 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePower Foam: Unifying Real-Time Differentiable Ray Tracing and Rasterization
Apr 27, 2026We introduce a differentiable 3D representation that unifies the ray tracing capabilities of foam-based ray tracing with the efficiency of modern rasterization pipelines. While prior foam representations enable constant-time ray traversal through an explicit volumetric partition of space, their potentially unbounded cells hinder efficient tile-based rasterization. We address this limitation by generalizing Voronoi foams to bounded power diagrams with controllable cell extents, enabling spatially bounded primitives without requiring expensive Delaunay triangulations during training. We further introduce an oriented surface formulation that explicitly models interfaces between interior and exterior regions, and decouple geometry from appearance by embedding differentiable texture directly on these surfaces. Together, these contributions yield a representation that preserves state-of-the-art ray tracing efficiency while achieving rasterization performance competitive with current generation 3DGS, providing a practical path toward unified real-time differentiable rendering.
NoKSR: Kernel-Free Neural Surface Reconstruction via Point Cloud Serialization
Feb 19, 2025We present a novel approach to large-scale point cloud surface reconstruction by developing an efficient framework that converts an irregular point cloud into a signed distance field (SDF). Our backbone builds upon recent transformer-based architectures (i.e., PointTransformerV3), that serializes the point cloud into a locality-preserving sequence of tokens. We efficiently predict the SDF value at a point by aggregating nearby tokens, where fast approximate neighbors can be retrieved thanks to the serialization. We serialize the point cloud at different levels/scales, and non-linearly aggregate a feature to predict the SDF value. We show that aggregating across multiple scales is critical to overcome the approximations introduced by the serialization (i.e. false negatives in the neighborhood). Our frameworks sets the new state-of-the-art in terms of accuracy and efficiency (better or similar performance with half the latency of the best prior method, coupled with a simpler implementation), particularly on outdoor datasets where sparse-grid methods have shown limited performance.
Radiant Foam: Real-Time Differentiable Ray Tracing
Feb 03, 2025



Research on differentiable scene representations is consistently moving towards more efficient, real-time models. Recently, this has led to the popularization of splatting methods, which eschew the traditional ray-based rendering of radiance fields in favor of rasterization. This has yielded a significant improvement in rendering speeds due to the efficiency of rasterization algorithms and hardware, but has come at a cost: the approximations that make rasterization efficient also make implementation of light transport phenomena like reflection and refraction much more difficult. We propose a novel scene representation which avoids these approximations, but keeps the efficiency and reconstruction quality of splatting by leveraging a decades-old efficient volumetric mesh ray tracing algorithm which has been largely overlooked in recent computer vision research. The resulting model, which we name Radiant Foam, achieves rendering speed and quality comparable to Gaussian Splatting, without the constraints of rasterization. Unlike ray traced Gaussian models that use hardware ray tracing acceleration, our method requires no special hardware or APIs beyond the standard features of a programmable GPU.
Lagrangian Hashing for Compressed Neural Field Representations
Sep 09, 2024



We present Lagrangian Hashing, a representation for neural fields combining the characteristics of fast training NeRF methods that rely on Eulerian grids (i.e.~InstantNGP), with those that employ points equipped with features as a way to represent information (e.g. 3D Gaussian Splatting or PointNeRF). We achieve this by incorporating a point-based representation into the high-resolution layers of the hierarchical hash tables of an InstantNGP representation. As our points are equipped with a field of influence, our representation can be interpreted as a mixture of Gaussians stored within the hash table. We propose a loss that encourages the movement of our Gaussians towards regions that require more representation budget to be sufficiently well represented. Our main finding is that our representation allows the reconstruction of signals using a more compact representation without compromising quality.
Stereo-Knowledge Distillation from dpMV to Dual Pixels for Light Field Video Reconstruction
May 20, 2024Dual pixels contain disparity cues arising from the defocus blur. This disparity information is useful for many vision tasks ranging from autonomous driving to 3D creative realism. However, directly estimating disparity from dual pixels is less accurate. This work hypothesizes that distilling high-precision dark stereo knowledge, implicitly or explicitly, to efficient dual-pixel student networks enables faithful reconstructions. This dark knowledge distillation should also alleviate stereo-synchronization setup and calibration costs while dramatically increasing parameter and inference time efficiency. We collect the first and largest 3-view dual-pixel video dataset, dpMV, to validate our explicit dark knowledge distillation hypothesis. We show that these methods outperform purely monocular solutions, especially in challenging foreground-background separation regions using faithful guidance from dual pixels. Finally, we demonstrate an unconventional use case unlocked by dpMV and implicit dark knowledge distillation from an ensemble of teachers for Light Field (LF) video reconstruction. Our LF video reconstruction method is the fastest and most temporally consistent to date. It remains competitive in reconstruction fidelity while offering many other essential properties like high parameter efficiency, implicit disocclusion handling, zero-shot cross-dataset transfer, geometrically consistent inference on higher spatial-angular resolutions, and adaptive baseline control. All source code is available at the anonymous repository https://github.com/Aryan-Garg.
BANF: Band-limited Neural Fields for Levels of Detail Reconstruction
Apr 19, 2024



Largely due to their implicit nature, neural fields lack a direct mechanism for filtering, as Fourier analysis from discrete signal processing is not directly applicable to these representations. Effective filtering of neural fields is critical to enable level-of-detail processing in downstream applications, and support operations that involve sampling the field on regular grids (e.g. marching cubes). Existing methods that attempt to decompose neural fields in the frequency domain either resort to heuristics or require extensive modifications to the neural field architecture. We show that via a simple modification, one can obtain neural fields that are low-pass filtered, and in turn show how this can be exploited to obtain a frequency decomposition of the entire signal. We demonstrate the validity of our technique by investigating level-of-detail reconstruction, and showing how coarser representations can be computed effectively.
Synthesizing Light Field Video from Monocular Video
Jul 21, 2022
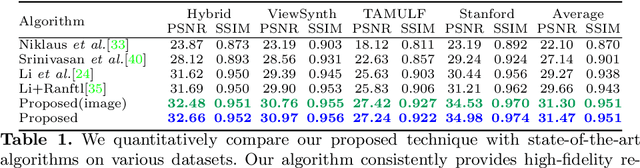


The hardware challenges associated with light-field(LF) imaging has made it difficult for consumers to access its benefits like applications in post-capture focus and aperture control. Learning-based techniques which solve the ill-posed problem of LF reconstruction from sparse (1, 2 or 4) views have significantly reduced the requirement for complex hardware. LF video reconstruction from sparse views poses a special challenge as acquiring ground-truth for training these models is hard. Hence, we propose a self-supervised learning-based algorithm for LF video reconstruction from monocular videos. We use self-supervised geometric, photometric and temporal consistency constraints inspired from a recent self-supervised technique for LF video reconstruction from stereo video. Additionally, we propose three key techniques that are relevant to our monocular video input. We propose an explicit disocclusion handling technique that encourages the network to inpaint disoccluded regions in a LF frame, using information from adjacent input temporal frames. This is crucial for a self-supervised technique as a single input frame does not contain any information about the disoccluded regions. We also propose an adaptive low-rank representation that provides a significant boost in performance by tailoring the representation to each input scene. Finally, we also propose a novel refinement block that is able to exploit the available LF image data using supervised learning to further refine the reconstruction quality. Our qualitative and quantitative analysis demonstrates the significance of each of the proposed building blocks and also the superior results compared to previous state-of-the-art monocular LF reconstruction techniques. We further validate our algorithm by reconstructing LF videos from monocular videos acquired using a commercial GoPro camera.