 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing the Robustness of PECNet
Oct 15, 2022
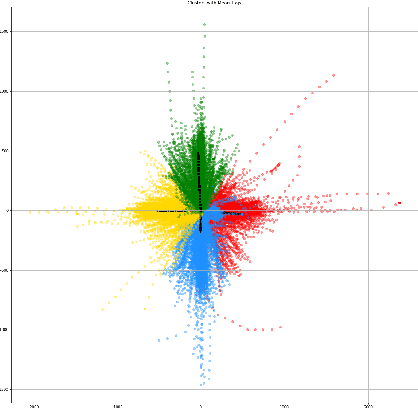
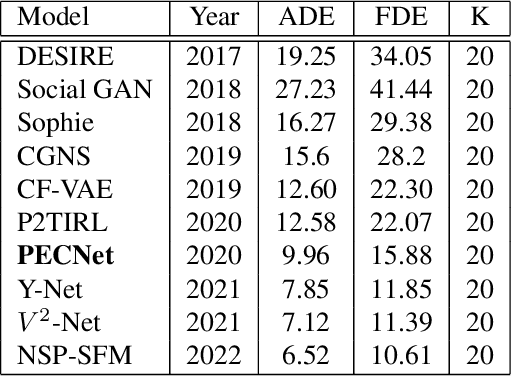
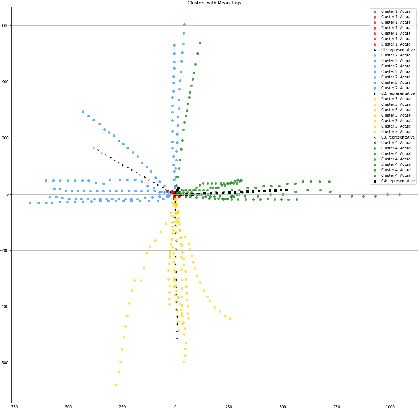
Comprehensive robustness analysis of PECNet, a pedestrian trajectory prediction system for autonomous vehicles. A novel metric is introduced for dataset analysis and classification. Synthetic data augmentation techniques ranging from Newtonian mechanics to Deep Reinforcement Learning based simulations are used to improve and test the system. An improvement of 9.5% over state-of-the-art results is seen on the FDE while compromising ADE. We introduce novel architectural changes using SIRENs for higher precision results to validate our robustness hypotheses. Additionally, we diagrammatically propose a novel multi-modal system for the same task.
Learning-Based Practical Light Field Image Compression Using A Disparity-Aware Model
Jun 23, 2021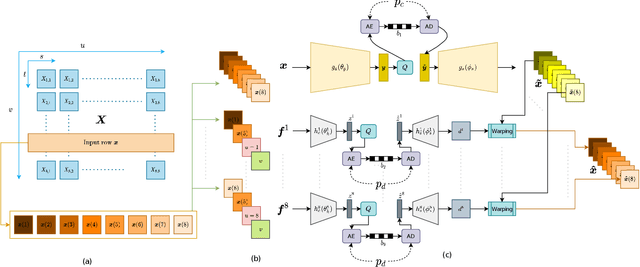
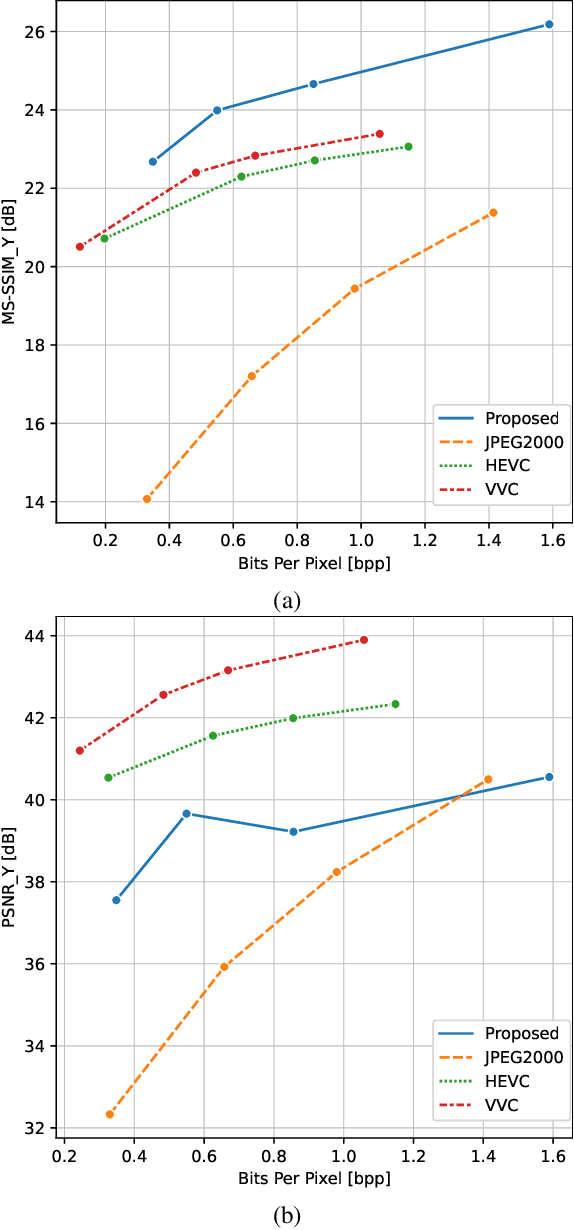

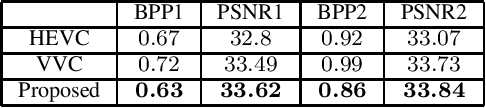
Light field technology has increasingly attracted the attention of the research community with its many possible applications. The lenslet array in commercial plenoptic cameras helps capture both the spatial and angular information of light rays in a single exposure. While the resulting high dimensionality of light field data enables its superior capabilities, it also impedes its extensive adoption. Hence, there is a compelling need for efficient compression of light field images. Existing solutions are commonly composed of several separate modules, some of which may not have been designed for the specific structure and quality of light field data. This increases the complexity of the codec and results in impractical decoding runtimes. We propose a new learning-based, disparity-aided model for compression of 4D light field images capable of parallel decoding. The model is end-to-end trainable, eliminating the need for hand-tuning