 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBACS: Background Aware Continual Semantic Segmentation
Apr 19, 2024



Semantic segmentation plays a crucial role in enabling comprehensive scene understanding for robotic systems. However, generating annotations is challenging, requiring labels for every pixel in an image. In scenarios like autonomous driving, there's a need to progressively incorporate new classes as the operating environment of the deployed agent becomes more complex. For enhanced annotation efficiency, ideally, only pixels belonging to new classes would be annotated. This approach is known as Continual Semantic Segmentation (CSS). Besides the common problem of classical catastrophic forgetting in the continual learning setting, CSS suffers from the inherent ambiguity of the background, a phenomenon we refer to as the "background shift'', since pixels labeled as background could correspond to future classes (forward background shift) or previous classes (backward background shift). As a result, continual learning approaches tend to fail. This paper proposes a Backward Background Shift Detector (BACS) to detect previously observed classes based on their distance in the latent space from the foreground centroids of previous steps. Moreover, we propose a modified version of the cross-entropy loss function, incorporating the BACS detector to down-weight background pixels associated with formerly observed classes. To combat catastrophic forgetting, we employ masked feature distillation alongside dark experience replay. Additionally, our approach includes a transformer decoder capable of adjusting to new classes without necessitating an additional classification head. We validate BACS's superior performance over existing state-of-the-art methods on standard CSS benchmarks.
Layerwise Early Stopping for Test Time Adaptation
Apr 04, 2024



