 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Harmonisation for Information Fusion in Digital Healthcare: A State-of-the-Art Systematic Review, Meta-Analysis and Future Research Directions
Jan 17, 2022
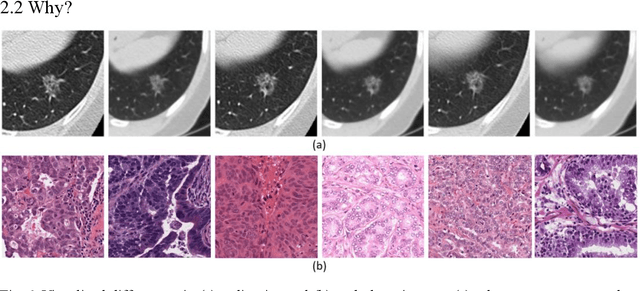

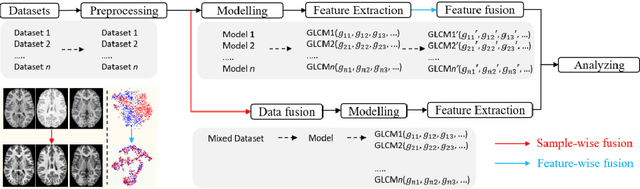
Removing the bias and variance of multicentre data has always been a challenge in large scale digital healthcare studies, which requires the ability to integrate clinical features extracted from data acquired by different scanners and protocols to improve stability and robustness. Previous studies have described various computational approaches to fuse single modality multicentre datasets. However, these surveys rarely focused on evaluation metrics and lacked a checklist for computational data harmonisation studies. In this systematic review, we summarise the computational data harmonisation approaches for multi-modality data in the digital healthcare field, including harmonisation strategies and evaluation metrics based on different theories. In addition, a comprehensive checklist that summarises common practices for data harmonisation studies is proposed to guide researchers to report their research findings more effectively. Last but not least, flowcharts presenting possible ways for methodology and metric selection are proposed and the limitations of different methods have been surveyed for future research.
Federated Learning for Multi-Center Imaging Diagnostics: A Study in Cardiovascular Disease
Jul 07, 2021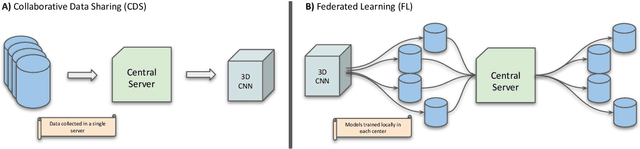



Deep learning models can enable accurate and efficient disease diagnosis, but have thus far been hampered by the data scarcity present in the medical world. Automated diagnosis studies have been constrained by underpowered single-center datasets, and although some results have shown promise, their generalizability to other institutions remains questionable as the data heterogeneity between institutions is not taken into account. By allowing models to be trained in a distributed manner that preserves patients' privacy, federated learning promises to alleviate these issues, by enabling diligent multi-center studies. We present the first federated learning study on the modality of cardiovascular magnetic resonance (CMR) and use four centers derived from subsets of the M\&M and ACDC datasets, focusing on the diagnosis of hypertrophic cardiomyopathy (HCM). We adapt a 3D-CNN network pretrained on action recognition and explore two different ways of incorporating shape prior information to the model, and four different data augmentation set-ups, systematically analyzing their impact on the different collaborative learning choices. We show that despite the small size of data (180 subjects derived from four centers), the privacy preserving federated learning achieves promising results that are competitive with traditional centralized learning. We further find that federatively trained models exhibit increased robustness and are more sensitive to domain shift effects.
Improving 3D Object Detection for Pedestrians with Virtual Multi-View Synthesis Orientation Estimation
Jul 15, 2019

