 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFiner-Personalization Rank: Fine-Grained Retrieval Examines Identity Preservation for Personalized Generation
Dec 22, 2025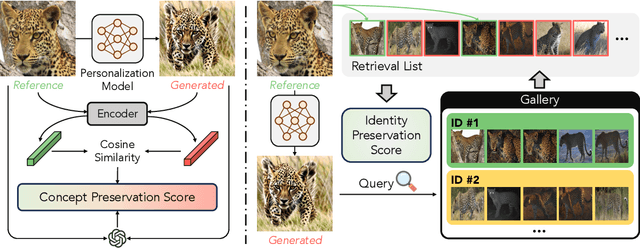
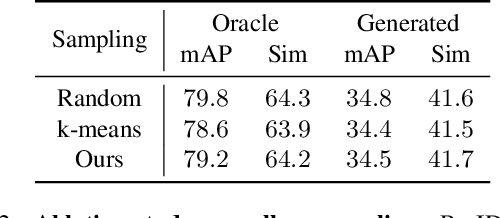
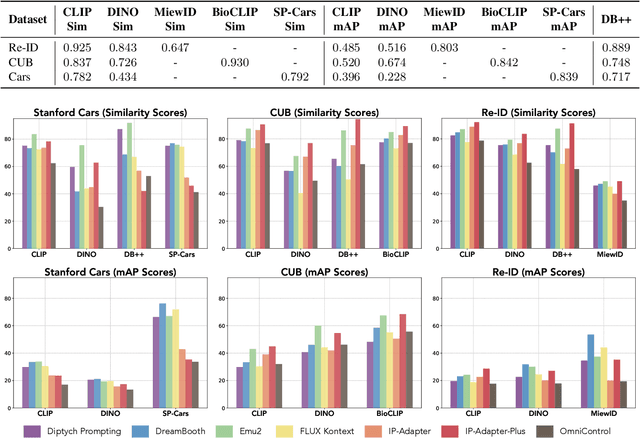

The rise of personalized generative models raises a central question: how should we evaluate identity preservation? Given a reference image (e.g., one's pet), we expect the generated image to retain precise details attached to the subject's identity. However, current generative evaluation metrics emphasize the overall semantic similarity between the reference and the output, and overlook these fine-grained discriminative details. We introduce Finer-Personalization Rank, an evaluation protocol tailored to identity preservation. Instead of pairwise similarity, Finer-Personalization Rank adopts a ranking view: it treats each generated image as a query against an identity-labeled gallery consisting of visually similar real images. Retrieval metrics (e.g., mean average precision) measure performance, where higher scores indicate that identity-specific details (e.g., a distinctive head spot) are preserved. We assess identity at multiple granularities -- from fine-grained categories (e.g., bird species, car models) to individual instances (e.g., re-identification). Across CUB, Stanford Cars, and animal Re-ID benchmarks, Finer-Personalization Rank more faithfully reflects identity retention than semantic-only metrics and reveals substantial identity drift in several popular personalization methods. These results position the gallery-based protocol as a principled and practical evaluation for personalized generation.
