 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject-Centric Stereo Matching for 3D Object Detection
Sep 17, 2019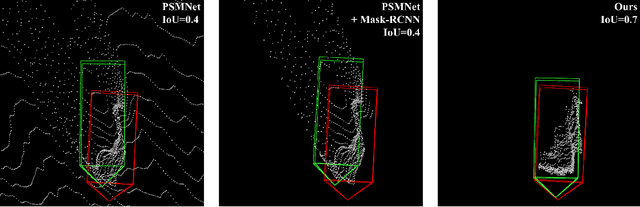
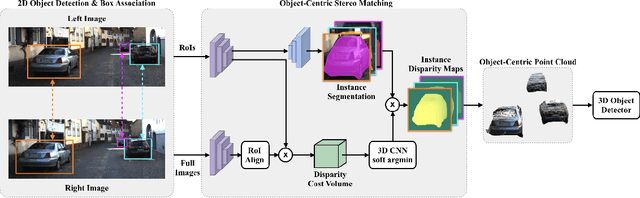


Safe autonomous driving requires reliable 3D object detection-determining the 6 DoF pose and dimensions of objects of interest. Using stereo cameras to solve this task is a cost-effective alternative to the widely used LiDAR sensor. The current state-of-the-art for stereo 3D object detection takes the existing PSMNet stereo matching network, with no modifications, and converts the estimated disparities into a 3D point cloud, and feeds this point cloud into a LiDAR-based 3D object detector. The issue with existing stereo matching networks is that they are designed for disparity estimation, not 3D object detection; the shape and accuracy of object point clouds are not the focus. Stereo matching networks commonly suffer from inaccurate depth estimates at object boundaries, which we define as streaking, because background and foreground points are jointly estimated. Existing networks also penalize disparity instead of the estimated position of object point clouds in their loss functions. We propose a novel 2D box association and object-centric stereo matching method that only estimates the disparities of the objects of interest to address these two issues. Our method achieves state-of-the-art results on the KITTI 3D and BEV benchmarks.
Improving 3D Object Detection for Pedestrians with Virtual Multi-View Synthesis Orientation Estimation
Jul 15, 2019

