 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFourier Neural Operators with rank-1 lattice points and hyperbolic cross
Jun 07, 2026The \emph{Fourier neural operator} (FNO) is a neural network architecture that learns mappings between function spaces. Its efficient implementation is based on the multi-dimensional Fourier transform. By deriving general regularity bounds for the FNO with respect to both the spatial and parametric variables, we prove that the generalization error of the FNO can be improved by replacing spatial tensor product grids with purpose-built rank-1 lattice points, and by using a second lattice carefully constructed as training points in the parametric space. We achieve more accurate and efficient approximations from fewer network parameters, fewer spatial points, and fewer training samples. In addition, the architecture is simplified, because the high-dimensional Fourier transform on rank-1 lattices requires only a \emph{one-dimensional fast Fourier transform}, and we can use a \emph{hyperbolic cross} frequency index set with lattice points. We demonstrate the benefits of our \emph{lattice-based hyperbolic-cross FNOs} for an elliptic PDE on the torus.
Lattice-based Deep Neural Networks: Regularity and Tailored Regularization
Mar 03, 2026This survey article is concerned with the application of lattice rules to Deep Neural Networks (DNNs), lattice rules being a family of quasi-Monte Carlo methods. They have demonstrated effectiveness in various contexts for high-dimensional integration and function approximation. They are extremely easy to implement thanks to their very simple formulation -- all that is required is a good integer generating vector of length matching the dimensionality of the problem. In recent years there has been a burst of research activities on the application and theory of DNNs. We review our recent article on using lattice rules as training points for DNNs with a smooth activation function, where we obtained explicit regularity bounds of the DNNs. By imposing restrictions on the network parameters to match the regularity features of the target function, we prove that DNNs with tailored lattice training points can achieve good theoretical generalization error bounds, with implied constants independent of the input dimension. We also demonstrate numerically that DNNs trained with our tailored regularization perform significantly better than with standard $\ell_2$ regularization.
FourCastNet 3: A geometric approach to probabilistic machine-learning weather forecasting at scale
Jul 16, 2025FourCastNet 3 advances global weather modeling by implementing a scalable, geometric machine learning (ML) approach to probabilistic ensemble forecasting. The approach is designed to respect spherical geometry and to accurately model the spatially correlated probabilistic nature of the problem, resulting in stable spectra and realistic dynamics across multiple scales. FourCastNet 3 delivers forecasting accuracy that surpasses leading conventional ensemble models and rivals the best diffusion-based methods, while producing forecasts 8 to 60 times faster than these approaches. In contrast to other ML approaches, FourCastNet 3 demonstrates excellent probabilistic calibration and retains realistic spectra, even at extended lead times of up to 60 days. All of these advances are realized using a purely convolutional neural network architecture tailored for spherical geometry. Scalable and efficient large-scale training on 1024 GPUs and more is enabled by a novel training paradigm for combined model- and data-parallelism, inspired by domain decomposition methods in classical numerical models. Additionally, FourCastNet 3 enables rapid inference on a single GPU, producing a 90-day global forecast at 0.25{\deg}, 6-hourly resolution in under 20 seconds. Its computational efficiency, medium-range probabilistic skill, spectral fidelity, and rollout stability at subseasonal timescales make it a strong candidate for improving meteorological forecasting and early warning systems through large ensemble predictions.
UniRelight: Learning Joint Decomposition and Synthesis for Video Relighting
Jun 18, 2025We address the challenge of relighting a single image or video, a task that demands precise scene intrinsic understanding and high-quality light transport synthesis. Existing end-to-end relighting models are often limited by the scarcity of paired multi-illumination data, restricting their ability to generalize across diverse scenes. Conversely, two-stage pipelines that combine inverse and forward rendering can mitigate data requirements but are susceptible to error accumulation and often fail to produce realistic outputs under complex lighting conditions or with sophisticated materials. In this work, we introduce a general-purpose approach that jointly estimates albedo and synthesizes relit outputs in a single pass, harnessing the generative capabilities of video diffusion models. This joint formulation enhances implicit scene comprehension and facilitates the creation of realistic lighting effects and intricate material interactions, such as shadows, reflections, and transparency. Trained on synthetic multi-illumination data and extensive automatically labeled real-world videos, our model demonstrates strong generalization across diverse domains and surpasses previous methods in both visual fidelity and temporal consistency.
Sionna RT: Technical Report
Apr 30, 2025Sionna is an open-source, GPU-accelerated library that, as of version 0.14, incorporates a ray tracer for simulating radio wave propagation. A unique feature of Sionna RT is differentiability, enabling the calculation of gradients for the channel impulse responses (CIRs), radio maps, and other related metrics with respect to system and environmental parameters, such as material properties, antenna patterns, and array geometries. The release of Sionna 1.0 provides a complete overhaul of the ray tracer, significantly improving its speed, memory efficiency, and extensibility. This document details the algorithms employed by Sionna RT to simulate radio wave propagation efficiently, while also addressing their current limitations. Given that the computation of CIRs and radio maps requires distinct algorithms, these are detailed in separate sections. For CIRs, Sionna RT integrates shooting and bouncing of rays (SBR) with the image method and uses a hashing-based mechanism to efficiently eliminate duplicate paths. Radio maps are computed using a purely SBR-based approach.
GEN3C: 3D-Informed World-Consistent Video Generation with Precise Camera Control
Mar 05, 2025We present GEN3C, a generative video model with precise Camera Control and temporal 3D Consistency. Prior video models already generate realistic videos, but they tend to leverage little 3D information, leading to inconsistencies, such as objects popping in and out of existence. Camera control, if implemented at all, is imprecise, because camera parameters are mere inputs to the neural network which must then infer how the video depends on the camera. In contrast, GEN3C is guided by a 3D cache: point clouds obtained by predicting the pixel-wise depth of seed images or previously generated frames. When generating the next frames, GEN3C is conditioned on the 2D renderings of the 3D cache with the new camera trajectory provided by the user. Crucially, this means that GEN3C neither has to remember what it previously generated nor does it have to infer the image structure from the camera pose. The model, instead, can focus all its generative power on previously unobserved regions, as well as advancing the scene state to the next frame. Our results demonstrate more precise camera control than prior work, as well as state-of-the-art results in sparse-view novel view synthesis, even in challenging settings such as driving scenes and monocular dynamic video. Results are best viewed in videos. Check out our webpage! https://research.nvidia.com/labs/toronto-ai/GEN3C/
DiffusionRenderer: Neural Inverse and Forward Rendering with Video Diffusion Models
Jan 30, 2025



