 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParaRNN: Unlocking Parallel Training of Nonlinear RNNs for Large Language Models
Oct 24, 2025Recurrent Neural Networks (RNNs) laid the foundation for sequence modeling, but their intrinsic sequential nature restricts parallel computation, creating a fundamental barrier to scaling. This has led to the dominance of parallelizable architectures like Transformers and, more recently, State Space Models (SSMs). While SSMs achieve efficient parallelization through structured linear recurrences, this linearity constraint limits their expressive power and precludes modeling complex, nonlinear sequence-wise dependencies. To address this, we present ParaRNN, a framework that breaks the sequence-parallelization barrier for nonlinear RNNs. Building on prior work, we cast the sequence of nonlinear recurrence relationships as a single system of equations, which we solve in parallel using Newton's iterations combined with custom parallel reductions. Our implementation achieves speedups of up to 665x over naive sequential application, allowing training nonlinear RNNs at unprecedented scales. To showcase this, we apply ParaRNN to adaptations of LSTM and GRU architectures, successfully training models of 7B parameters that attain perplexity comparable to similarly-sized Transformers and Mamba2 architectures. To accelerate research in efficient sequence modeling, we release the ParaRNN codebase as an open-source framework for automatic training-parallelization of nonlinear RNNs, enabling researchers and practitioners to explore new nonlinear RNN models at scale.
Understanding Input Selectivity in Mamba: Impact on Approximation Power, Memorization, and Associative Recall Capacity
Jun 13, 2025State-Space Models (SSMs), and particularly Mamba, have recently emerged as a promising alternative to Transformers. Mamba introduces input selectivity to its SSM layer (S6) and incorporates convolution and gating into its block definition. While these modifications do improve Mamba's performance over its SSM predecessors, it remains largely unclear how Mamba leverages the additional functionalities provided by input selectivity, and how these interact with the other operations in the Mamba architecture. In this work, we demystify the role of input selectivity in Mamba, investigating its impact on function approximation power, long-term memorization, and associative recall capabilities. In particular: (i) we prove that the S6 layer of Mamba can represent projections onto Haar wavelets, providing an edge over its Diagonal SSM (S4D) predecessor in approximating discontinuous functions commonly arising in practice; (ii) we show how the S6 layer can dynamically counteract memory decay; (iii) we provide analytical solutions to the MQAR associative recall task using the Mamba architecture with different mixers -- Mamba, Mamba-2, and S4D. We demonstrate the tightness of our theoretical constructions with empirical results on concrete tasks. Our findings offer a mechanistic understanding of Mamba and reveal opportunities for improvement.
Learning Spatially-Aware Language and Audio Embedding
Sep 17, 2024



Humans can picture a sound scene given an imprecise natural language description. For example, it is easy to imagine an acoustic environment given a phrase like "the lion roar came from right behind me!". For a machine to have the same degree of comprehension, the machine must know what a lion is (semantic attribute), what the concept of "behind" is (spatial attribute) and how these pieces of linguistic information align with the semantic and spatial attributes of the sound (what a roar sounds like when its coming from behind). State-of-the-art audio foundation models which learn to map between audio scenes and natural textual descriptions, are trained on non-spatial audio and text pairs, and hence lack spatial awareness. In contrast, sound event localization and detection models are limited to recognizing sounds from a fixed number of classes, and they localize the source to absolute position (e.g., 0.2m) rather than a position described using natural language (e.g., "next to me"). To address these gaps, we present ELSA a spatially aware-audio and text embedding model trained using multimodal contrastive learning. ELSA supports non-spatial audio, spatial audio, and open vocabulary text captions describing both the spatial and semantic components of sound. To train ELSA: (a) we spatially augment the audio and captions of three open-source audio datasets totaling 4,738 hours of audio, and (b) we design an encoder to capture the semantics of non-spatial audio, and the semantics and spatial attributes of spatial audio using contrastive learning. ELSA is competitive with state-of-the-art for both semantic retrieval and 3D source localization. In particular, ELSA achieves +2.8% mean audio-to-text and text-to-audio R@1 above the baseline, and outperforms by -11.6{\deg} mean-absolute-error in 3D source localization over the baseline.
