 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnrolled Primal-Dual Networks for Lensless Cameras
Mar 08, 2022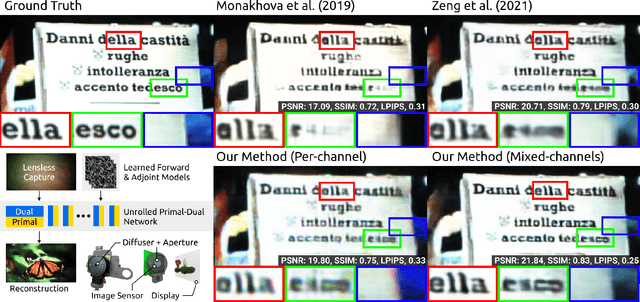
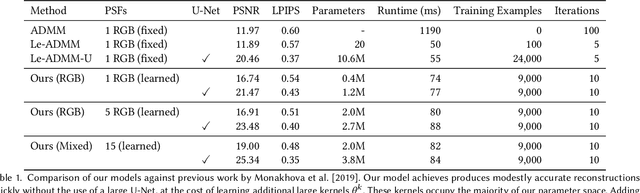
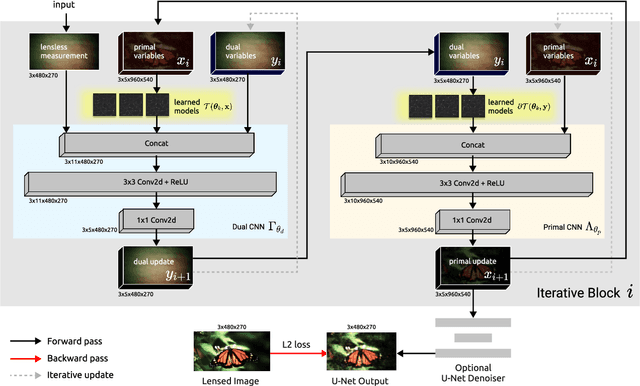

Conventional image reconstruction models for lensless cameras often assume that each measurement results from convolving a given scene with a single experimentally measured point-spread function. These image reconstruction models fall short in simulating lensless cameras truthfully as these models are not sophisticated enough to account for optical aberrations or scenes with depth variations. Our work shows that learning a supervised primal-dual reconstruction method results in image quality matching state of the art in the literature without demanding a large network capacity. This improvement stems from our primary finding that embedding learnable forward and adjoint models in a learned primal-dual optimization framework can even improve the quality of reconstructed images (+5dB PSNR) compared to works that do not correct for the model error. In addition, we built a proof-of-concept lensless camera prototype that uses a pseudo-random phase mask to demonstrate our point. Finally, we share the extensive evaluation of our learned model based on an open dataset and a dataset from our proof-of-concept lensless camera prototype.