 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRS: Generating Robotic Simulation Tasks from Real-World Images
Oct 20, 2024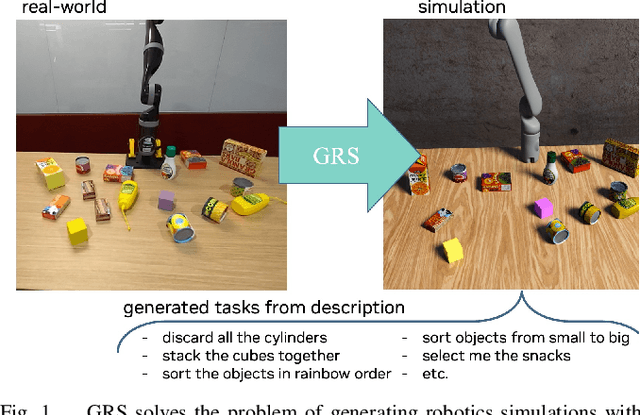
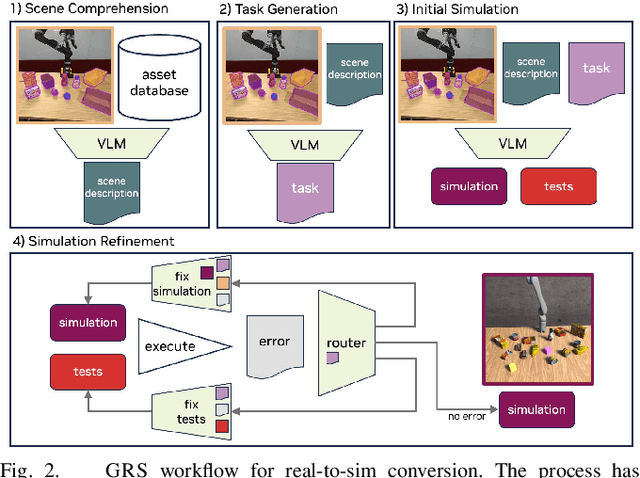


We introduce GRS (Generating Robotic Simulation tasks), a novel system to address the challenge of real-to-sim in robotics, computer vision, and AR/VR. GRS enables the creation of digital twin simulations from single real-world RGB-D observations, complete with diverse, solvable tasks for virtual agent training. We use state-of-the-art vision-language models (VLMs) to achieve a comprehensive real-to-sim pipeline. GRS operates in three stages: 1) scene comprehension using SAM2 for object segmentation and VLMs for object description, 2) matching identified objects with simulation-ready assets, and 3) generating contextually appropriate robotic tasks. Our approach ensures simulations align with task specifications by generating test suites designed to verify adherence to the task specification. We introduce a router that iteratively refines the simulation and test code to ensure the simulation is solvable by a robot policy while remaining aligned to the task specification. Our experiments demonstrate the system's efficacy in accurately identifying object correspondence, which allows us to generate task environments that closely match input environments, and enhance automated simulation task generation through our novel router mechanism.
SpecTrack: Learned Multi-Rotation Tracking via Speckle Imaging
Oct 08, 2024
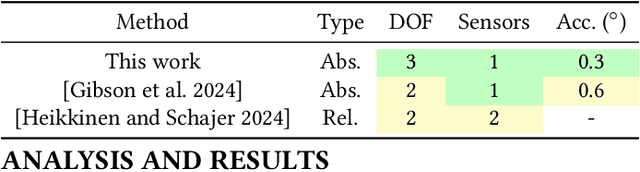
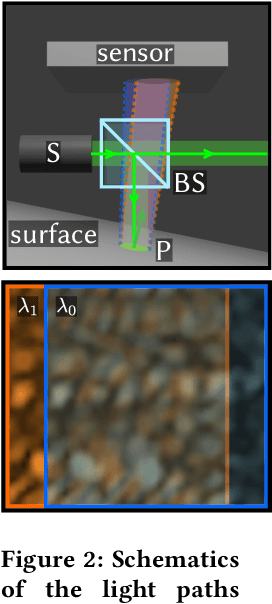
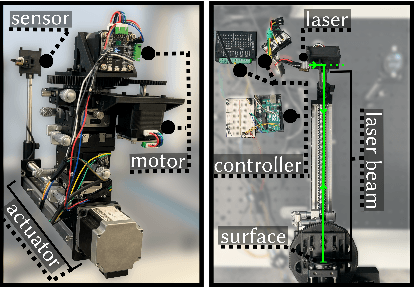
Precision pose detection is increasingly demanded in fields such as personal fabrication, Virtual Reality (VR), and robotics due to its critical role in ensuring accurate positioning information. However, conventional vision-based systems used in these systems often struggle with achieving high precision and accuracy, particularly when dealing with complex environments or fast-moving objects. To address these limitations, we investigate Laser Speckle Imaging (LSI), an emerging optical tracking method that offers promising potential for improving pose estimation accuracy. Specifically, our proposed LSI-Based Tracking (SpecTrack) leverages the captures from a lensless camera and a retro-reflector marker with a coded aperture to achieve multi-axis rotational pose estimation with high precision. Our extensive trials using our in-house built testbed have shown that SpecTrack achieves an accuracy of 0.31{\deg} (std=0.43{\deg}), significantly outperforming state-of-the-art approaches and improving accuracy up to 200%.