INQUIRE-Search: A Framework for Interactive Discovery in Large-Scale Biodiversity Databases
Nov 19, 2025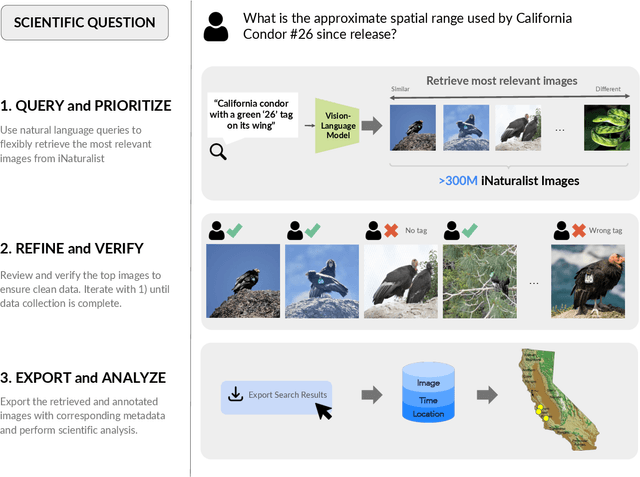
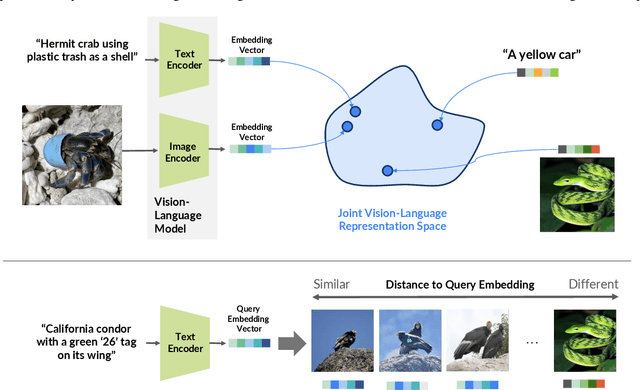

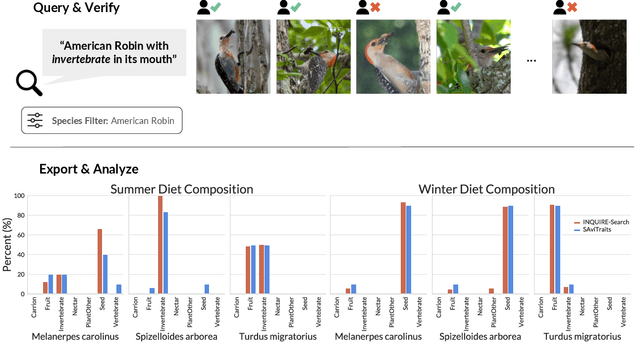
Large community science platforms such as iNaturalist contain hundreds of millions of biodiversity images that often capture ecological context on behaviors, interactions, phenology, and habitat. Yet most ecological workflows rely on metadata filtering or manual inspection, leaving this secondary information inaccessible at scale. We introduce INQUIRE-Search, an open-source system that enables scientists to rapidly and interactively search within an ecological image database for specific concepts using natural language, verify and export relevant observations, and utilize this discovered data for novel scientific analysis. Compared to traditional methods, INQUIRE-Search takes a fraction of the time, opening up new possibilities for scientific questions that can be explored. Through five case studies, we show the diversity of scientific applications that a tool like INQUIRE-Search can support, from seasonal variation in behavior across species to forest regrowth after wildfires. These examples demonstrate a new paradigm for interactive, efficient, and scalable scientific discovery that can begin to unlock previously inaccessible scientific value in large-scale biodiversity datasets. Finally, we emphasize using such AI-enabled discovery tools for science call for experts to reframe the priorities of the scientific process and develop novel methods for experiment design, data collection, survey effort, and uncertainty analysis.
Personalized Representation from Personalized Generation
Dec 20, 2024Modern vision models excel at general purpose downstream tasks. It is unclear, however, how they may be used for personalized vision tasks, which are both fine-grained and data-scarce. Recent works have successfully applied synthetic data to general-purpose representation learning, while advances in T2I diffusion models have enabled the generation of personalized images from just a few real examples. Here, we explore a potential connection between these ideas, and formalize the challenge of using personalized synthetic data to learn personalized representations, which encode knowledge about an object of interest and may be flexibly applied to any downstream task relating to the target object. We introduce an evaluation suite for this challenge, including reformulations of two existing datasets and a novel dataset explicitly constructed for this purpose, and propose a contrastive learning approach that makes creative use of image generators. We show that our method improves personalized representation learning for diverse downstream tasks, from recognition to segmentation, and analyze characteristics of image generation approaches that are key to this gain.
