 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeShap: Weak Supervision Source Evaluation with Shapley Values
Jun 16, 2024



Efficient data annotation stands as a significant bottleneck in training contemporary machine learning models. The Programmatic Weak Supervision (PWS) pipeline presents a solution by utilizing multiple weak supervision sources to automatically label data, thereby expediting the annotation process. Given the varied contributions of these weak supervision sources to the accuracy of PWS, it is imperative to employ a robust and efficient metric for their evaluation. This is crucial not only for understanding the behavior and performance of the PWS pipeline but also for facilitating corrective measures. In our study, we introduce WeShap values as an evaluation metric, which quantifies the average contribution of weak supervision sources within a proxy PWS pipeline, leveraging the theoretical underpinnings of Shapley values. We demonstrate efficient computation of WeShap values using dynamic programming, achieving quadratic computational complexity relative to the number of weak supervision sources. Our experiments demonstrate the versatility of WeShap values across various applications, including the identification of beneficial or detrimental labeling functions, refinement of the PWS pipeline, and rectification of mislabeled data. Furthermore, WeShap values aid in comprehending the behavior of the PWS pipeline and scrutinizing specific instances of mislabeled data. Although initially derived from a specific proxy PWS pipeline, we empirically demonstrate the generalizability of WeShap values to other PWS pipeline configurations. Our findings indicate a noteworthy average improvement of 4.8 points in downstream model accuracy through the revision of the PWS pipeline compared to previous state-of-the-art methods, underscoring the efficacy of WeShap values in enhancing data quality for training machine learning models.
ActiveDP: Bridging Active Learning and Data Programming
Feb 08, 2024



Modern machine learning models require large labelled datasets to achieve good performance, but manually labelling large datasets is expensive and time-consuming. The data programming paradigm enables users to label large datasets efficiently but produces noisy labels, which deteriorates the downstream model's performance. The active learning paradigm, on the other hand, can acquire accurate labels but only for a small fraction of instances. In this paper, we propose ActiveDP, an interactive framework bridging active learning and data programming together to generate labels with both high accuracy and coverage, combining the strengths of both paradigms. Experiments show that ActiveDP outperforms previous weak supervision and active learning approaches and consistently performs well under different labelling budgets.
Can Large Language Models Design Accurate Label Functions?
Nov 01, 2023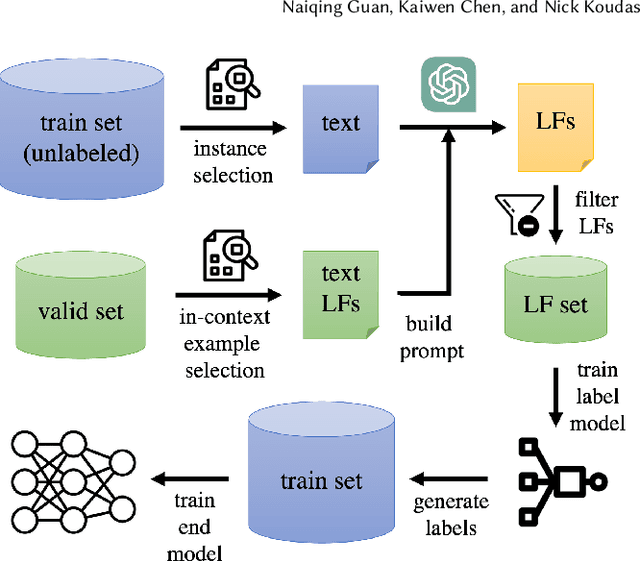



Programmatic weak supervision methodologies facilitate the expedited labeling of extensive datasets through the use of label functions (LFs) that encapsulate heuristic data sources. Nonetheless, the creation of precise LFs necessitates domain expertise and substantial endeavors. Recent advances in pre-trained language models (PLMs) have exhibited substantial potential across diverse tasks. However, the capacity of PLMs to autonomously formulate accurate LFs remains an underexplored domain. In this research, we address this gap by introducing DataSculpt, an interactive framework that harnesses PLMs for the automated generation of LFs. Within DataSculpt, we incorporate an array of prompting techniques, instance selection strategies, and LF filtration methods to explore the expansive design landscape. Ultimately, we conduct a thorough assessment of DataSculpt's performance on 12 real-world datasets, encompassing a range of tasks. This evaluation unveils both the strengths and limitations of contemporary PLMs in LF design.
Estimating Regression Predictive Distributions with Sample Networks
Nov 24, 2022Estimating the uncertainty in deep neural network predictions is crucial for many real-world applications. A common approach to model uncertainty is to choose a parametric distribution and fit the data to it using maximum likelihood estimation. The chosen parametric form can be a poor fit to the data-generating distribution, resulting in unreliable uncertainty estimates. In this work, we propose SampleNet, a flexible and scalable architecture for modeling uncertainty that avoids specifying a parametric form on the output distribution. SampleNets do so by defining an empirical distribution using samples that are learned with the Energy Score and regularized with the Sinkhorn Divergence. SampleNets are shown to be able to well-fit a wide range of distributions and to outperform baselines on large-scale real-world regression tasks.