 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage-to-Lidar Relational Distillation for Autonomous Driving Data
Sep 01, 2024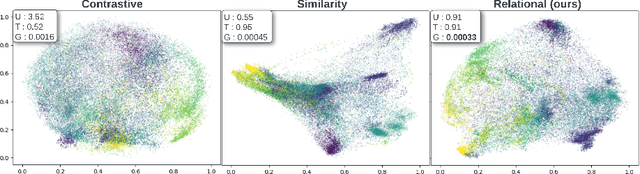

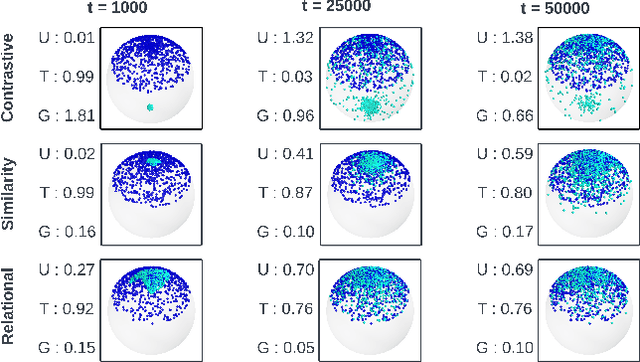
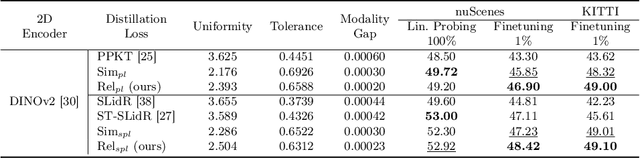
Pre-trained on extensive and diverse multi-modal datasets, 2D foundation models excel at addressing 2D tasks with little or no downstream supervision, owing to their robust representations. The emergence of 2D-to-3D distillation frameworks has extended these capabilities to 3D models. However, distilling 3D representations for autonomous driving datasets presents challenges like self-similarity, class imbalance, and point cloud sparsity, hindering the effectiveness of contrastive distillation, especially in zero-shot learning contexts. Whereas other methodologies, such as similarity-based distillation, enhance zero-shot performance, they tend to yield less discriminative representations, diminishing few-shot performance. We investigate the gap in structure between the 2D and the 3D representations that result from state-of-the-art distillation frameworks and reveal a significant mismatch between the two. Additionally, we demonstrate that the observed structural gap is negatively correlated with the efficacy of the distilled representations on zero-shot and few-shot 3D semantic segmentation. To bridge this gap, we propose a relational distillation framework enforcing intra-modal and cross-modal constraints, resulting in distilled 3D representations that closely capture the structure of the 2D representation. This alignment significantly enhances 3D representation performance over those learned through contrastive distillation in zero-shot segmentation tasks. Furthermore, our relational loss consistently improves the quality of 3D representations in both in-distribution and out-of-distribution few-shot segmentation tasks, outperforming approaches that rely on the similarity loss.
BACS: Background Aware Continual Semantic Segmentation
Apr 19, 2024



Semantic segmentation plays a crucial role in enabling comprehensive scene understanding for robotic systems. However, generating annotations is challenging, requiring labels for every pixel in an image. In scenarios like autonomous driving, there's a need to progressively incorporate new classes as the operating environment of the deployed agent becomes more complex. For enhanced annotation efficiency, ideally, only pixels belonging to new classes would be annotated. This approach is known as Continual Semantic Segmentation (CSS). Besides the common problem of classical catastrophic forgetting in the continual learning setting, CSS suffers from the inherent ambiguity of the background, a phenomenon we refer to as the "background shift'', since pixels labeled as background could correspond to future classes (forward background shift) or previous classes (backward background shift). As a result, continual learning approaches tend to fail. This paper proposes a Backward Background Shift Detector (BACS) to detect previously observed classes based on their distance in the latent space from the foreground centroids of previous steps. Moreover, we propose a modified version of the cross-entropy loss function, incorporating the BACS detector to down-weight background pixels associated with formerly observed classes. To combat catastrophic forgetting, we employ masked feature distillation alongside dark experience replay. Additionally, our approach includes a transformer decoder capable of adjusting to new classes without necessitating an additional classification head. We validate BACS's superior performance over existing state-of-the-art methods on standard CSS benchmarks.