Coherent 3D Portrait Video Reconstruction via Triplane Fusion
May 01, 2024


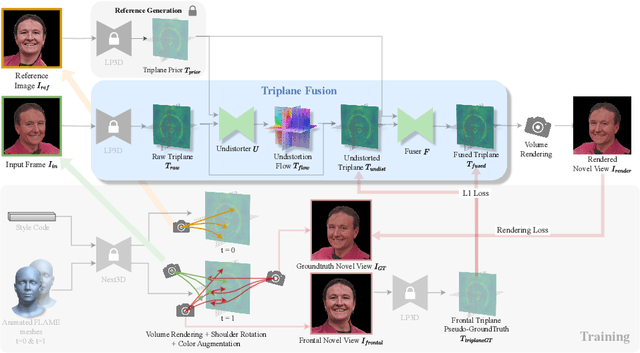
Recent breakthroughs in single-image 3D portrait reconstruction have enabled telepresence systems to stream 3D portrait videos from a single camera in real-time, potentially democratizing telepresence. However, per-frame 3D reconstruction exhibits temporal inconsistency and forgets the user's appearance. On the other hand, self-reenactment methods can render coherent 3D portraits by driving a personalized 3D prior, but fail to faithfully reconstruct the user's per-frame appearance (e.g., facial expressions and lighting). In this work, we recognize the need to maintain both coherent identity and dynamic per-frame appearance to enable the best possible realism. To this end, we propose a new fusion-based method that fuses a personalized 3D subject prior with per-frame information, producing temporally stable 3D videos with faithful reconstruction of the user's per-frame appearances. Trained only using synthetic data produced by an expression-conditioned 3D GAN, our encoder-based method achieves both state-of-the-art 3D reconstruction accuracy and temporal consistency on in-studio and in-the-wild datasets.
Noise-Aware Saliency Prediction for Videos with Incomplete Gaze Data
Apr 16, 2021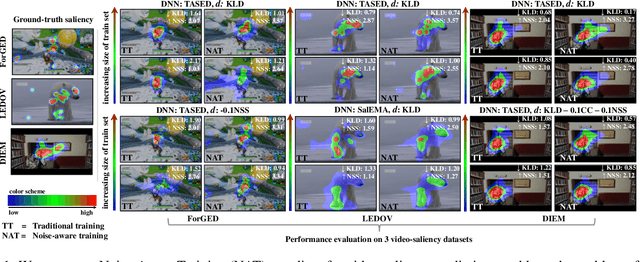
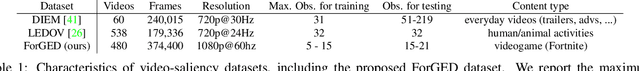
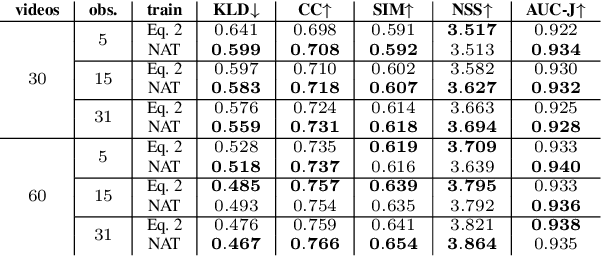

Deep-learning-based algorithms have led to impressive results in visual-saliency prediction, but the impact of noise in training gaze data has been largely overlooked. This issue is especially relevant for videos, where the gaze data tends to be incomplete, and thus noisier, compared to images. Therefore, we propose a noise-aware training (NAT) paradigm for visual-saliency prediction that quantifies the uncertainty arising from gaze data incompleteness and inaccuracy, and accounts for it in training. We demonstrate the advantage of NAT independently of the adopted model architecture, loss function, or training dataset. Given its robustness to the noise in incomplete training datasets, NAT ushers in the possibility of designing gaze datasets with fewer human subjects. We also introduce the first dataset that offers a video-game context for video-saliency research, with rich temporal semantics, and multiple gaze attractors per frame.