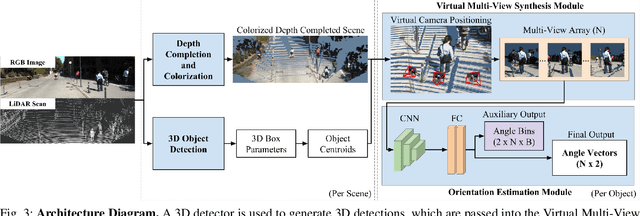

Accurately estimating the orientation of pedestrians is an important and challenging task for autonomous driving because this information is essential for tracking and predicting pedestrian behavior. This paper presents a flexible Virtual Multi-View Synthesis module that can be adopted into 3D object detection methods to improve orientation estimation. The module uses a multi-step process to acquire the fine-grained semantic information required for accurate orientation estimation. First, the scene's point cloud is densified using a structure preserving depth completion algorithm and each point is colorized using its corresponding RGB pixel. Next, virtual cameras are placed around each object in the densified point cloud to generate novel viewpoints, which preserve the object's appearance. We show that this module greatly improves the orientation estimation on the challenging pedestrian class on the KITTI benchmark. When used with the open-source 3D detector AVOD-FPN, we outperform all other published methods on the pedestrian Orientation, 3D, and Bird's Eye View benchmarks.
Monocular 3D Object Detection Leveraging Accurate Proposals and Shape Reconstruction
Apr 02, 2019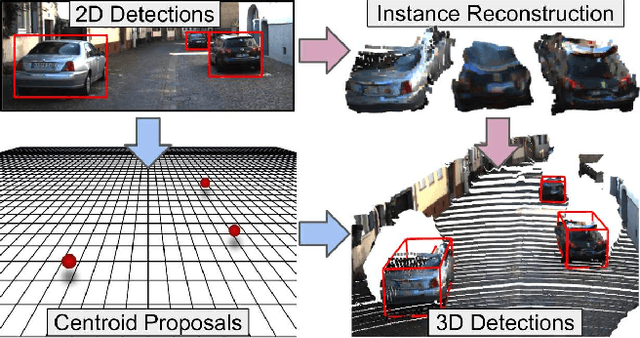
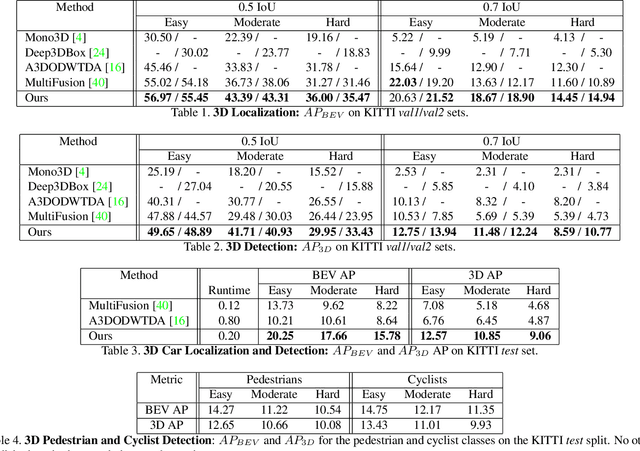
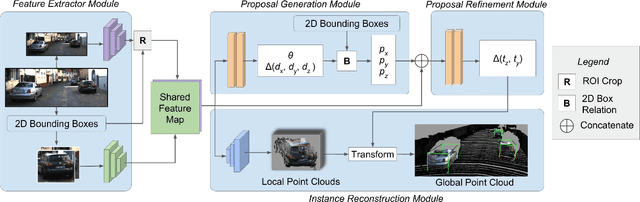
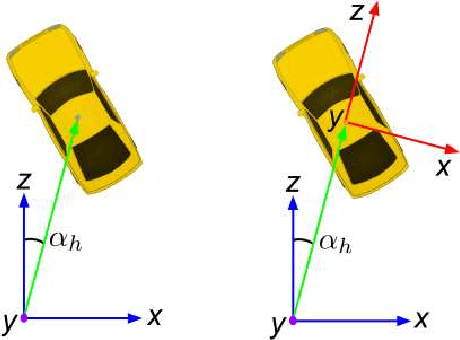
We present MonoPSR, a monocular 3D object detection method that leverages proposals and shape reconstruction. First, using the fundamental relations of a pinhole camera model, detections from a mature 2D object detector are used to generate a 3D proposal per object in a scene. The 3D location of these proposals prove to be quite accurate, which greatly reduces the difficulty of regressing the final 3D bounding box detection. Simultaneously, a point cloud is predicted in an object centered coordinate system to learn local scale and shape information. However, the key challenge is how to exploit shape information to guide 3D localization. As such, we devise aggregate losses, including a novel projection alignment loss, to jointly optimize these tasks in the neural network to improve 3D localization accuracy. We validate our method on the KITTI benchmark where we set new state-of-the-art results among published monocular methods, including the harder pedestrian and cyclist classes, while maintaining efficient run-time.
A Hierarchical Deep Architecture and Mini-Batch Selection Method For Joint Traffic Sign and Light Detection
Sep 13, 2018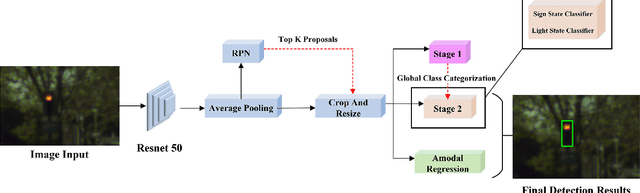



Traffic light and sign detectors on autonomous cars are integral for road scene perception. The literature is abundant with deep learning networks that detect either lights or signs, not both, which makes them unsuitable for real-life deployment due to the limited graphics processing unit (GPU) memory and power available on embedded systems. The root cause of this issue is that no public dataset contains both traffic light and sign labels, which leads to difficulties in developing a joint detection framework. We present a deep hierarchical architecture in conjunction with a mini-batch proposal selection mechanism that allows a network to detect both traffic lights and signs from training on separate traffic light and sign datasets. Our method solves the overlapping issue where instances from one dataset are not labelled in the other dataset. We are the first to present a network that performs joint detection on traffic lights and signs. We measure our network on the Tsinghua-Tencent 100K benchmark for traffic sign detection and the Bosch Small Traffic Lights benchmark for traffic light detection and show it outperforms the existing Bosch Small Traffic light state-of-the-art method. We focus on autonomous car deployment and show our network is more suitable than others because of its low memory footprint and real-time image processing time. Qualitative results can be viewed at https://youtu.be/_YmogPzBXOw