Sample-Efficient Preference-based Reinforcement Learning with Dynamics Aware Rewards
Feb 28, 2024Preference-based reinforcement learning (PbRL) aligns a robot behavior with human preferences via a reward function learned from binary feedback over agent behaviors. We show that dynamics-aware reward functions improve the sample efficiency of PbRL by an order of magnitude. In our experiments we iterate between: (1) learning a dynamics-aware state-action representation (z^{sa}) via a self-supervised temporal consistency task, and (2) bootstrapping the preference-based reward function from (z^{sa}), which results in faster policy learning and better final policy performance. For example, on quadruped-walk, walker-walk, and cheetah-run, with 50 preference labels we achieve the same performance as existing approaches with 500 preference labels, and we recover 83\% and 66\% of ground truth reward policy performance versus only 38\% and 21\%. The performance gains demonstrate the benefits of explicitly learning a dynamics-aware reward model. Repo: \texttt{https://github.com/apple/ml-reed}.
Novel-View Acoustic Synthesis from 3D Reconstructed Rooms
Oct 23, 2023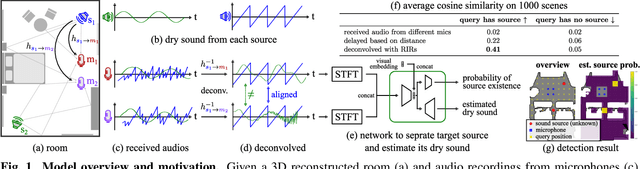
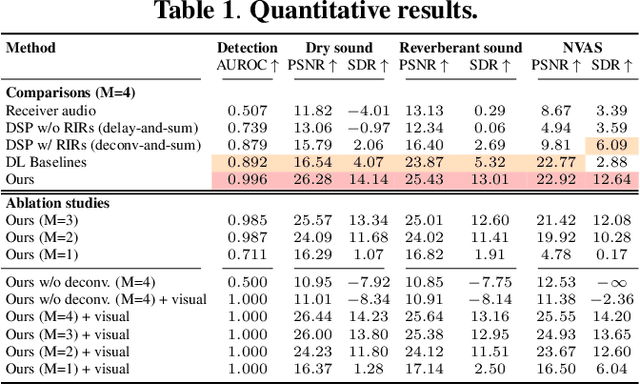
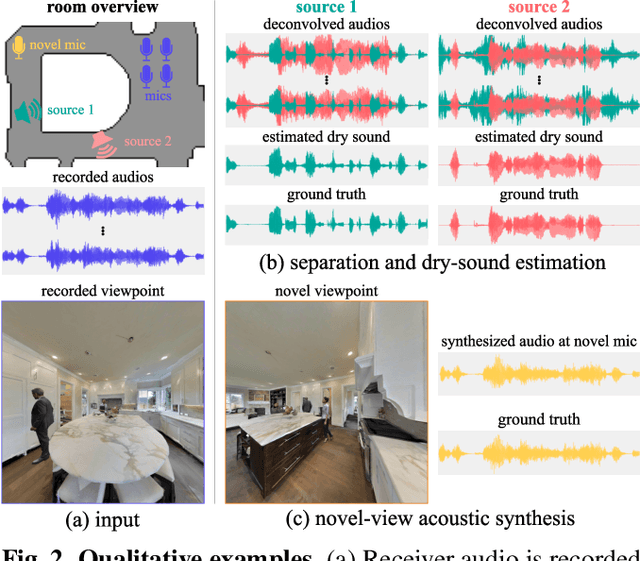
We investigate the benefit of combining blind audio recordings with 3D scene information for novel-view acoustic synthesis. Given audio recordings from 2-4 microphones and the 3D geometry and material of a scene containing multiple unknown sound sources, we estimate the sound anywhere in the scene. We identify the main challenges of novel-view acoustic synthesis as sound source localization, separation, and dereverberation. While naively training an end-to-end network fails to produce high-quality results, we show that incorporating room impulse responses (RIRs) derived from 3D reconstructed rooms enables the same network to jointly tackle these tasks. Our method outperforms existing methods designed for the individual tasks, demonstrating its effectiveness at utilizing 3D visual information. In a simulated study on the Matterport3D-NVAS dataset, our model achieves near-perfect accuracy on source localization, a PSNR of 26.44 dB and a SDR of 14.23 dB for source separation and dereverberation, resulting in a PSNR of 25.55 dB and a SDR of 14.20 dB on novel-view acoustic synthesis. Code, pretrained model, and video results are available on the project webpage (https://github.com/apple/ml-nvas3d).
