 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBANF: Band-limited Neural Fields for Levels of Detail Reconstruction
Apr 19, 2024



Largely due to their implicit nature, neural fields lack a direct mechanism for filtering, as Fourier analysis from discrete signal processing is not directly applicable to these representations. Effective filtering of neural fields is critical to enable level-of-detail processing in downstream applications, and support operations that involve sampling the field on regular grids (e.g. marching cubes). Existing methods that attempt to decompose neural fields in the frequency domain either resort to heuristics or require extensive modifications to the neural field architecture. We show that via a simple modification, one can obtain neural fields that are low-pass filtered, and in turn show how this can be exploited to obtain a frequency decomposition of the entire signal. We demonstrate the validity of our technique by investigating level-of-detail reconstruction, and showing how coarser representations can be computed effectively.
Bayes' Rays: Uncertainty Quantification for Neural Radiance Fields
Sep 06, 2023Neural Radiance Fields (NeRFs) have shown promise in applications like view synthesis and depth estimation, but learning from multiview images faces inherent uncertainties. Current methods to quantify them are either heuristic or computationally demanding. We introduce BayesRays, a post-hoc framework to evaluate uncertainty in any pre-trained NeRF without modifying the training process. Our method establishes a volumetric uncertainty field using spatial perturbations and a Bayesian Laplace approximation. We derive our algorithm statistically and show its superior performance in key metrics and applications. Additional results available at: https://bayesrays.github.io.
InterTrack: Interaction Transformer for 3D Multi-Object Tracking
Aug 17, 2022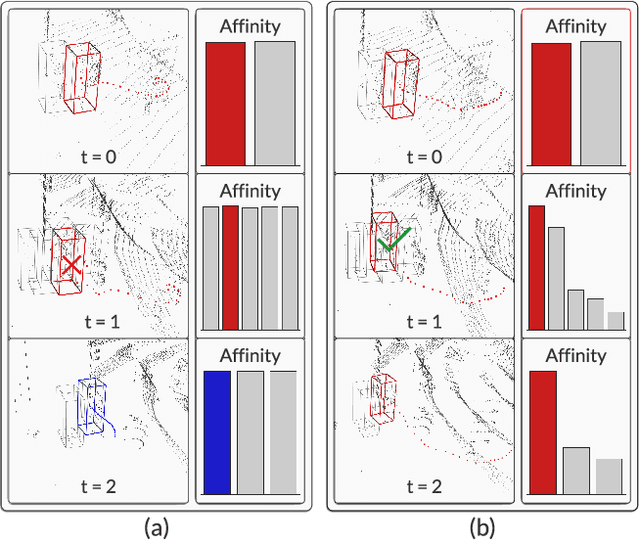
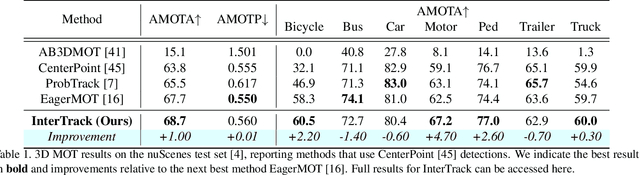
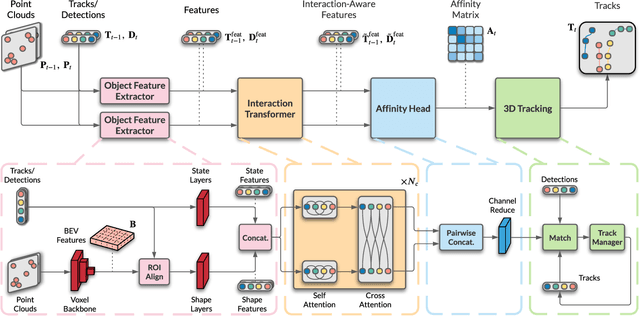
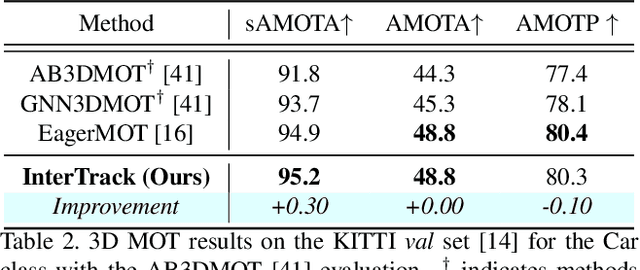
3D multi-object tracking (MOT) is a key problem for autonomous vehicles, required to perform well-informed motion planning in dynamic environments. Particularly for densely occupied scenes, associating existing tracks to new detections remains challenging as existing systems tend to omit critical contextual information. Our proposed solution, InterTrack, introduces the Interaction Transformer for 3D MOT to generate discriminative object representations for data association. We extract state and shape features for each track and detection, and efficiently aggregate global information via attention. We then perform a learned regression on each track/detection feature pair to estimate affinities, and use a robust two-stage data association and track management approach to produce the final tracks. We validate our approach on the nuScenes 3D MOT benchmark, where we observe significant improvements, particularly on classes with small physical sizes and clustered objects. As of submission, InterTrack ranks 1st in overall AMOTA among methods using CenterPoint detections.