Self-Supervised Image-to-Point Distillation via Semantically Tolerant Contrastive Loss
Jan 12, 2023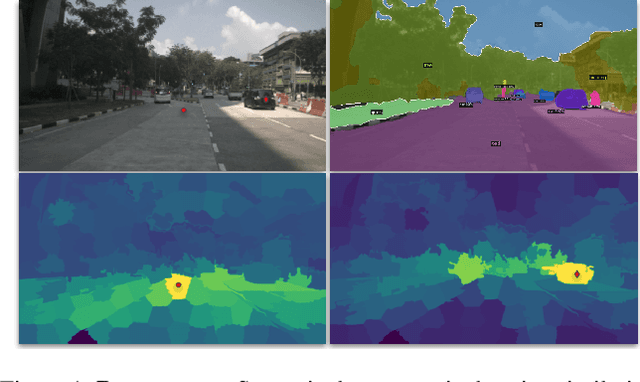
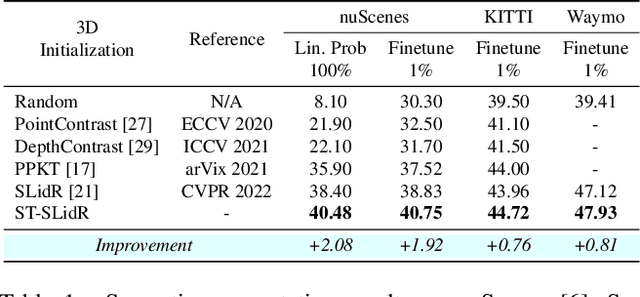

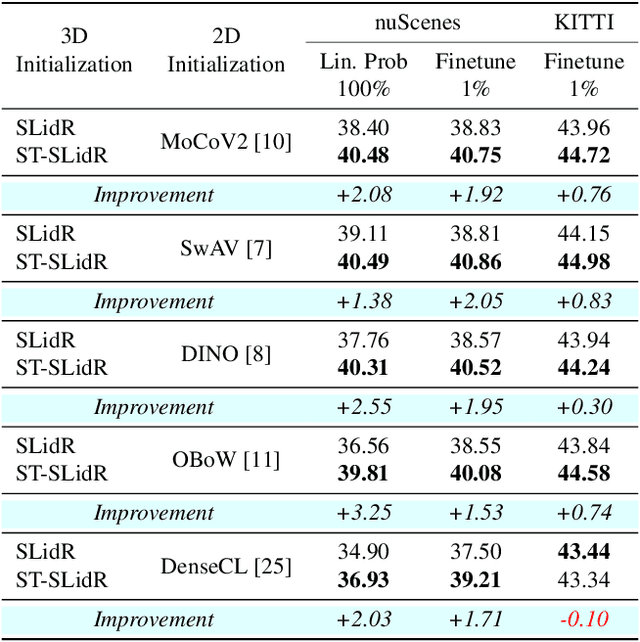
An effective framework for learning 3D representations for perception tasks is distilling rich self-supervised image features via contrastive learning. However, image-to point representation learning for autonomous driving datasets faces two main challenges: 1) the abundance of self-similarity, which results in the contrastive losses pushing away semantically similar point and image regions and thus disturbing the local semantic structure of the learned representations, and 2) severe class imbalance as pretraining gets dominated by over-represented classes. We propose to alleviate the self-similarity problem through a novel semantically tolerant image-to-point contrastive loss that takes into consideration the semantic distance between positive and negative image regions to minimize contrasting semantically similar point and image regions. Additionally, we address class imbalance by designing a class-agnostic balanced loss that approximates the degree of class imbalance through an aggregate sample-to-samples semantic similarity measure. We demonstrate that our semantically-tolerant contrastive loss with class balancing improves state-of-the art 2D-to-3D representation learning in all evaluation settings on 3D semantic segmentation. Our method consistently outperforms state-of-the-art 2D-to-3D representation learning frameworks across a wide range of 2D self-supervised pretrained models.
