 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence Guided Stereo 3D Object Detection with Split Depth Estimation
Mar 11, 2020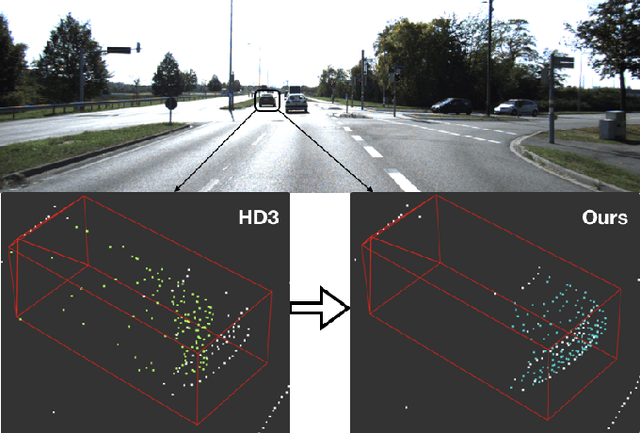
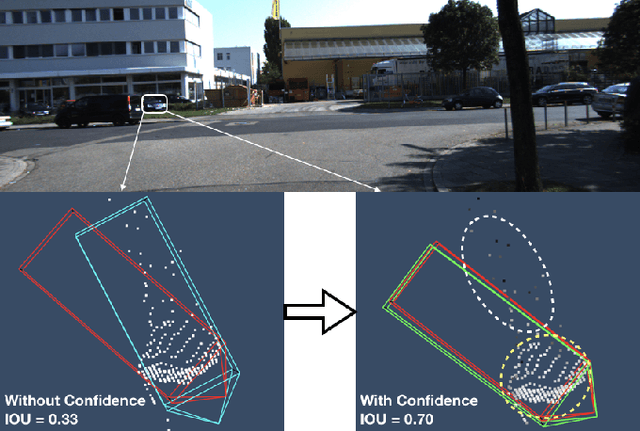
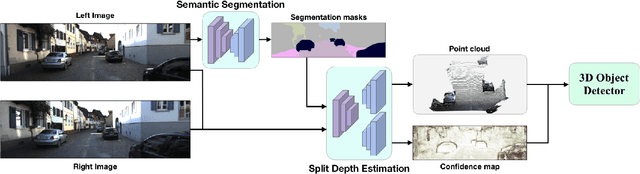
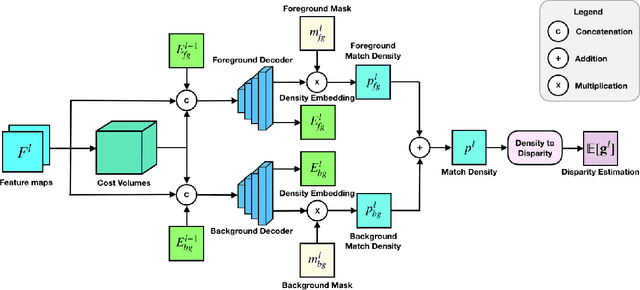
Accurate and reliable 3D object detection is vital to safe autonomous driving. Despite recent developments, the performance gap between stereo-based methods and LiDAR-based methods is still considerable. Accurate depth estimation is crucial to the performance of stereo-based 3D object detection methods, particularly for those pixels associated with objects in the foreground. Moreover, stereo-based methods suffer from high variance in the depth estimation accuracy, which is often not considered in the object detection pipeline. To tackle these two issues, we propose CG-Stereo, a confidence-guided stereo 3D object detection pipeline that uses separate decoders for foreground and background pixels during depth estimation, and leverages the confidence estimation from the depth estimation network as a soft attention mechanism in the 3D object detector. Our approach outperforms all state-of-the-art stereo-based 3D detectors on the KITTI benchmark.