DeepPCR: Parallelizing Sequential Operations in Neural Networks
Sep 28, 2023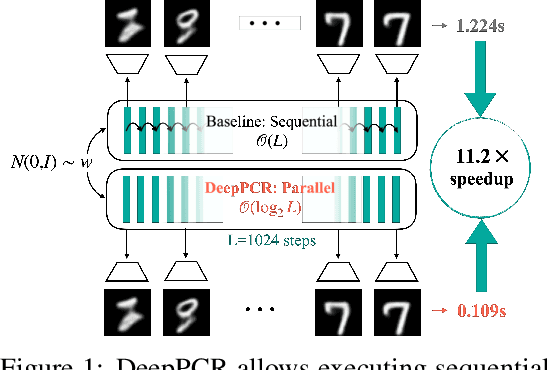



Parallelization techniques have become ubiquitous for accelerating inference and training of deep neural networks. Despite this, several operations are still performed in a sequential manner. For instance, the forward and backward passes are executed layer-by-layer, and the output of diffusion models is produced by applying a sequence of denoising steps. This sequential approach results in a computational cost proportional to the number of steps involved, presenting a potential bottleneck as the number of steps increases. In this work, we introduce DeepPCR, a novel algorithm which parallelizes typically sequential operations used in inference and training of neural networks. DeepPCR is based on interpreting a sequence of $L$ steps as the solution of a specific system of equations, which we recover using the Parallel Cyclic Reduction algorithm. This reduces the complexity of computing the sequential operations from $\mathcal{O}(L)$ to $\mathcal{O}(\log_2L)$, thus yielding a speedup for large $L$. To verify the theoretical lower complexity of the algorithm, and to identify regimes for speedup, we test the effectiveness of DeepPCR in parallelizing the forward and backward pass in multi-layer perceptrons, and reach speedups of up to $30\times$ for forward and $200\times$ for backward pass. We additionally showcase the flexibility of DeepPCR by parallelizing training of ResNets with as many as 1024 layers, and generation in diffusion models, enabling up to $7\times$ faster training and $11\times$ faster generation, respectively, when compared to the sequential approach.
Spatial LibriSpeech: An Augmented Dataset for Spatial Audio Learning
Aug 18, 2023



We present Spatial LibriSpeech, a spatial audio dataset with over 650 hours of 19-channel audio, first-order ambisonics, and optional distractor noise. Spatial LibriSpeech is designed for machine learning model training, and it includes labels for source position, speaking direction, room acoustics and geometry. Spatial LibriSpeech is generated by augmenting LibriSpeech samples with 200k+ simulated acoustic conditions across 8k+ synthetic rooms. To demonstrate the utility of our dataset, we train models on four spatial audio tasks, resulting in a median absolute error of 6.60{\deg} on 3D source localization, 0.43m on distance, 90.66ms on T30, and 2.74dB on DRR estimation. We show that the same models generalize well to widely-used evaluation datasets, e.g., obtaining a median absolute error of 12.43{\deg} on 3D source localization on TUT Sound Events 2018, and 157.32ms on T30 estimation on ACE Challenge.