Test Time Adaptation (TTA) addresses the problem of distribution shift by enabling pretrained models to learn new features on an unseen domain at test time. However, it poses a significant challenge to maintain a balance between learning new features and retaining useful pretrained features. In this paper, we propose Layerwise EArly STopping (LEAST) for TTA to address this problem. The key idea is to stop adapting individual layers during TTA if the features being learned do not appear beneficial for the new domain. For that purpose, we propose using a novel gradient-based metric to measure the relevance of the current learnt features to the new domain without the need for supervised labels. More specifically, we propose to use this metric to determine dynamically when to stop updating each layer during TTA. This enables a more balanced adaptation, restricted to layers benefiting from it, and only for a certain number of steps. Such an approach also has the added effect of limiting the forgetting of pretrained features useful for dealing with new domains. Through extensive experiments, we demonstrate that Layerwise Early Stopping improves the performance of existing TTA approaches across multiple datasets, domain shifts, model architectures, and TTA losses.
GROOD: GRadient-aware Out-Of-Distribution detection in interpolated manifolds
Dec 22, 2023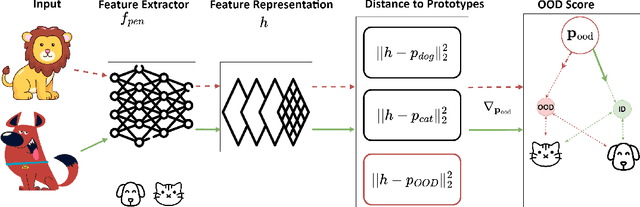
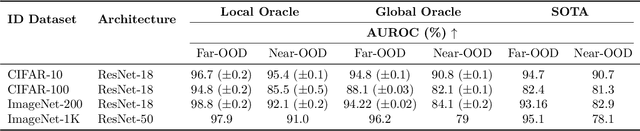
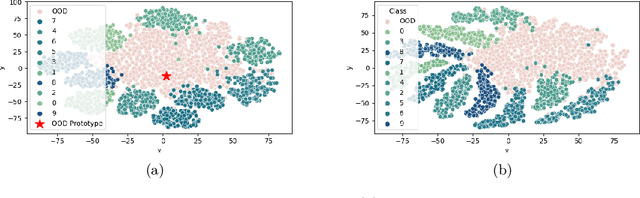
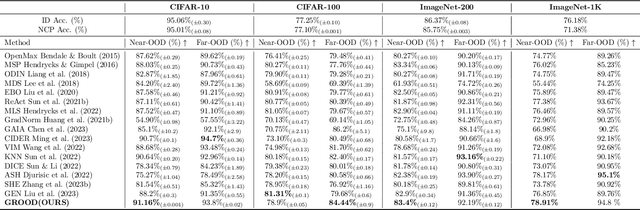
Deep neural networks (DNNs) often fail silently with over-confident predictions on out-of-distribution (OOD) samples, posing risks in real-world deployments. Existing techniques predominantly emphasize either the feature representation space or the gradient norms computed with respect to DNN parameters, yet they overlook the intricate gradient distribution and the topology of classification regions. To address this gap, we introduce GRadient-aware Out-Of-Distribution detection in interpolated manifolds (GROOD), a novel framework that relies on the discriminative power of gradient space to distinguish between in-distribution (ID) and OOD samples. To build this space, GROOD relies on class prototypes together with a prototype that specifically captures OOD characteristics. Uniquely, our approach incorporates a targeted mix-up operation at an early intermediate layer of the DNN to refine the separation of gradient spaces between ID and OOD samples. We quantify OOD detection efficacy using the distance to the nearest neighbor gradients derived from the training set, yielding a robust OOD score. Experimental evaluations substantiate that the introduction of targeted input mix-upamplifies the separation between ID and OOD in the gradient space, yielding impressive results across diverse datasets. Notably, when benchmarked against ImageNet-1k, GROOD surpasses the established robustness of state-of-the-art baselines. Through this work, we establish the utility of leveraging gradient spaces and class prototypes for enhanced OOD detection for DNN in image classification.
Towards Lifelong Self-Supervision For Unpaired Image-to-Image Translation
Mar 31, 2020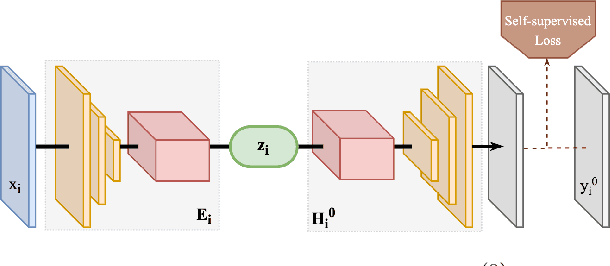
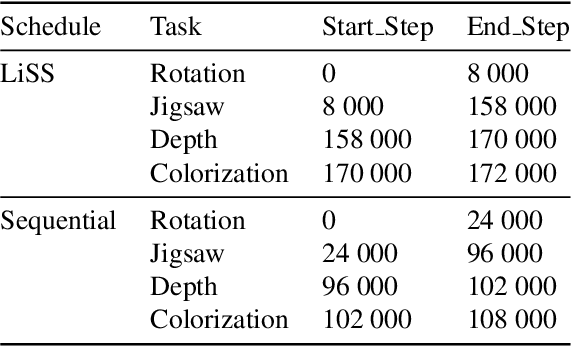
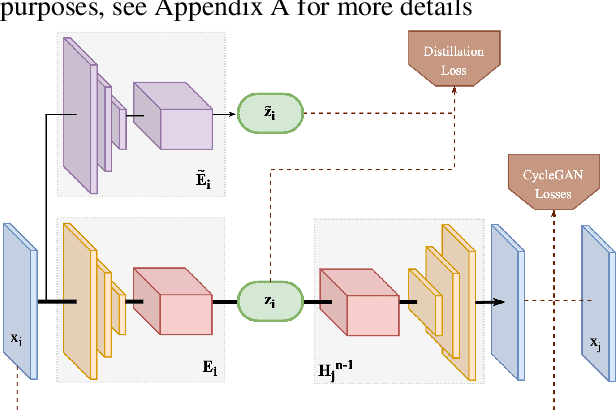
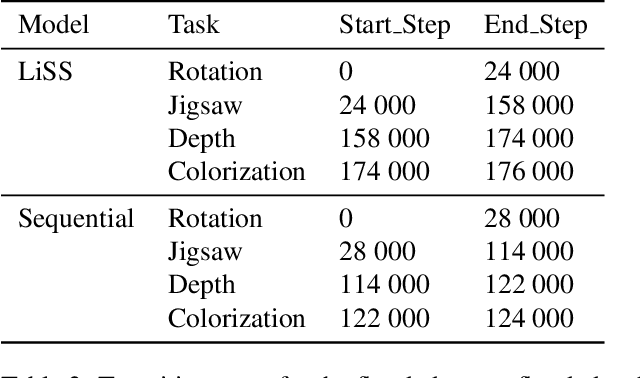
Unpaired Image-to-Image Translation (I2IT) tasks often suffer from lack of data, a problem which self-supervised learning (SSL) has recently been very popular and successful at tackling. Leveraging auxiliary tasks such as rotation prediction or generative colorization, SSL can produce better and more robust representations in a low data regime. Training such tasks along an I2IT task is however computationally intractable as model size and the number of task grow. On the other hand, learning sequentially could incur catastrophic forgetting of previously learned tasks. To alleviate this, we introduce Lifelong Self-Supervision (LiSS) as a way to pre-train an I2IT model (e.g., CycleGAN) on a set of self-supervised auxiliary tasks. By keeping an exponential moving average of past encoders and distilling the accumulated knowledge, we are able to maintain the network's validation performance on a number of tasks without any form of replay, parameter isolation or retraining techniques typically used in continual learning. We show that models trained with LiSS perform better on past tasks, while also being more robust than the CycleGAN baseline to color bias and entity entanglement (when two entities are very close).
Identifying Critical Neurons in ANN Architectures using Mixed Integer Programming
Feb 17, 2020



We introduce a novel approach to optimize the architecture of deep neural networks by identifying critical neurons and removing non-critical ones. The proposed approach utilizes a mixed integer programming (MIP) formulation of neural models which includes a continuous importance score computed for each neuron in the network. The optimization in MIP solver minimizes the number of critical neurons (i.e., with high importance score) that need to be kept for maintaining the overall accuracy of the model. Further, the proposed formulation generalizes the recently considered lottery ticket optimization by identifying multiple "lucky" sub-networks resulting in optimized architecture that not only perform well on a single dataset, but also generalize across multiple ones upon retraining of network weights. Finally, the proposed framework provides significant improvement in scalability of automatic sparsification of deep network architectures compared to previous attempts. We validate the performance and generalizability of our approach on MNIST, Fashion-MNIST, and CIFAR-10 datasets, using three different neural networks: LeNet 5 and two ReLU fully connected models.