 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgegQIR: Generative Quanta Image Reconstruction
Feb 23, 2026Capturing high-quality images from only a few detected photons is a fundamental challenge in computational imaging. Single-photon avalanche diode (SPAD) sensors promise high-quality imaging in regimes where conventional cameras fail, but raw \emph{quanta frames} contain only sparse, noisy, binary photon detections. Recovering a coherent image from a burst of such frames requires handling alignment, denoising, and demosaicing (for color) under noise statistics far outside those assumed by standard restoration pipelines or modern generative models. We present an approach that adapts large text-to-image latent diffusion models to the photon-limited domain of quanta burst imaging. Our method leverages the structural and semantic priors of internet-scale diffusion models while introducing mechanisms to handle Bernoulli photon statistics. By integrating latent-space restoration with burst-level spatio-temporal reasoning, our approach produces reconstructions that are both photometrically faithful and perceptually pleasing, even under high-speed motion. We evaluate the method on synthetic benchmarks and new real-world datasets, including the first color SPAD burst dataset and a challenging \textit{Deforming (XD)} video benchmark. Across all settings, the approach substantially improves perceptual quality over classical and modern learning-based baselines, demonstrating the promise of adapting large generative priors to extreme photon-limited sensing. Code at \href{https://github.com/Aryan-Garg/gQIR}{https://github.com/Aryan-Garg/gQIR}.
Controllable GUI Exploration
Feb 05, 2025



During the early stages of interface design, designers need to produce multiple sketches to explore a design space. Design tools often fail to support this critical stage, because they insist on specifying more details than necessary. Although recent advances in generative AI have raised hopes of solving this issue, in practice they fail because expressing loose ideas in a prompt is impractical. In this paper, we propose a diffusion-based approach to the low-effort generation of interface sketches. It breaks new ground by allowing flexible control of the generation process via three types of inputs: A) prompts, B) wireframes, and C) visual flows. The designer can provide any combination of these as input at any level of detail, and will get a diverse gallery of low-fidelity solutions in response. The unique benefit is that large design spaces can be explored rapidly with very little effort in input-specification. We present qualitative results for various combinations of input specifications. Additionally, we demonstrate that our model aligns more accurately with these specifications than other models.
IP-FaceDiff: Identity-Preserving Facial Video Editing with Diffusion
Jan 13, 2025Facial video editing has become increasingly important for content creators, enabling the manipulation of facial expressions and attributes. However, existing models encounter challenges such as poor editing quality, high computational costs and difficulties in preserving facial identity across diverse edits. Additionally, these models are often constrained to editing predefined facial attributes, limiting their flexibility to diverse editing prompts. To address these challenges, we propose a novel facial video editing framework that leverages the rich latent space of pre-trained text-to-image (T2I) diffusion models and fine-tune them specifically for facial video editing tasks. Our approach introduces a targeted fine-tuning scheme that enables high quality, localized, text-driven edits while ensuring identity preservation across video frames. Additionally, by using pre-trained T2I models during inference, our approach significantly reduces editing time by 80%, while maintaining temporal consistency throughout the video sequence. We evaluate the effectiveness of our approach through extensive testing across a wide range of challenging scenarios, including varying head poses, complex action sequences, and diverse facial expressions. Our method consistently outperforms existing techniques, demonstrating superior performance across a broad set of metrics and benchmarks.
HDRSplat: Gaussian Splatting for High Dynamic Range 3D Scene Reconstruction from Raw Images
Jul 23, 2024The recent advent of 3D Gaussian Splatting (3DGS) has revolutionized the 3D scene reconstruction space enabling high-fidelity novel view synthesis in real-time. However, with the exception of RawNeRF, all prior 3DGS and NeRF-based methods rely on 8-bit tone-mapped Low Dynamic Range (LDR) images for scene reconstruction. Such methods struggle to achieve accurate reconstructions in scenes that require a higher dynamic range. Examples include scenes captured in nighttime or poorly lit indoor spaces having a low signal-to-noise ratio, as well as daylight scenes with shadow regions exhibiting extreme contrast. Our proposed method HDRSplat tailors 3DGS to train directly on 14-bit linear raw images in near darkness which preserves the scenes' full dynamic range and content. Our key contributions are two-fold: Firstly, we propose a linear HDR space-suited loss that effectively extracts scene information from noisy dark regions and nearly saturated bright regions simultaneously, while also handling view-dependent colors without increasing the degree of spherical harmonics. Secondly, through careful rasterization tuning, we implicitly overcome the heavy reliance and sensitivity of 3DGS on point cloud initialization. This is critical for accurate reconstruction in regions of low texture, high depth of field, and low illumination. HDRSplat is the fastest method to date that does 14-bit (HDR) 3D scene reconstruction in $\le$15 minutes/scene ($\sim$30x faster than prior state-of-the-art RawNeRF). It also boasts the fastest inference speed at $\ge$120fps. We further demonstrate the applicability of our HDR scene reconstruction by showcasing various applications like synthetic defocus, dense depth map extraction, and post-capture control of exposure, tone-mapping and view-point.