Object-Centric Stereo Matching for 3D Object Detection
Sep 17, 2019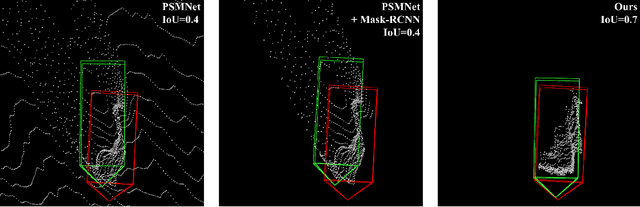
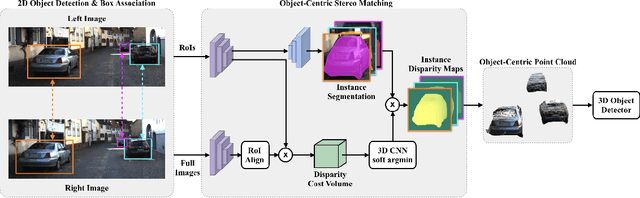


Safe autonomous driving requires reliable 3D object detection-determining the 6 DoF pose and dimensions of objects of interest. Using stereo cameras to solve this task is a cost-effective alternative to the widely used LiDAR sensor. The current state-of-the-art for stereo 3D object detection takes the existing PSMNet stereo matching network, with no modifications, and converts the estimated disparities into a 3D point cloud, and feeds this point cloud into a LiDAR-based 3D object detector. The issue with existing stereo matching networks is that they are designed for disparity estimation, not 3D object detection; the shape and accuracy of object point clouds are not the focus. Stereo matching networks commonly suffer from inaccurate depth estimates at object boundaries, which we define as streaking, because background and foreground points are jointly estimated. Existing networks also penalize disparity instead of the estimated position of object point clouds in their loss functions. We propose a novel 2D box association and object-centric stereo matching method that only estimates the disparities of the objects of interest to address these two issues. Our method achieves state-of-the-art results on the KITTI 3D and BEV benchmarks.
Improving 3D Object Detection for Pedestrians with Virtual Multi-View Synthesis Orientation Estimation
Jul 15, 2019

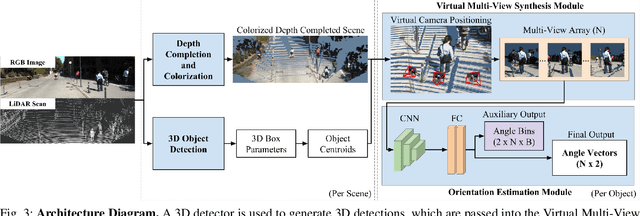

Accurately estimating the orientation of pedestrians is an important and challenging task for autonomous driving because this information is essential for tracking and predicting pedestrian behavior. This paper presents a flexible Virtual Multi-View Synthesis module that can be adopted into 3D object detection methods to improve orientation estimation. The module uses a multi-step process to acquire the fine-grained semantic information required for accurate orientation estimation. First, the scene's point cloud is densified using a structure preserving depth completion algorithm and each point is colorized using its corresponding RGB pixel. Next, virtual cameras are placed around each object in the densified point cloud to generate novel viewpoints, which preserve the object's appearance. We show that this module greatly improves the orientation estimation on the challenging pedestrian class on the KITTI benchmark. When used with the open-source 3D detector AVOD-FPN, we outperform all other published methods on the pedestrian Orientation, 3D, and Bird's Eye View benchmarks.
