and Associative Recall Capacity
Jun 13, 2025State-Space Models (SSMs), and particularly Mamba, have recently emerged as a promising alternative to Transformers. Mamba introduces input selectivity to its SSM layer (S6) and incorporates convolution and gating into its block definition. While these modifications do improve Mamba's performance over its SSM predecessors, it remains largely unclear how Mamba leverages the additional functionalities provided by input selectivity, and how these interact with the other operations in the Mamba architecture. In this work, we demystify the role of input selectivity in Mamba, investigating its impact on function approximation power, long-term memorization, and associative recall capabilities. In particular: (i) we prove that the S6 layer of Mamba can represent projections onto Haar wavelets, providing an edge over its Diagonal SSM (S4D) predecessor in approximating discontinuous functions commonly arising in practice; (ii) we show how the S6 layer can dynamically counteract memory decay; (iii) we provide analytical solutions to the MQAR associative recall task using the Mamba architecture with different mixers -- Mamba, Mamba-2, and S4D. We demonstrate the tightness of our theoretical constructions with empirical results on concrete tasks. Our findings offer a mechanistic understanding of Mamba and reveal opportunities for improvement.
Revisiting Uncertainty Quantification Evaluation in Language Models: Spurious Interactions with Response Length Bias Results
Apr 18, 2025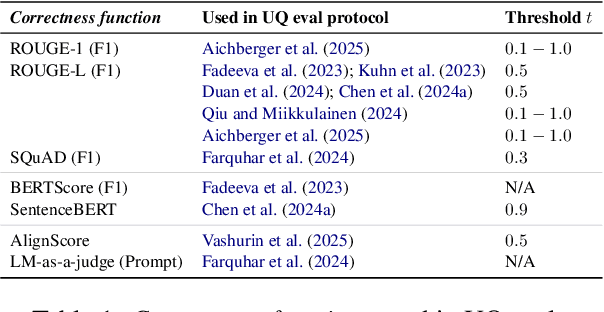
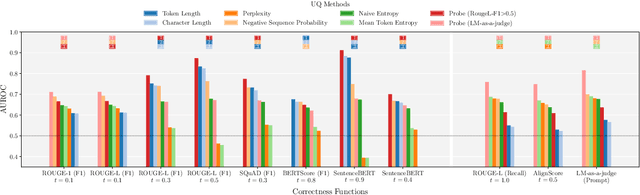
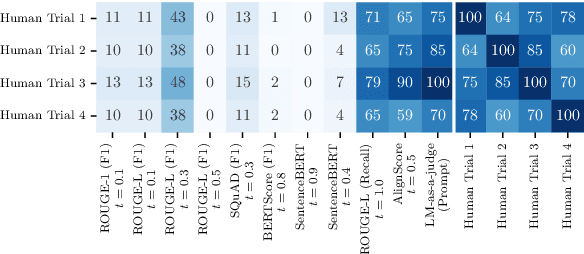
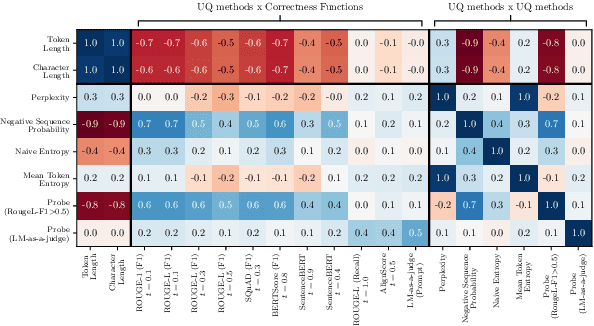
Uncertainty Quantification (UQ) in Language Models (LMs) is crucial for improving their safety and reliability. Evaluations often use performance metrics like AUROC to assess how well UQ methods (e.g., negative sequence probabilities) correlate with task correctness functions (e.g., ROUGE-L). In this paper, we show that commonly used correctness functions bias UQ evaluations by inflating the performance of certain UQ methods. We evaluate 7 correctness functions -- from lexical-based and embedding-based metrics to LLM-as-a-judge approaches -- across 4 datasets x 4 models x 6 UQ methods. Our analysis reveals that length biases in the errors of these correctness functions distort UQ assessments by interacting with length biases in UQ methods. We identify LLM-as-a-judge approaches as among the least length-biased choices and hence a potential solution to mitigate these biases.
Theory, Analysis, and Best Practices for Sigmoid Self-Attention
Sep 06, 2024