SIDOD: A Synthetic Image Dataset for 3D Object Pose Recognition with Distractors
Aug 12, 2020


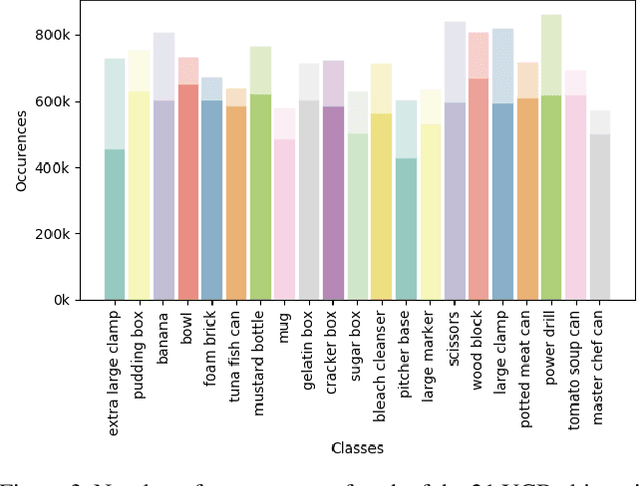
We present a new, publicly-available image dataset generated by the NVIDIA Deep Learning Data Synthesizer intended for use in object detection, pose estimation, and tracking applications. This dataset contains 144k stereo image pairs that synthetically combine 18 camera viewpoints of three photorealistic virtual environments with up to 10 objects (chosen randomly from the 21 object models of the YCB dataset [1]) and flying distractors. Object and camera pose, scene lighting, and quantity of objects and distractors were randomized. Each provided view includes RGB, depth, segmentation, and surface normal images, all pixel level. We describe our approach for domain randomization and provide insight into the decisions that produced the dataset.
Toward Standardized Classification of Foveated Displays
May 03, 2019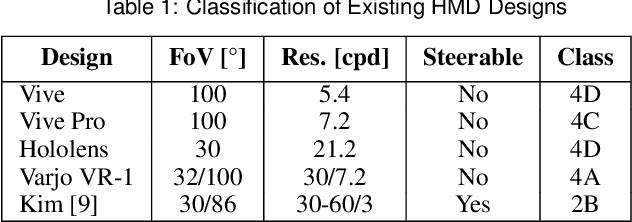
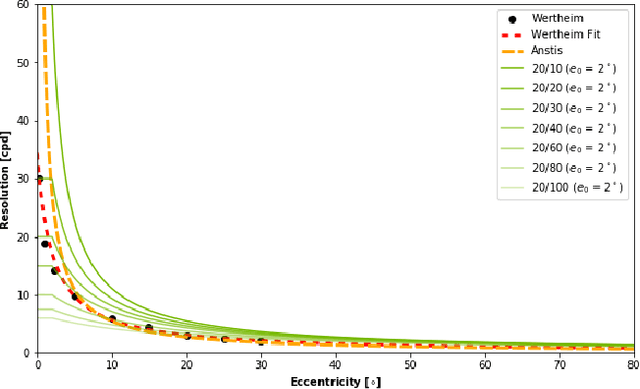
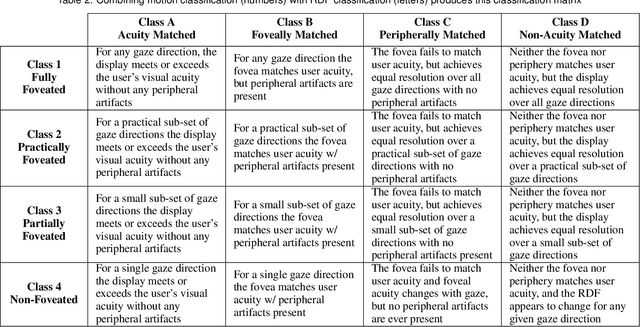

Emergent in the field of head mounted display design is a desire to leverage the limitations of the human visual system to reduce the computation, communication, and display workload in power and form-factor constrained systems. Fundamental to this reduced workload is the ability to match display resolution to the acuity of the human visual system, along with a resulting need to follow the gaze of the eye as it moves, a process referred to as foveation. A display that moves its content along with the eye may be called a Foveated Display, though this term is also commonly used to describe displays with non-uniform resolution that attempt to mimic human visual acuity. We therefore recommend a definition for the term Foveated Display that accepts both of these interpretations. Furthermore, we include a simplified model for human visual Acuity Distribution Functions (ADFs) at various levels of visual acuity, across wide fields of view and propose comparison of this ADF with the Resolution Distribution Function of a foveated display for evaluation of its resolution at a particular gaze direction. We also provide a taxonomy to allow the field to meaningfully compare and contrast various aspects of foveated displays in a display and optical technology-agnostic manner.
