 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Large Language Models Design Accurate Label Functions?
Paper and Code
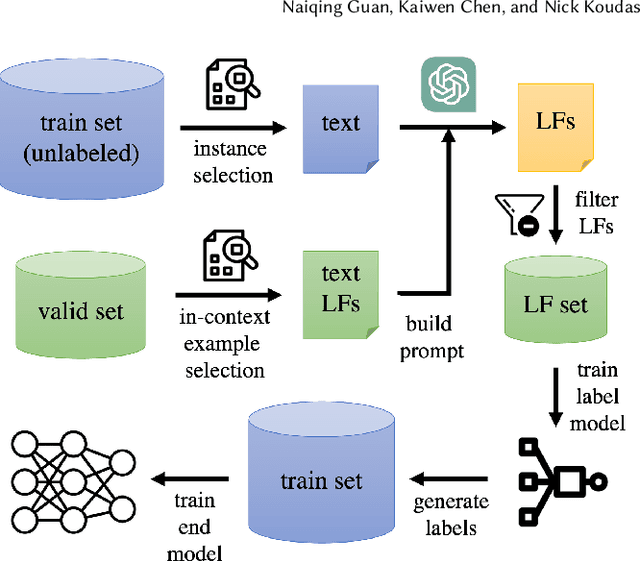



Programmatic weak supervision methodologies facilitate the expedited labeling of extensive datasets through the use of label functions (LFs) that encapsulate heuristic data sources. Nonetheless, the creation of precise LFs necessitates domain expertise and substantial endeavors. Recent advances in pre-trained language models (PLMs) have exhibited substantial potential across diverse tasks. However, the capacity of PLMs to autonomously formulate accurate LFs remains an underexplored domain. In this research, we address this gap by introducing DataSculpt, an interactive framework that harnesses PLMs for the automated generation of LFs. Within DataSculpt, we incorporate an array of prompting techniques, instance selection strategies, and LF filtration methods to explore the expansive design landscape. Ultimately, we conduct a thorough assessment of DataSculpt's performance on 12 real-world datasets, encompassing a range of tasks. This evaluation unveils both the strengths and limitations of contemporary PLMs in LF design.