Monocular 3D Object Detection Leveraging Accurate Proposals and Shape Reconstruction
Apr 02, 2019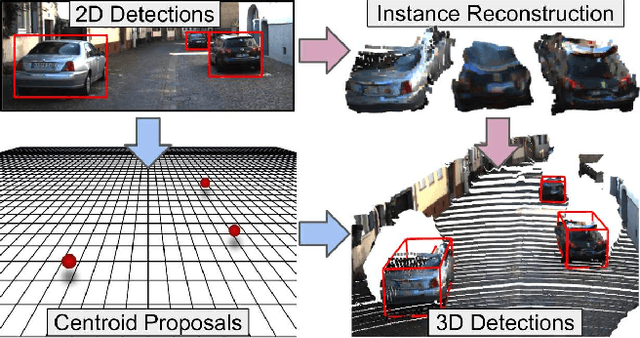
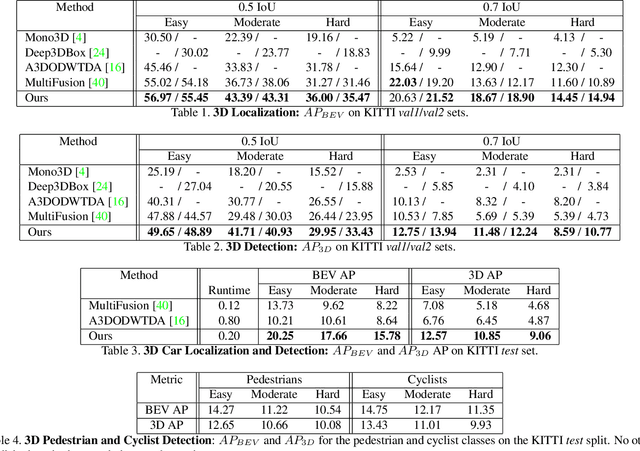
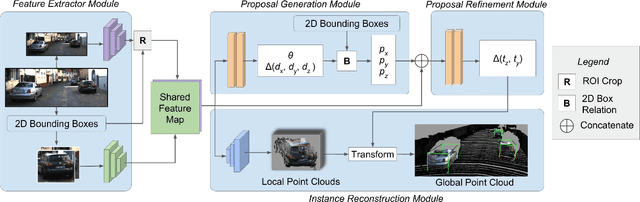
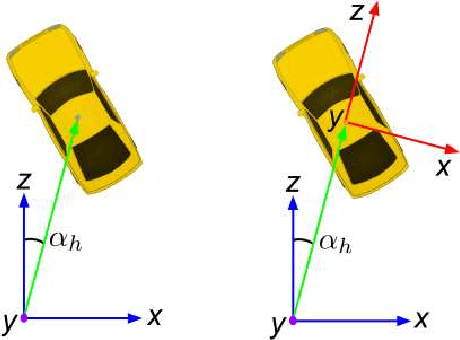
We present MonoPSR, a monocular 3D object detection method that leverages proposals and shape reconstruction. First, using the fundamental relations of a pinhole camera model, detections from a mature 2D object detector are used to generate a 3D proposal per object in a scene. The 3D location of these proposals prove to be quite accurate, which greatly reduces the difficulty of regressing the final 3D bounding box detection. Simultaneously, a point cloud is predicted in an object centered coordinate system to learn local scale and shape information. However, the key challenge is how to exploit shape information to guide 3D localization. As such, we devise aggregate losses, including a novel projection alignment loss, to jointly optimize these tasks in the neural network to improve 3D localization accuracy. We validate our method on the KITTI benchmark where we set new state-of-the-art results among published monocular methods, including the harder pedestrian and cyclist classes, while maintaining efficient run-time.
Joint 3D Proposal Generation and Object Detection from View Aggregation
Jul 12, 2018
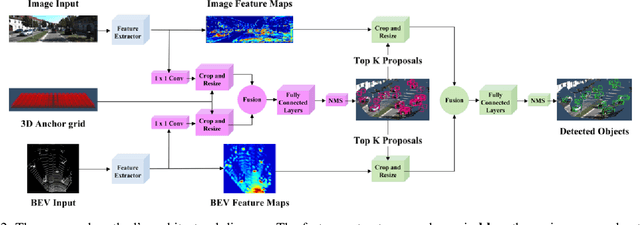
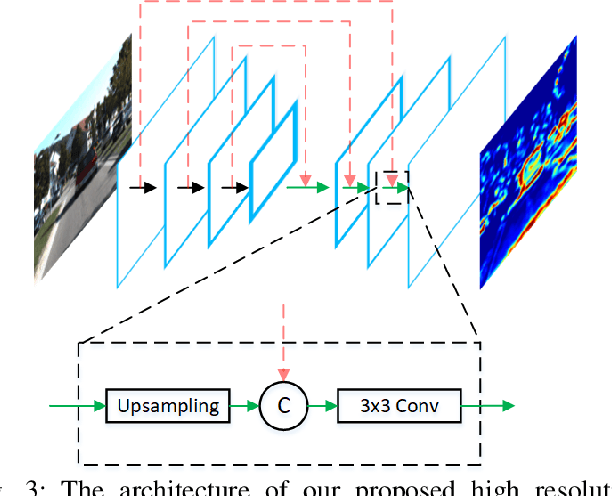
We present AVOD, an Aggregate View Object Detection network for autonomous driving scenarios. The proposed neural network architecture uses LIDAR point clouds and RGB images to generate features that are shared by two subnetworks: a region proposal network (RPN) and a second stage detector network. The proposed RPN uses a novel architecture