A Deformable Interface for Human Touch Recognition using Stretchable Carbon Nanotube Dielectric Elastomer Sensors and Deep Neural Networks
Mar 24, 2018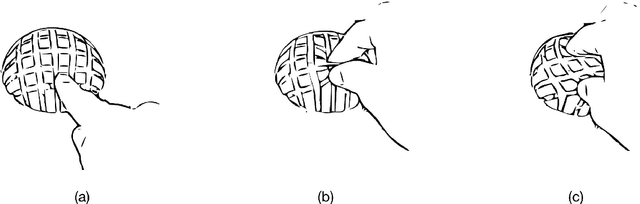
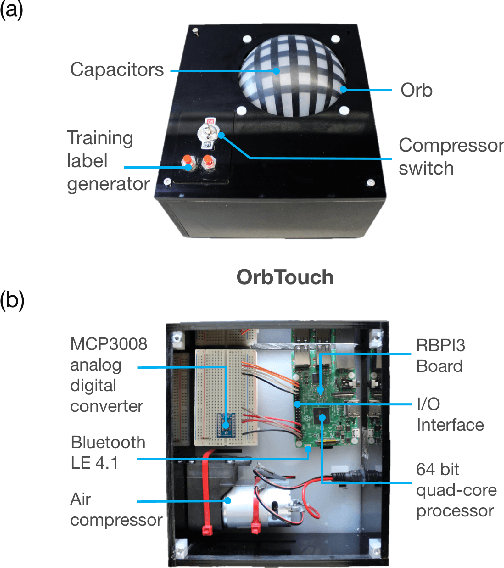
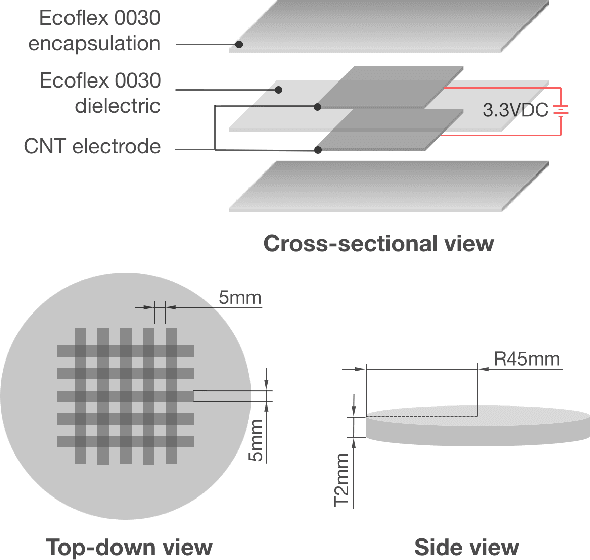
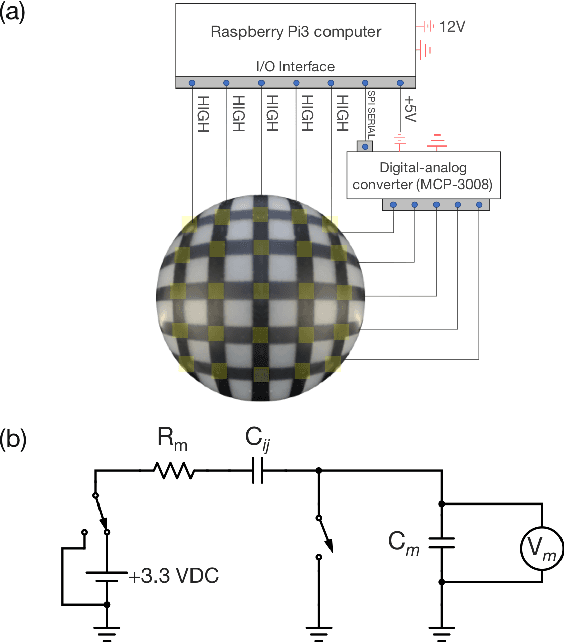
User interfaces provide an interactive window between physical and virtual environments. A new concept in the field of human-computer interaction is a soft user interface; a compliant surface that facilitates touch interaction through deformation. Despite the potential of these interfaces, they currently lack a signal processing framework that can efficiently extract information from their deformation. Here we present OrbTouch, a device that uses statistical learning algorithms, based on convolutional neural networks, to map deformations from human touch to categorical labels (i.e., gestures) and touch location using stretchable capacitor signals as inputs. We demonstrate this approach by using the device to control the popular game Tetris. OrbTouch provides a modular, robust framework to interpret deformation in soft media, laying a foundation for new modes of human computer interaction through shape changing solids.