Estimating Regression Predictive Distributions with Sample Networks
Nov 24, 2022Estimating the uncertainty in deep neural network predictions is crucial for many real-world applications. A common approach to model uncertainty is to choose a parametric distribution and fit the data to it using maximum likelihood estimation. The chosen parametric form can be a poor fit to the data-generating distribution, resulting in unreliable uncertainty estimates. In this work, we propose SampleNet, a flexible and scalable architecture for modeling uncertainty that avoids specifying a parametric form on the output distribution. SampleNets do so by defining an empirical distribution using samples that are learned with the Energy Score and regularized with the Sinkhorn Divergence. SampleNets are shown to be able to well-fit a wide range of distributions and to outperform baselines on large-scale real-world regression tasks.
Bayesian Embeddings for Few-Shot Open World Recognition
Jul 29, 2021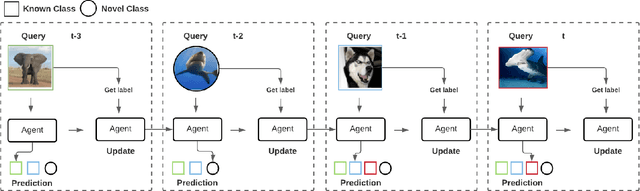
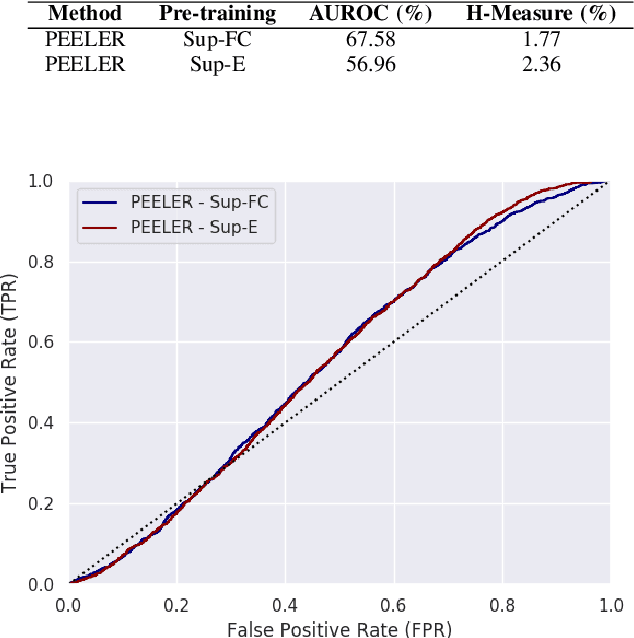
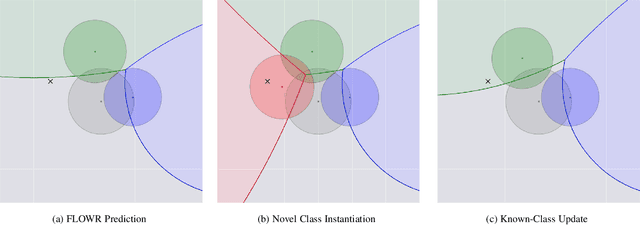
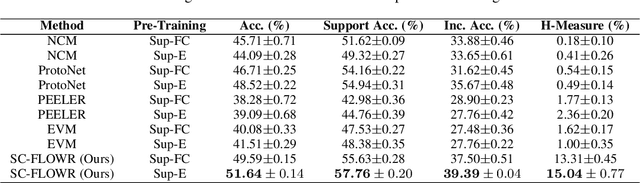
As autonomous decision-making agents move from narrow operating environments to unstructured worlds, learning systems must move from a closed-world formulation to an open-world and few-shot setting in which agents continuously learn new classes from small amounts of information. This stands in stark contrast to modern machine learning systems that are typically designed with a known set of classes and a large number of examples for each class. In this work we extend embedding-based few-shot learning algorithms to the open-world recognition setting. We combine Bayesian non-parametric class priors with an embedding-based pre-training scheme to yield a highly flexible framework which we refer to as few-shot learning for open world recognition (FLOWR). We benchmark our framework on open-world extensions of the common MiniImageNet and TieredImageNet few-shot learning datasets. Our results show, compared to prior methods, strong classification accuracy performance and up to a 12% improvement in H-measure (a measure of novel class detection) from our non-parametric open-world few-shot learning scheme.