separate modules and allowing joint learning of rate and distortion. The disparity-aided approach ensures the structural integrity of the reconstructed light fields. Comparisons with the state of the art show encouraging performance in terms of PSNR and MS-SSIM metrics. Also, there is a notable gain in the encoding and decoding runtimes. Source code is available at https://moha23.github.io/LF-DAAE.
MOTS R-CNN: Cosine-margin-triplet loss for multi-object tracking
Feb 06, 2021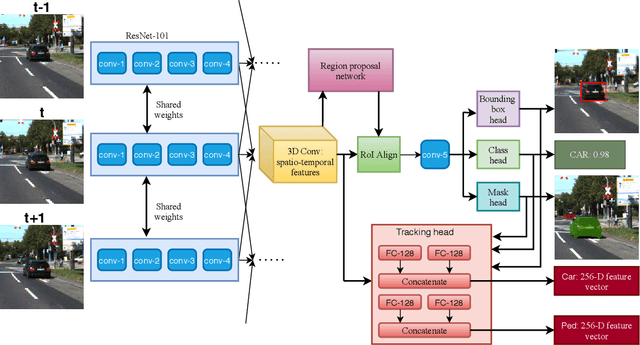



One of the central tasks of multi-object tracking involves learning a distance metric that is consistent with the semantic similarities of objects. The design of an appropriate loss function that encourages discriminative feature learning is among the most crucial challenges in deep neural network-based metric learning. Despite significant progress, slow convergence and a poor local optimum of the existing contrastive and triplet loss based deep metric learning methods necessitates a better solution. In this paper, we propose cosine-margin-contrastive (CMC) and cosine-margin-triplet (CMT) loss by reformulating both contrastive and triplet loss functions from the perspective of cosine distance. The proposed reformulation as a cosine loss is achieved by feature normalization which distributes the learned features on a hypersphere. We then propose the MOTS R-CNN framework for joint multi-object tracking and segmentation, particularly targeted at improving the tracking performance. Specifically, the tracking problem is addressed through deep metric learning based on the proposed loss functions. We propose a scale-invariant tracking by using a multi-layer feature aggregation scheme to make the model robust against object scale variations and occlusions. The MOTS R-CNN achieves the state-of-the-art tracking performance on the KITTI MOTS dataset. We show that the MOTS R-CNN reduces the identity switching by $62\%$ and $61\%$ on cars and pedestrians, respectively in comparison to Track R-CNN.