Understanding and modeling lighting effects are fundamental tasks in computer vision and graphics. Classic physically-based rendering (PBR) accurately simulates the light transport, but relies on precise scene representations--explicit 3D geometry, high-quality material properties, and lighting conditions--that are often impractical to obtain in real-world scenarios. Therefore, we introduce DiffusionRenderer, a neural approach that addresses the dual problem of inverse and forward rendering within a holistic framework. Leveraging powerful video diffusion model priors, the inverse rendering model accurately estimates G-buffers from real-world videos, providing an interface for image editing tasks, and training data for the rendering model. Conversely, our rendering model generates photorealistic images from G-buffers without explicit light transport simulation. Experiments demonstrate that DiffusionRenderer effectively approximates inverse and forwards rendering, consistently outperforming the state-of-the-art. Our model enables practical applications from a single video input--including relighting, material editing, and realistic object insertion.
Design of a Standard-Compliant Real-Time Neural Receiver for 5G NR
Sep 04, 2024We detail the steps required to deploy a multi-user multiple-input multiple-output (MU-MIMO) neural receiver (NRX) in an actual cellular communication system. This raises several exciting research challenges, including the need for real-time inference and compatibility with the 5G NR standard. As the network configuration in a practical setup can change dynamically within milliseconds, we propose an adaptive NRX architecture capable of supporting dynamic modulation and coding scheme (MCS) configurations without the need for any re-training and without additional inference cost. We optimize the latency of the neural network (NN) architecture to achieve inference times of less than 1ms on an NVIDIA A100 GPU using the TensorRT inference library. These latency constraints effectively limit the size of the NN and we quantify the resulting signal-to-noise ratio (SNR) degradation as less than 0.7 dB when compared to a preliminary non-real-time NRX architecture. Finally, we explore the potential for site-specific adaptation of the receiver by investigating the required size of the training dataset and the number of fine-tuning iterations to optimize the NRX for specific radio environments using a ray tracing-based channel model. The resulting NRX is ready for deployment in a real-time 5G NR system and the source code including the TensorRT experiments is available online.
Compact Neural Graphics Primitives with Learned Hash Probing
Dec 28, 2023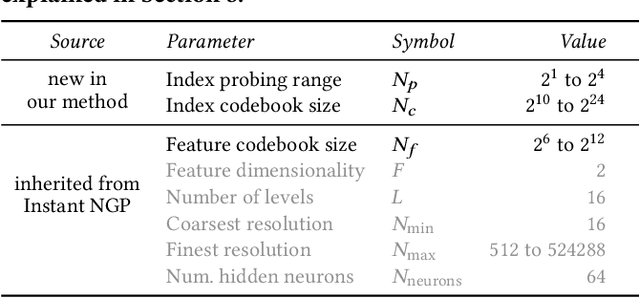



Neural graphics primitives are faster and achieve higher quality when their neural networks are augmented by spatial data structures that hold trainable features arranged in a grid. However, existing feature grids either come with a large memory footprint (dense or factorized grids, trees, and hash tables) or slow performance (index learning and vector quantization). In this paper, we show that a hash table with learned probes has neither disadvantage, resulting in a favorable combination of size and speed. Inference is faster than unprobed hash tables at equal quality while training is only 1.2-2.6x slower, significantly outperforming prior index learning approaches. We arrive at this formulation by casting all feature grids into a common framework: they each correspond to a lookup function that indexes into a table of feature vectors. In this framework, the lookup functions of existing data structures can be combined by simple arithmetic combinations of their indices, resulting in Pareto optimal compression and speed.
Learning Radio Environments by Differentiable Ray Tracing
Nov 30, 2023



Ray tracing (RT) is instrumental in 6G research in order to generate spatially-consistent and environment-specific channel impulse responses (CIRs). While acquiring accurate scene geometries is now relatively straightforward, determining material characteristics requires precise calibration using channel measurements. We therefore introduce a novel gradient-based calibration method, complemented by differentiable parametrizations of material properties, scattering and antenna patterns. Our method seamlessly integrates with differentiable ray tracers that enable the computation of derivatives of CIRs with respect to these parameters. Essentially, we approach field computation as a large computational graph wherein parameters are trainable akin to weights of a neural network (NN). We have validated our method using both synthetic data and real-world indoor channel measurements, employing a distributed multiple-input multiple-output (MIMO) channel sounder.