 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDPPD: Deformable Polar Polygon Object Detection
Apr 05, 2023Regular object detection methods output rectangle bounding boxes, which are unable to accurately describe the actual object shapes. Instance segmentation methods output pixel-level labels, which are computationally expensive for real-time applications. Therefore, a polygon representation is needed to achieve precise shape alignment, while retaining low computation cost. We develop a novel Deformable Polar Polygon Object Detection method (DPPD) to detect objects in polygon shapes. In particular, our network predicts, for each object, a sparse set of flexible vertices to construct the polygon, where each vertex is represented by a pair of angle and distance in the Polar coordinate system. To enable training, both ground truth and predicted polygons are densely resampled to have the same number of vertices with equal-spaced raypoints. The resampling operation is fully differentable, allowing gradient back-propagation. Sparse polygon predicton ensures high-speed runtime inference while dense resampling allows the network to learn object shapes with high precision. The polygon detection head is established on top of an anchor-free and NMS-free network architecture. DPPD has been demonstrated successfully in various object detection tasks for autonomous driving such as traffic-sign, crosswalk, vehicle and pedestrian objects.
A Hierarchical Deep Architecture and Mini-Batch Selection Method For Joint Traffic Sign and Light Detection
Sep 13, 2018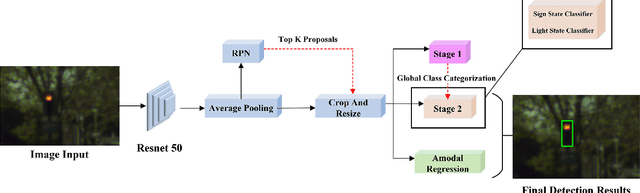



Traffic light and sign detectors on autonomous cars are integral for road scene perception. The literature is abundant with deep learning networks that detect either lights or signs, not both, which makes them unsuitable for real-life deployment due to the limited graphics processing unit (GPU) memory and power available on embedded systems. The root cause of this issue is that no public dataset contains both traffic light and sign labels, which leads to difficulties in developing a joint detection framework. We present a deep hierarchical architecture in conjunction with a mini-batch proposal selection mechanism that allows a network to detect both traffic lights and signs from training on separate traffic light and sign datasets. Our method solves the overlapping issue where instances from one dataset are not labelled in the other dataset. We are the first to present a network that performs joint detection on traffic lights and signs. We measure our network on the Tsinghua-Tencent 100K benchmark for traffic sign detection and the Bosch Small Traffic Lights benchmark for traffic light detection and show it outperforms the existing Bosch Small Traffic light state-of-the-art method. We focus on autonomous car deployment and show our network is more suitable than others because of its low memory footprint and real-time image processing time. Qualitative results can be viewed at https://youtu.be/_YmogPzBXOw
Unlimited Road-scene Synthetic Annotation (URSA) Dataset
Jul 16, 2018
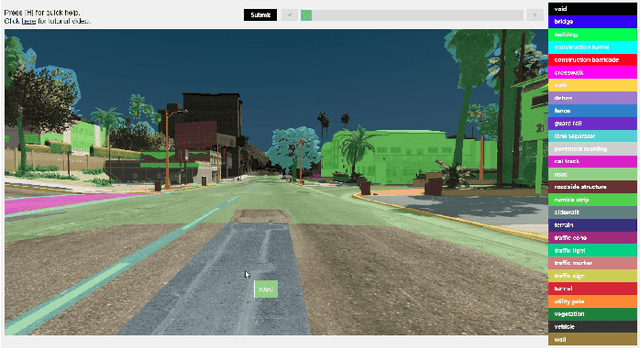

In training deep neural networks for semantic segmentation, the main limiting factor is the low amount of ground truth annotation data that is available in currently existing datasets. The limited availability of such data is due to the time cost and human effort required to accurately and consistently label real images on a pixel level. Modern sandbox video game engines provide open world environments where traffic and pedestrians behave in a pseudo-realistic manner. This caters well to the collection of a believable road-scene dataset. Utilizing open-source tools and resources found in single-player modding communities, we provide a method for persistent, ground truth, asset annotation of a game world. By collecting a synthetic dataset containing upwards of $1,000,000$ images, we demonstrate real-time, on-demand, ground truth data annotation capability of our method. Supplementing this synthetic data to Cityscapes dataset, we show that our data generation method provides qualitative as well as quantitative improvements---for training networks---over previous methods that use video games as surrogate.