Attention is a key part of the transformer architecture. It is a sequence-to-sequence mapping that transforms each sequence element into a weighted sum of values. The weights are typically obtained as the softmax of dot products between keys and queries. Recent work has explored alternatives to softmax attention in transformers, such as ReLU and sigmoid activations. In this work, we revisit sigmoid attention and conduct an in-depth theoretical and empirical analysis. Theoretically, we prove that transformers with sigmoid attention are universal function approximators and benefit from improved regularity compared to softmax attention. Through detailed empirical analysis, we identify stabilization of large initial attention norms during the early stages of training as a crucial factor for the successful training of models with sigmoid attention, outperforming prior attempts. We also introduce FLASHSIGMOID, a hardware-aware and memory-efficient implementation of sigmoid attention yielding a 17% inference kernel speed-up over FLASHATTENTION2 on H100 GPUs. Experiments across language, vision, and speech show that properly normalized sigmoid attention matches the strong performance of softmax attention on a wide range of domains and scales, which previous attempts at sigmoid attention were unable to fully achieve. Our work unifies prior art and establishes best practices for sigmoid attention as a drop-in softmax replacement in transformers.
DeepPCR: Parallelizing Sequential Operations in Neural Networks
Sep 28, 2023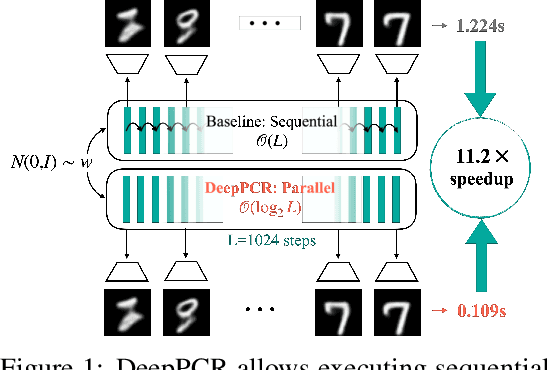



Parallelization techniques have become ubiquitous for accelerating inference and training of deep neural networks. Despite this, several operations are still performed in a sequential manner. For instance, the forward and backward passes are executed layer-by-layer, and the output of diffusion models is produced by applying a sequence of denoising steps. This sequential approach results in a computational cost proportional to the number of steps involved, presenting a potential bottleneck as the number of steps increases. In this work, we introduce DeepPCR, a novel algorithm which parallelizes typically sequential operations used in inference and training of neural networks. DeepPCR is based on interpreting a sequence of $L$ steps as the solution of a specific system of equations, which we recover using the Parallel Cyclic Reduction algorithm. This reduces the complexity of computing the sequential operations from $\mathcal{O}(L)$ to $\mathcal{O}(\log_2L)$, thus yielding a speedup for large $L$. To verify the theoretical lower complexity of the algorithm, and to identify regimes for speedup, we test the effectiveness of DeepPCR in parallelizing the forward and backward pass in multi-layer perceptrons, and reach speedups of up to $30\times$ for forward and $200\times$ for backward pass. We additionally showcase the flexibility of DeepPCR by parallelizing training of ResNets with as many as 1024 layers, and generation in diffusion models, enabling up to $7\times$ faster training and $11\times$ faster generation, respectively, when compared to the sequential approach.
REALM: Robust Entropy Adaptive Loss Minimization for Improved Single-Sample Test-Time Adaptation
Sep 07, 2023



Fully-test-time adaptation (F-TTA) can mitigate performance loss due to distribution shifts between train and test data (1) without access to the training data, and (2) without knowledge of the model training procedure. In online F-TTA, a pre-trained model is adapted using a stream of test samples by minimizing a self-supervised objective, such as entropy minimization. However, models adapted with online using entropy minimization, are unstable especially in single sample settings, leading to degenerate solutions, and limiting the adoption of TTA inference strategies. Prior works identify noisy, or unreliable, samples as a cause of failure in online F-TTA. One solution is to ignore these samples, which can lead to bias in the update procedure, slow adaptation, and poor generalization. In this work, we present a general framework for improving robustness of F-TTA to these noisy samples, inspired by self-paced learning and robust loss functions. Our proposed approach, Robust Entropy Adaptive Loss Minimization (REALM), achieves better adaptation accuracy than previous approaches throughout the adaptation process on corruptions of CIFAR-10 and ImageNet-1K, demonstrating its effectiveness.
DUET: 2D Structured and Approximately Equivariant Representations
Jun 30, 2023Multiview Self-Supervised Learning (MSSL) is based on learning invariances with respect to a set of input transformations. However, invariance partially or totally removes transformation-related information from the representations, which might harm performance for specific downstream tasks that require such information. We propose 2D strUctured and EquivarianT representations (coined DUET), which are 2d representations organized in a matrix structure, and equivariant with respect to transformations acting on the input data. DUET representations maintain information about an input transformation, while remaining semantically expressive. Compared to SimCLR (Chen et al., 2020) (unstructured and invariant) and ESSL (Dangovski et al., 2022) (unstructured and equivariant), the structured and equivariant nature of DUET representations enables controlled generation with lower reconstruction error, while controllability is not possible with SimCLR or ESSL. DUET also achieves higher accuracy for several discriminative tasks, and improves transfer learning.