Categorical Depth Distribution Network for Monocular 3D Object Detection
Mar 01, 2021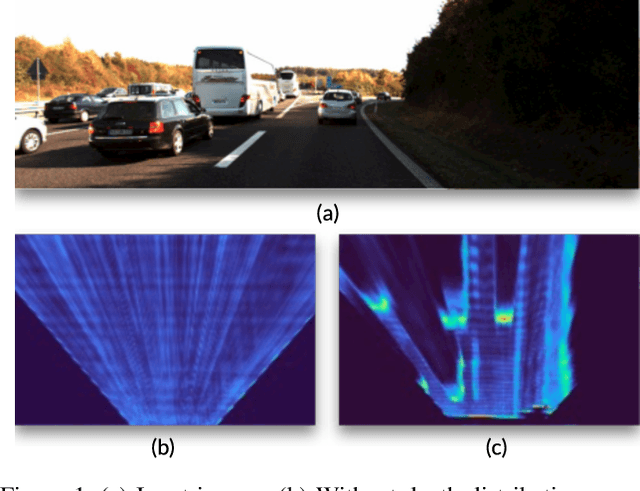
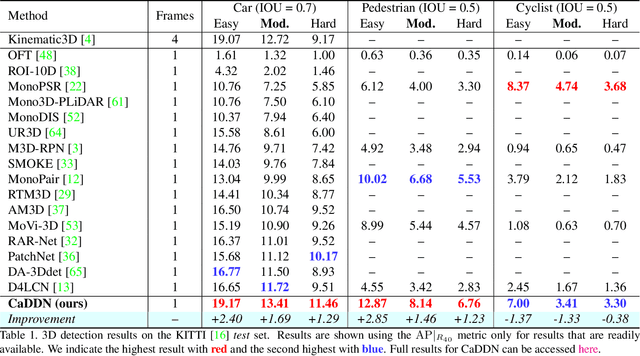
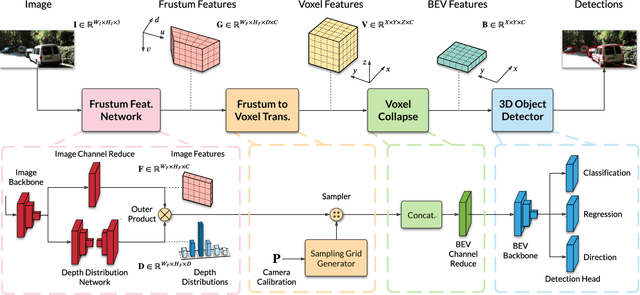
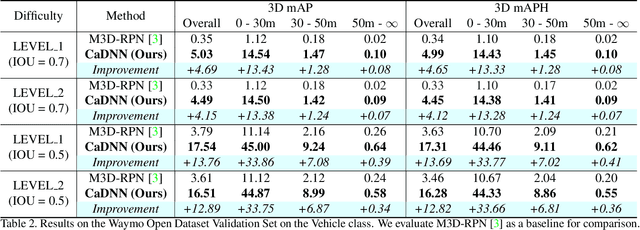
Monocular 3D object detection is a key problem for autonomous vehicles, as it provides a solution with simple configuration compared to typical multi-sensor systems. The main challenge in monocular 3D detection lies in accurately predicting object depth, which must be inferred from object and scene cues due to the lack of direct range measurement. Many methods attempt to directly estimate depth to assist in 3D detection, but show limited performance as a result of depth inaccuracy. Our proposed solution, Categorical Depth Distribution Network (CaDDN), uses a predicted categorical depth distribution for each pixel to project rich contextual feature information to the appropriate depth interval in 3D space. We then use the computationally efficient bird's-eye-view projection and single-stage detector to produce the final output bounding boxes. We design CaDDN as a fully differentiable end-to-end approach for joint depth estimation and object detection. We validate our approach on the KITTI 3D object detection benchmark, where we rank 1st among published monocular methods. We also provide the first monocular 3D detection results on the newly released Waymo Open Dataset. The source code for CaDDN will be made publicly available before publication.