Categorical Depth Distribution Network for Monocular 3D Object Detection
Mar 01, 2021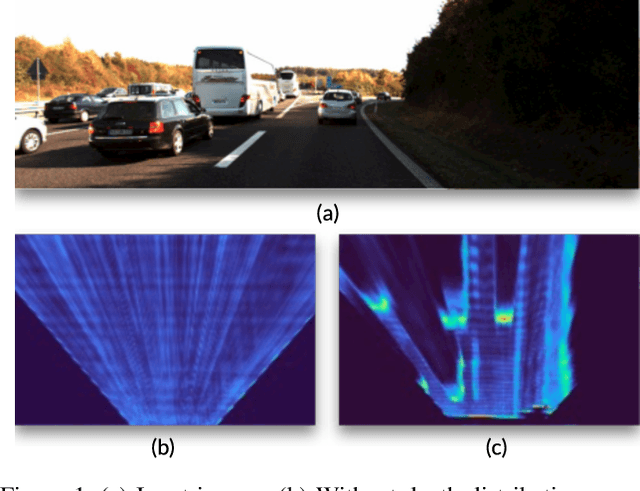
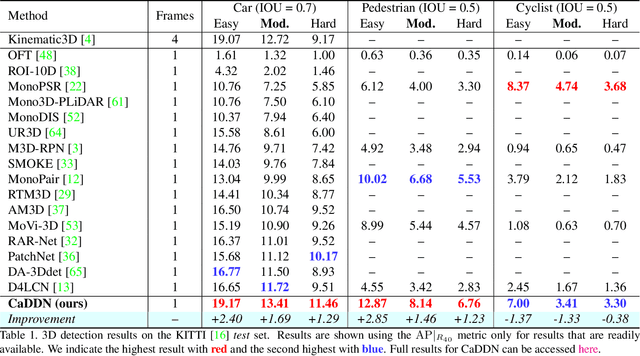
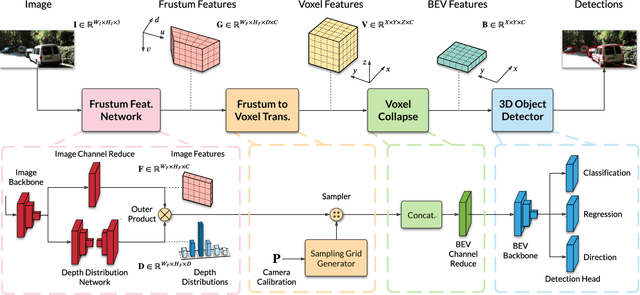
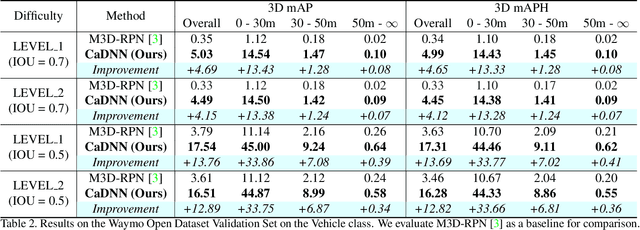
Monocular 3D object detection is a key problem for autonomous vehicles, as it provides a solution with simple configuration compared to typical multi-sensor systems. The main challenge in monocular 3D detection lies in accurately predicting object depth, which must be inferred from object and scene cues due to the lack of direct range measurement. Many methods attempt to directly estimate depth to assist in 3D detection, but show limited performance as a result of depth inaccuracy. Our proposed solution, Categorical Depth Distribution Network (CaDDN), uses a predicted categorical depth distribution for each pixel to project rich contextual feature information to the appropriate depth interval in 3D space. We then use the computationally efficient bird's-eye-view projection and single-stage detector to produce the final output bounding boxes. We design CaDDN as a fully differentiable end-to-end approach for joint depth estimation and object detection. We validate our approach on the KITTI 3D object detection benchmark, where we rank 1st among published monocular methods. We also provide the first monocular 3D detection results on the newly released Waymo Open Dataset. The source code for CaDDN will be made publicly available before publication.
Unlimited Road-scene Synthetic Annotation (URSA) Dataset
Jul 16, 2018
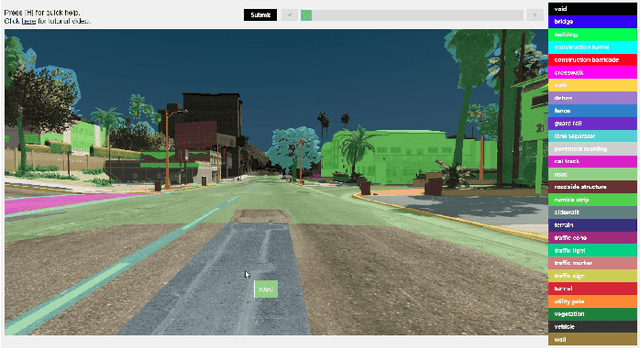

In training deep neural networks for semantic segmentation, the main limiting factor is the low amount of ground truth annotation data that is available in currently existing datasets. The limited availability of such data is due to the time cost and human effort required to accurately and consistently label real images on a pixel level. Modern sandbox video game engines provide open world environments where traffic and pedestrians behave in a pseudo-realistic manner. This caters well to the collection of a believable road-scene dataset. Utilizing open-source tools and resources found in single-player modding communities, we provide a method for persistent, ground truth, asset annotation of a game world. By collecting a synthetic dataset containing upwards of $1,000,000$ images, we demonstrate real-time, on-demand, ground truth data annotation capability of our method. Supplementing this synthetic data to Cityscapes dataset, we show that our data generation method provides qualitative as well as quantitative improvements---for training networks---over previous methods that use video games as surrogate.