 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning-Based Practical Light Field Image Compression Using A Disparity-Aware Model
Jun 23, 2021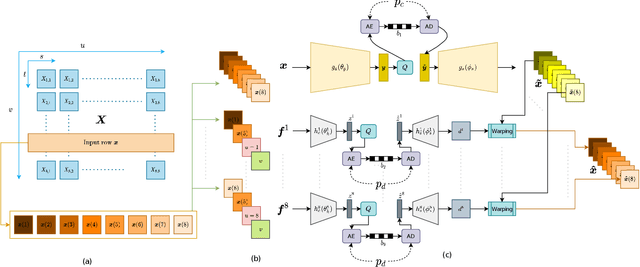
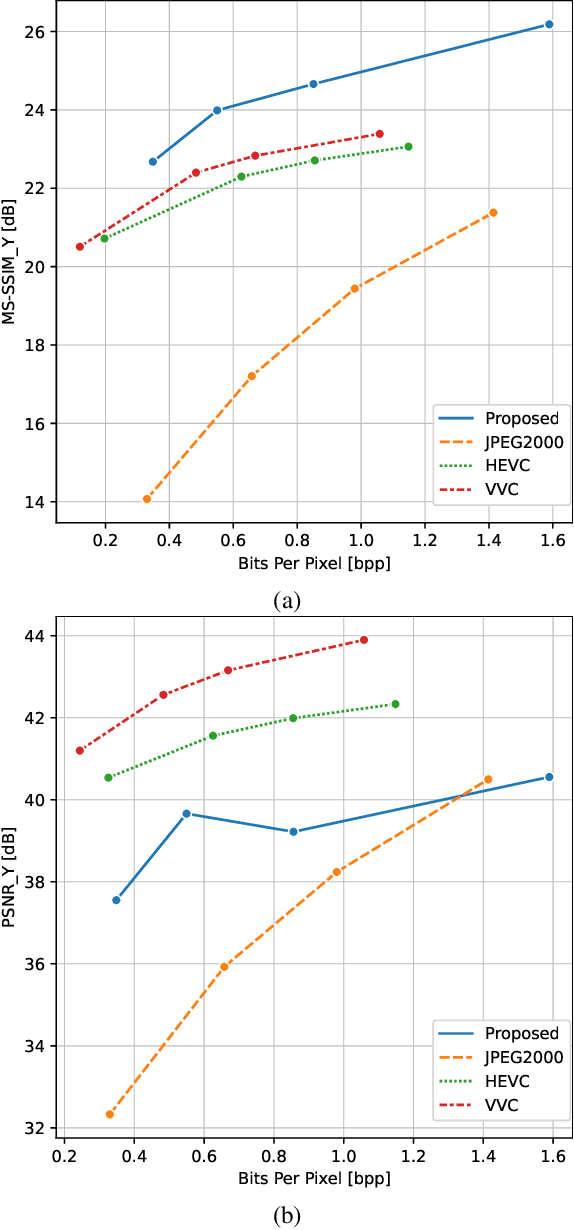

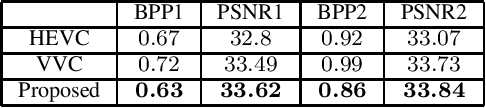
Light field technology has increasingly attracted the attention of the research community with its many possible applications. The lenslet array in commercial plenoptic cameras helps capture both the spatial and angular information of light rays in a single exposure. While the resulting high dimensionality of light field data enables its superior capabilities, it also impedes its extensive adoption. Hence, there is a compelling need for efficient compression of light field images. Existing solutions are commonly composed of several separate modules, some of which may not have been designed for the specific structure and quality of light field data. This increases the complexity of the codec and results in impractical decoding runtimes. We propose a new learning-based, disparity-aided model for compression of 4D light field images capable of parallel decoding. The model is end-to-end trainable, eliminating the need for hand-tuning separate modules and allowing joint learning of rate and distortion. The disparity-aided approach ensures the structural integrity of the reconstructed light fields. Comparisons with the state of the art show encouraging performance in terms of PSNR and MS-SSIM metrics. Also, there is a notable gain in the encoding and decoding runtimes. Source code is available at https://moha23.github.io/LF-DAAE.