Estimating and Evaluating Regression Predictive Uncertainty in Deep Object Detectors
Jan 19, 2021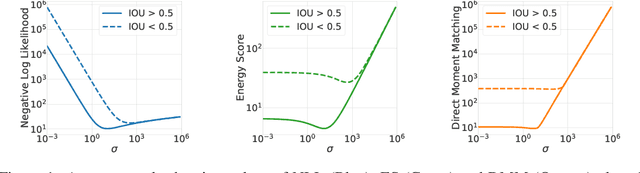
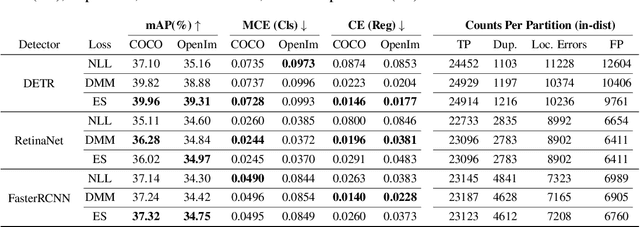

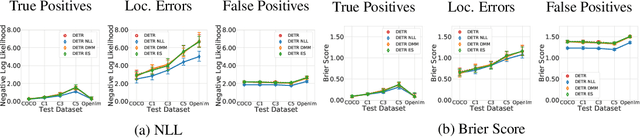
Predictive uncertainty estimation is an essential next step for the reliable deployment of deep object detectors in safety-critical tasks. In this work, we focus on estimating predictive distributions for bounding box regression output with variance networks. We show that in the context of object detection, training variance networks with negative log likelihood (NLL) can lead to high entropy predictive distributions regardless of the correctness of the output mean. We propose to use the energy score as a non-local proper scoring rule and find that when used for training, the energy score leads to better calibrated and lower entropy predictive distributions than NLL. We also address the widespread use of non-proper scoring metrics for evaluating predictive distributions from deep object detectors by proposing an alternate evaluation approach founded on proper scoring rules. Using the proposed evaluation tools, we show that although variance networks can be used to produce high quality predictive distributions, ad-hoc approaches used by seminal object detectors for choosing regression targets during training do not provide wide enough data support for reliable variance learning. We hope that our work helps shift evaluation in probabilistic object detection to better align with predictive uncertainty evaluation in other machine learning domains. Code for all models, evaluation, and datasets is available at: https://github.com/asharakeh/probdet.git.