Rewards Encoding Environment Dynamics Improves Preference-based Reinforcement Learning
Nov 12, 2022



Preference-based reinforcement learning (RL) algorithms help avoid the pitfalls of hand-crafted reward functions by distilling them from human preference feedback, but they remain impractical due to the burdensome number of labels required from the human, even for relatively simple tasks. In this work, we demonstrate that encoding environment dynamics in the reward function (REED) dramatically reduces the number of preference labels required in state-of-the-art preference-based RL frameworks. We hypothesize that REED-based methods better partition the state-action space and facilitate generalization to state-action pairs not included in the preference dataset. REED iterates between encoding environment dynamics in a state-action representation via a self-supervised temporal consistency task, and bootstrapping the preference-based reward function from the state-action representation. Whereas prior approaches train only on the preference-labelled trajectory pairs, REED exposes the state-action representation to all transitions experienced during policy training. We explore the benefits of REED within the PrefPPO [1] and PEBBLE [2] preference learning frameworks and demonstrate improvements across experimental conditions to both the speed of policy learning and the final policy performance. For example, on quadruped-walk and walker-walk with 50 preference labels, REED-based reward functions recover 83% and 66% of ground truth reward policy performance and without REED only 38\% and 21\% are recovered. For some domains, REED-based reward functions result in policies that outperform policies trained on the ground truth reward.
Contrastive Self-Supervised Learning for Skeleton Representations
Nov 10, 2022Human skeleton point clouds are commonly used to automatically classify and predict the behaviour of others. In this paper, we use a contrastive self-supervised learning method, SimCLR, to learn representations that capture the semantics of skeleton point clouds. This work focuses on systematically evaluating the effects that different algorithmic decisions (including augmentations, dataset partitioning and backbone architecture) have on the learned skeleton representations. To pre-train the representations, we normalise six existing datasets to obtain more than 40 million skeleton frames. We evaluate the quality of the learned representations with three downstream tasks: skeleton reconstruction, motion prediction, and activity classification. Our results demonstrate the importance of 1) combining spatial and temporal augmentations, 2) including additional datasets for encoder training, and 3) and using a graph neural network as an encoder.
Towards a Perceptual Model for Estimating the Quality of Visual Speech
Mar 24, 2022

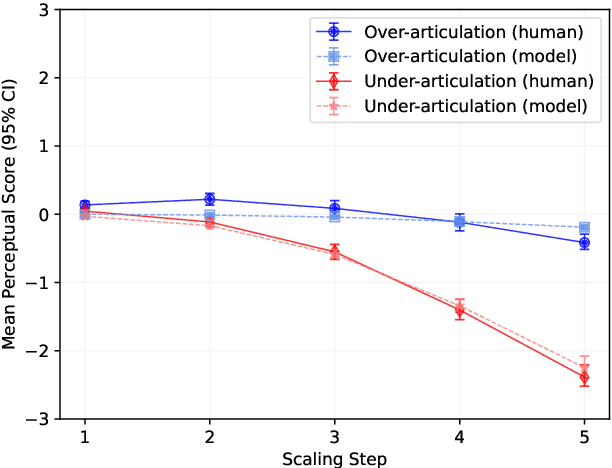
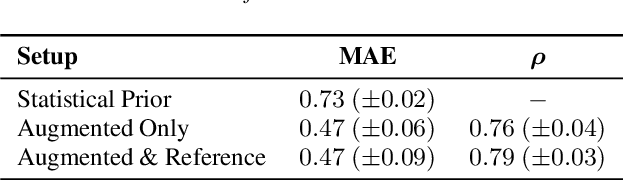
Generating realistic lip motions to simulate speech production is key for driving natural character animations from audio. Previous research has shown that traditional metrics used to optimize and assess models for generating lip motions from speech are not a good indicator of subjective opinion of animation quality. Yet, running repetitive subjective studies for assessing the quality of animations can be time-consuming and difficult to replicate. In this work, we seek to understand the relationship between perturbed lip motion and subjective opinion of lip motion quality. Specifically, we adjust the degree of articulation for lip motion sequences and run a user-study to examine how this adjustment impacts the perceived quality of lip motion. We then train a model using the scores collected from our user-study to automatically predict the subjective quality of an animated sequence. Our results show that (1) users score lip motions with slight over-articulation the highest in terms of perceptual quality; (2) under-articulation had a more detrimental effect on perceived quality of lip motion compared to the effect of over-articulation; and (3) we can automatically estimate the subjective perceptual score for a given lip motion sequences with low error rates.