Categorical Depth Distribution Network for Monocular 3D Object Detection
Mar 01, 2021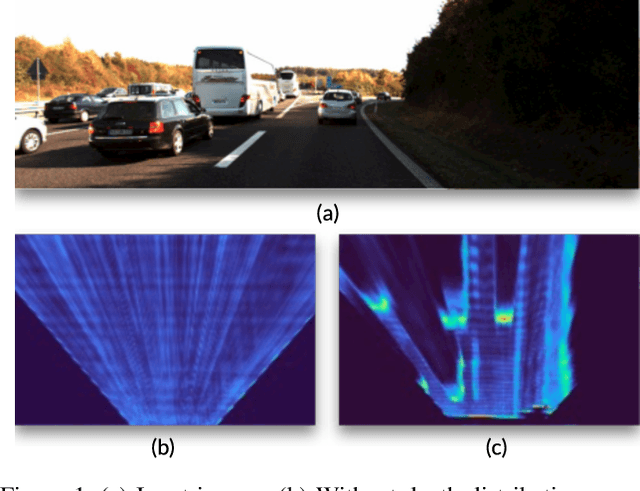
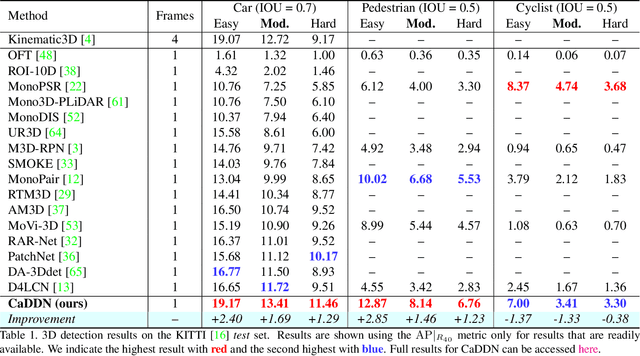
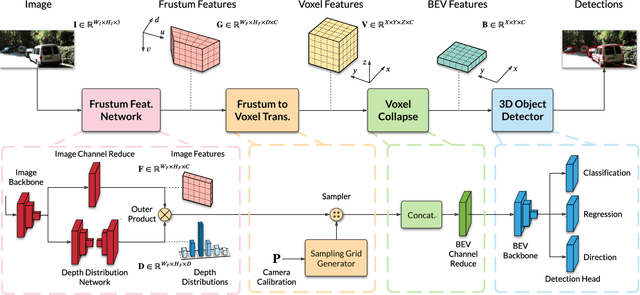
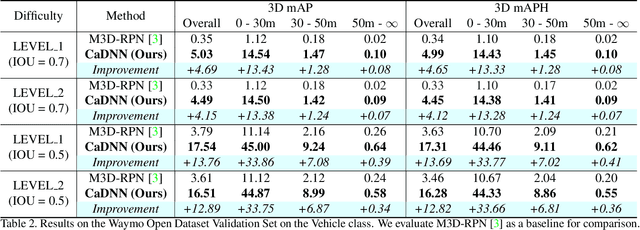
Monocular 3D object detection is a key problem for autonomous vehicles, as it provides a solution with simple configuration compared to typical multi-sensor systems. The main challenge in monocular 3D detection lies in accurately predicting object depth, which must be inferred from object and scene cues due to the lack of direct range measurement. Many methods attempt to directly estimate depth to assist in 3D detection, but show limited performance as a result of depth inaccuracy. Our proposed solution, Categorical Depth Distribution Network (CaDDN), uses a predicted categorical depth distribution for each pixel to project rich contextual feature information to the appropriate depth interval in 3D space. We then use the computationally efficient bird's-eye-view projection and single-stage detector to produce the final output bounding boxes. We design CaDDN as a fully differentiable end-to-end approach for joint depth estimation and object detection. We validate our approach on the KITTI 3D object detection benchmark, where we rank 1st among published monocular methods. We also provide the first monocular 3D detection results on the newly released Waymo Open Dataset. The source code for CaDDN will be made publicly available before publication.