A Review and Comparative Study on Probabilistic Object Detection in Autonomous Driving
Nov 20, 2020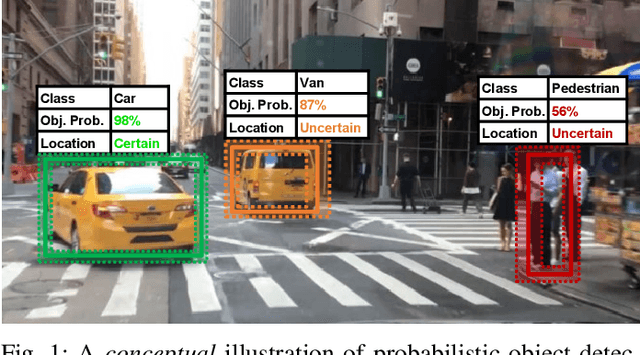
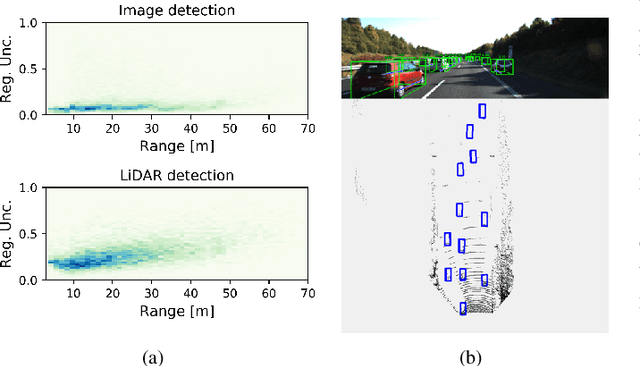
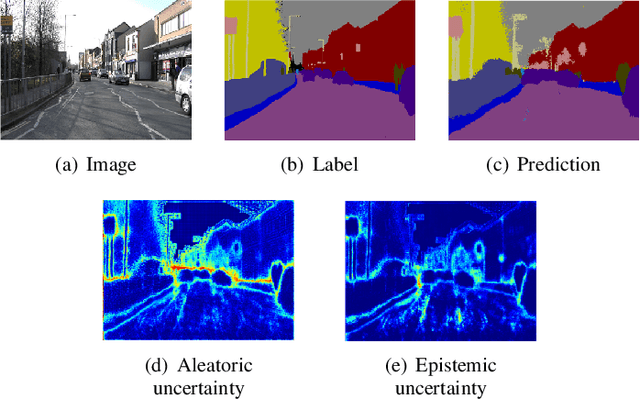
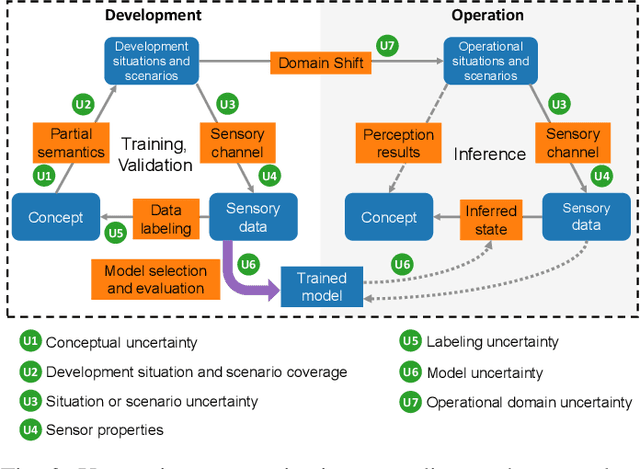
Capturing uncertainty in object detection is indispensable for safe autonomous driving. In recent years, deep learning has become the de-facto approach for object detection, and many probabilistic object detectors have been proposed. However, there is no summary on uncertainty estimation in deep object detection, and existing methods are not only built with different network architectures and uncertainty estimation methods, but also evaluated on different datasets with a wide range of evaluation metrics. As a result, a comparison among methods remains challenging, as does the selection of a model that best suits a particular application. This paper aims to alleviate this problem by providing a review and comparative study on existing probabilistic object detection methods for autonomous driving applications. First, we provide an overview of generic uncertainty estimation in deep learning, and then systematically survey existing methods and evaluation metrics for probabilistic object detection. Next, we present a strict comparative study for probabilistic object detection based on an image detector and three public autonomous driving datasets. Finally, we present a discussion of the remaining challenges and future works. Code has been made available at https://github.com/asharakeh/pod_compare.git
BayesOD: A Bayesian Approach for Uncertainty Estimation in Deep Object Detectors
Mar 09, 2019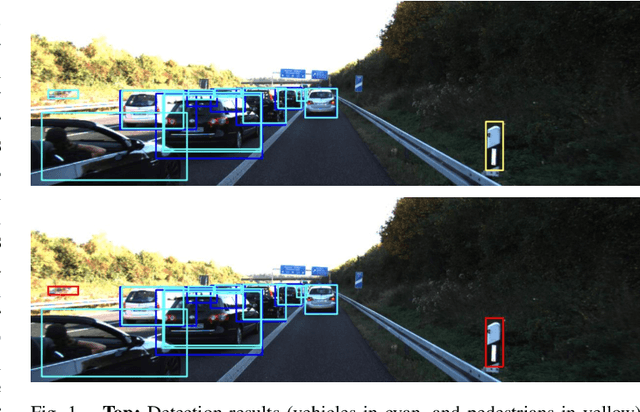
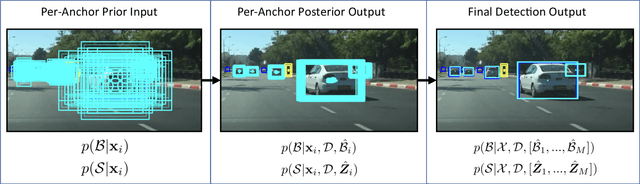
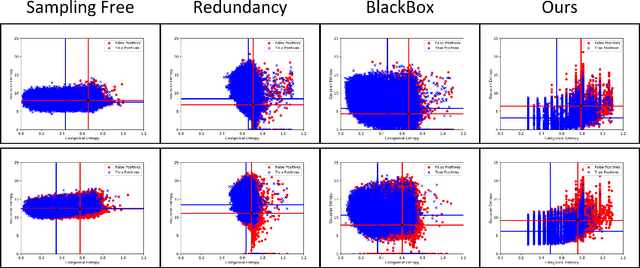

One of the challenging aspects of incorporating deep neural networks into robotic systems is the lack of uncertainty measures associated with their output predictions. Recent work has identified aleatoric and epistemic as two types of uncertainty in the output of deep neural networks, and provided methods for their estimation. However, these methods have had limited success when applied to the object detection task. This paper introduces, BayesOD, a Bayesian approach for estimating