 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Lifelong Self-Supervision For Unpaired Image-to-Image Translation
Paper and Code
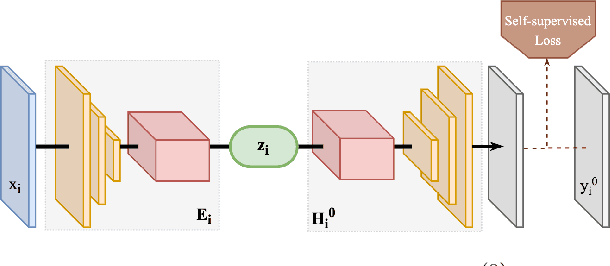
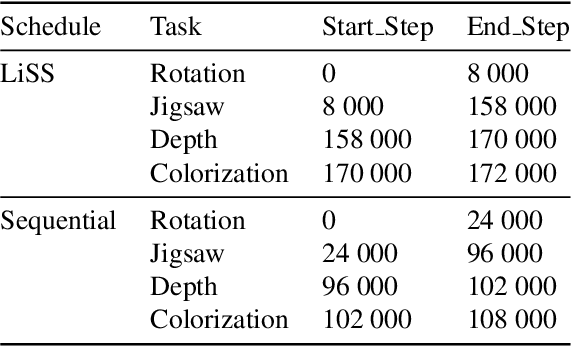
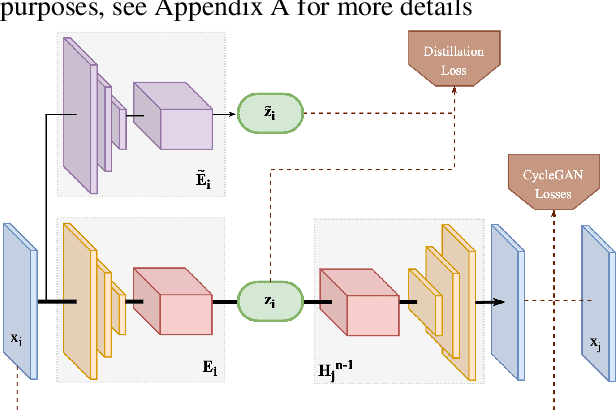
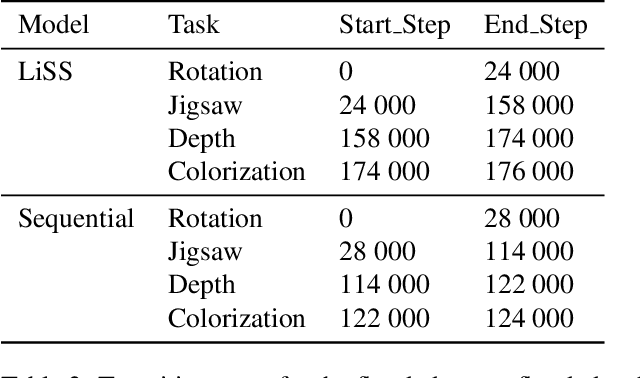
Unpaired Image-to-Image Translation (I2IT) tasks often suffer from lack of data, a problem which self-supervised learning (SSL) has recently been very popular and successful at tackling. Leveraging auxiliary tasks such as rotation prediction or generative colorization, SSL can produce better and more robust representations in a low data regime. Training such tasks along an I2IT task is however computationally intractable as model size and the number of task grow. On the other hand, learning sequentially could incur catastrophic forgetting of previously learned tasks. To alleviate this, we introduce Lifelong Self-Supervision (LiSS) as a way to pre-train an I2IT model (e.g., CycleGAN) on a set of self-supervised auxiliary tasks. By keeping an exponential moving average of past encoders and distilling the accumulated knowledge, we are able to maintain the network's validation performance on a number of tasks without any form of replay, parameter isolation or retraining techniques typically used in continual learning. We show that models trained with LiSS perform better on past tasks, while also being more robust than the CycleGAN baseline to color bias and entity entanglement (when two entities are very close).