capable of performing multimodal feature fusion on high resolution feature maps to generate reliable 3D object proposals for multiple object classes in road scenes. Using these proposals, the second stage detection network performs accurate oriented 3D bounding box regression and category classification to predict the extents, orientation, and classification of objects in 3D space. Our proposed architecture is shown to produce state of the art results on the KITTI 3D object detection benchmark while running in real time with a low memory footprint, making it a suitable candidate for deployment on autonomous vehicles. Code is at: https://github.com/kujason/avod
In Defense of Classical Image Processing: Fast Depth Completion on the CPU
Jan 31, 2018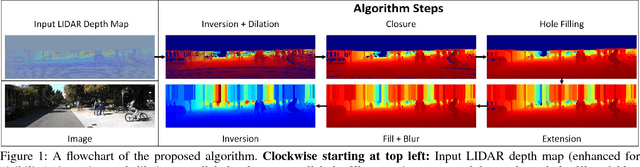

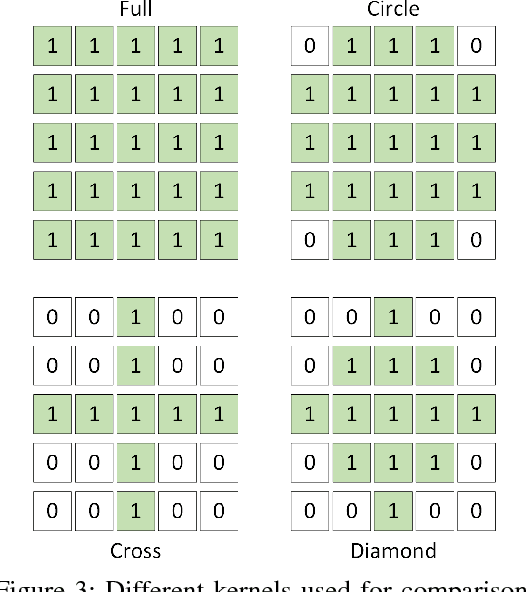
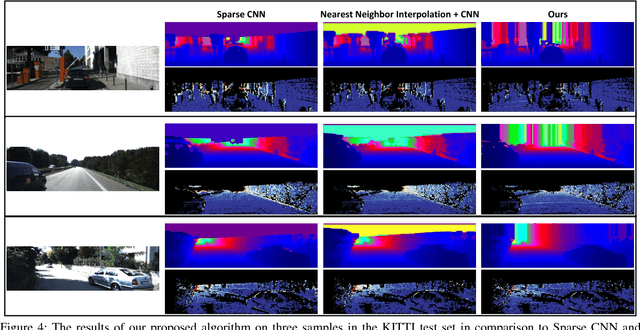
With the rise of data driven deep neural networks as a realization of universal function approximators, most research on computer vision problems has moved away from hand crafted classical image processing algorithms. This paper shows that with a well designed algorithm, we are capable of outperforming neural network based methods on the task of depth completion. The proposed algorithm is simple and fast, runs on the CPU, and relies only on basic image processing operations to perform depth completion of sparse LIDAR depth data. We evaluate our algorithm on the challenging KITTI depth completion benchmark, and at the time of submission, our method ranks first on the KITTI test server among all published methods. Furthermore, our algorithm is data independent, requiring no training data to perform the task at hand. The code written in Python will be made publicly available at https://github.com/kujason/ip_basic.