the uncertainty in the output of deep object detectors, which reformulates the neural network inference and Non-Maximum suppression components of standard object detectors from a Bayesian perspective. As a result, BayesOD provides uncertainty estimates associated with detected object instances, which allows the deep object detector to be treated as any other sensor in a robotic system. BayesOD is shown to be capable of reliably identifying erroneous detection output instances using their estimated uncertainty measure. The estimated uncertainty measures are also shown to be better correlated with the correctness of a detection than the state of the art methods available in literature.
A Hierarchical Deep Architecture and Mini-Batch Selection Method For Joint Traffic Sign and Light Detection
Sep 13, 2018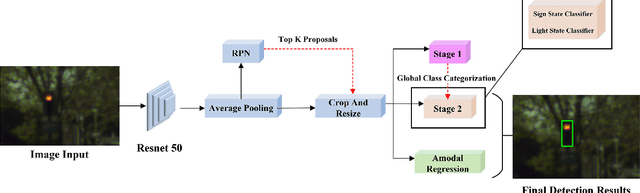



Traffic light and sign detectors on autonomous cars are integral for road scene perception. The literature is abundant with deep learning networks that detect either lights or signs, not both, which makes them unsuitable for real-life deployment due to the limited graphics processing unit (GPU) memory and power available on embedded systems. The root cause of this issue is that no public dataset contains both traffic light and sign labels, which leads to difficulties in developing a joint detection framework. We present a deep hierarchical architecture in conjunction with a mini-batch proposal selection mechanism that allows a network to detect both traffic lights and signs from training on separate traffic light and sign datasets. Our method solves the overlapping issue where instances from one dataset are not labelled in the other dataset. We are the first to present a network that performs joint detection on traffic lights and signs. We measure our network on the Tsinghua-Tencent 100K benchmark for traffic sign detection and the Bosch Small Traffic Lights benchmark for traffic light detection and show it outperforms the existing Bosch Small Traffic light state-of-the-art method. We focus on autonomous car deployment and show our network is more suitable than others because of its low memory footprint and real-time image processing time. Qualitative results can be viewed at https://youtu.be/_YmogPzBXOw