Stereo-Knowledge Distillation from dpMV to Dual Pixels for Light Field Video Reconstruction
May 20, 2024Dual pixels contain disparity cues arising from the defocus blur. This disparity information is useful for many vision tasks ranging from autonomous driving to 3D creative realism. However, directly estimating disparity from dual pixels is less accurate. This work hypothesizes that distilling high-precision dark stereo knowledge, implicitly or explicitly, to efficient dual-pixel student networks enables faithful reconstructions. This dark knowledge distillation should also alleviate stereo-synchronization setup and calibration costs while dramatically increasing parameter and inference time efficiency. We collect the first and largest 3-view dual-pixel video dataset, dpMV, to validate our explicit dark knowledge distillation hypothesis. We show that these methods outperform purely monocular solutions, especially in challenging foreground-background separation regions using faithful guidance from dual pixels. Finally, we demonstrate an unconventional use case unlocked by dpMV and implicit dark knowledge distillation from an ensemble of teachers for Light Field (LF) video reconstruction. Our LF video reconstruction method is the fastest and most temporally consistent to date. It remains competitive in reconstruction fidelity while offering many other essential properties like high parameter efficiency, implicit disocclusion handling, zero-shot cross-dataset transfer, geometrically consistent inference on higher spatial-angular resolutions, and adaptive baseline control. All source code is available at the anonymous repository https://github.com/Aryan-Garg.
Parameter and Data-Efficient Spectral StyleDCGAN
Mar 31, 2024We present a simple, highly parameter, and data-efficient adversarial network for unconditional face generation. Our method: Spectral Style-DCGAN or SSD utilizes only 6.574 million parameters and 4739 dog faces from the Animal Faces HQ (AFHQ) dataset as training samples while preserving fidelity at low resolutions up to 64x64. Code available at https://github.com/Aryan-Garg/StyleDCGAN.
Analyzing the Robustness of PECNet
Oct 15, 2022
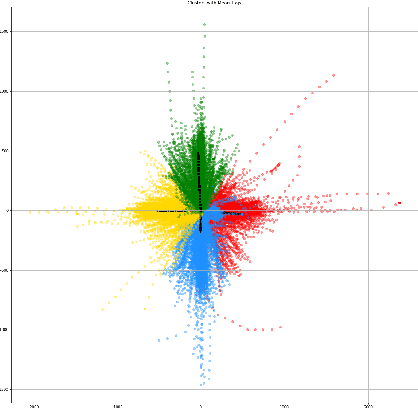
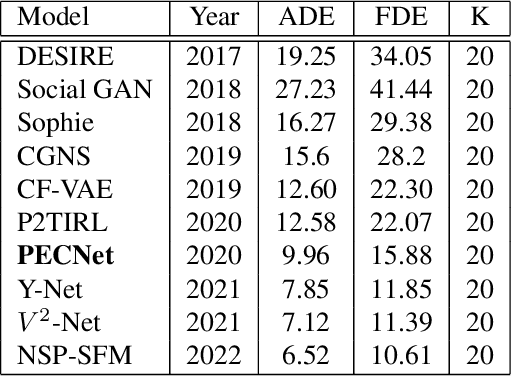
Comprehensive robustness analysis of PECNet, a pedestrian trajectory prediction system for autonomous vehicles. A novel metric is introduced for dataset analysis and classification. Synthetic data augmentation techniques ranging from Newtonian mechanics to Deep Reinforcement Learning based simulations are used to improve and test the system. An improvement of 9.5% over state-of-the-art results is seen on the FDE while compromising ADE. We introduce novel architectural changes using SIRENs for higher precision results to validate our robustness hypotheses. Additionally, we diagrammatically propose a novel multi-modal system for the same task.