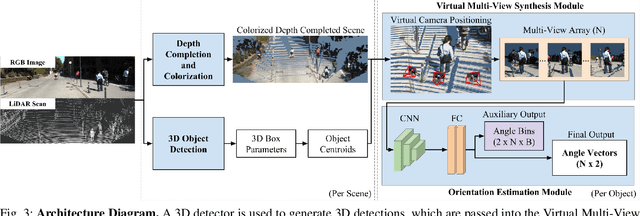

Accurately estimating the orientation of pedestrians is an important and challenging task for autonomous driving because this information is essential for tracking and predicting pedestrian behavior. This paper presents a flexible Virtual Multi-View Synthesis module that can be adopted into 3D object detection methods to improve orientation estimation. The module uses a multi-step process to acquire the fine-grained semantic information required for accurate orientation estimation. First, the scene's point cloud is densified using a structure preserving depth completion algorithm and each point is colorized using its corresponding RGB pixel. Next, virtual cameras are placed around each object in the densified point cloud to generate novel viewpoints, which preserve the object's appearance. We show that this module greatly improves the orientation estimation on the challenging pedestrian class on the KITTI benchmark. When used with the open-source 3D detector AVOD-FPN, we outperform all other published methods on the pedestrian Orientation, 3D, and Bird's Eye View benchmarks.
Leveraging Pre-Trained 3D Object Detection Models For Fast Ground Truth Generation
Jul 16, 2018
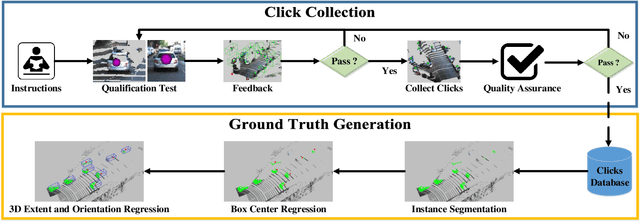
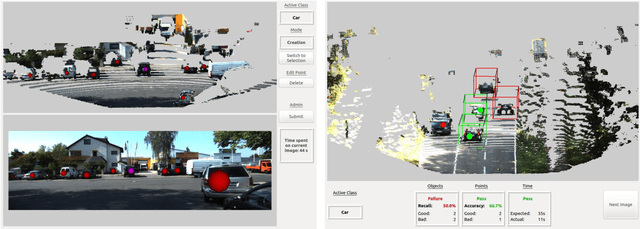
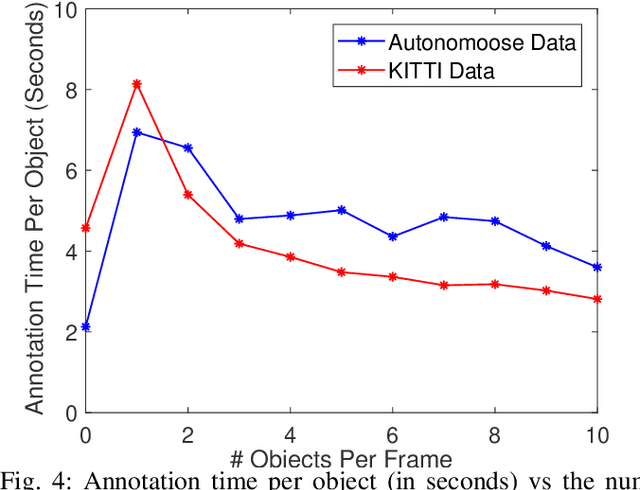
Training 3D object detectors for autonomous driving has been limited to small datasets due to the effort required to generate annotations. Reducing both task complexity and the amount of task switching done by annotators is key to reducing the effort and time required to generate 3D bounding box annotations. This paper introduces a novel ground truth generation method that combines human supervision with pretrained neural networks to generate per-instance 3D point cloud segmentation, 3D bounding boxes, and class annotations. The annotators provide object anchor clicks which behave as a seed to generate instance segmentation results in 3D. The points belonging to each instance are then used to regress object centroids, bounding box dimensions, and object orientation. Our proposed annotation scheme requires 30x lower human annotation time. We use the KITTI 3D object detection dataset to evaluate the efficiency and the quality of our annotation scheme. We also test the the proposed scheme on previously unseen data from the Autonomoose self-driving vehicle to demonstrate generalization capabilities of the network.