 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesizing Light Field Video from Monocular Video
Jul 21, 2022
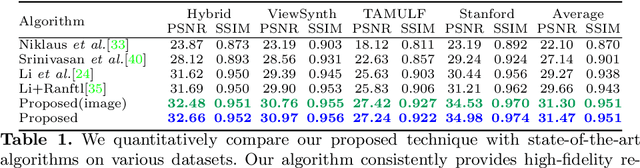


The hardware challenges associated with light-field(LF) imaging has made it difficult for consumers to access its benefits like applications in post-capture focus and aperture control. Learning-based techniques which solve the ill-posed problem of LF reconstruction from sparse (1, 2 or 4) views have significantly reduced the requirement for complex hardware. LF video reconstruction from sparse views poses a special challenge as acquiring ground-truth for training these models is hard. Hence, we propose a self-supervised learning-based algorithm for LF video reconstruction from monocular videos. We use self-supervised geometric, photometric and temporal consistency constraints inspired from a recent self-supervised technique for LF video reconstruction from stereo video. Additionally, we propose three key techniques that are relevant to our monocular video input. We propose an explicit disocclusion handling technique that encourages the network to inpaint disoccluded regions in a LF frame, using information from adjacent input temporal frames. This is crucial for a self-supervised technique as a single input frame does not contain any information about the disoccluded regions. We also propose an adaptive low-rank representation that provides a significant boost in performance by tailoring the representation to each input scene. Finally, we also propose a novel refinement block that is able to exploit the available LF image data using supervised learning to further refine the reconstruction quality. Our qualitative and quantitative analysis demonstrates the significance of each of the proposed building blocks and also the superior results compared to previous state-of-the-art monocular LF reconstruction techniques. We further validate our algorithm by reconstructing LF videos from monocular videos acquired using a commercial GoPro camera.
Improving Acquisition Speed of X-Ray Ptychography through Spatial Undersampling and Regularization
May 20, 2021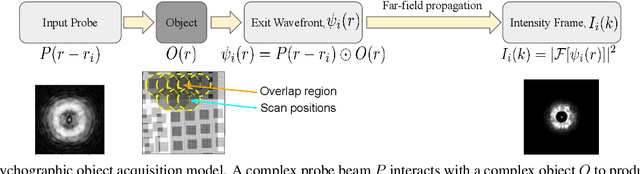
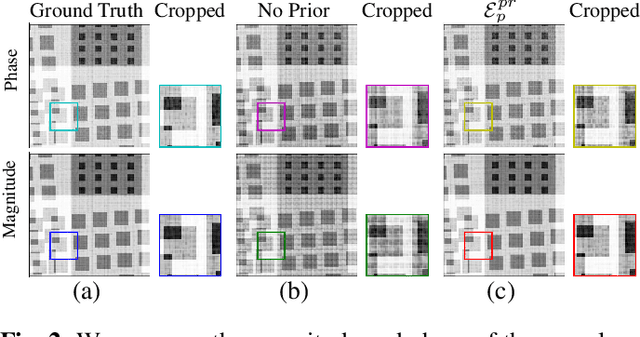

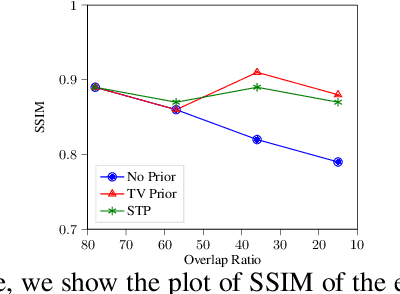
X-ray ptychography is one of the versatile techniques for nanometer resolution imaging. The magnitude of the diffraction patterns is recorded on a detector and the phase of the diffraction patterns is estimated using phase retrieval techniques. Most phase retrieval algorithms make the solution well-posed by relying on the constraints imposed by the overlapping region between neighboring diffraction pattern samples. As the overlap between neighboring diffraction patterns reduces, the problem becomes ill-posed and the object cannot be recovered. To avoid the ill-posedness, we investigate the effect of regularizing the phase retrieval algorithm with image priors for various overlap ratios between the neighboring diffraction patterns. We show that the object can be faithfully reconstructed at low overlap ratios by regularizing the phase retrieval algorithm with image priors such as Total-Variation and Structure Tensor Prior. We also show the effectiveness of our proposed algorithm on real data acquired from an IC chip with a coherent X-ray beam.
A Unified Framework for Compressive Video Recovery from Coded Exposure Techniques
Nov 11, 2020



Several coded exposure techniques have been proposed for acquiring high frame rate videos at low bandwidth. Most recently, a Coded-2-Bucket camera has been proposed that can acquire two compressed measurements in a single exposure, unlike previously proposed coded exposure techniques, which can acquire only a single measurement. Although two measurements are better than one for an effective video recovery, we are yet unaware of the clear advantage of two measurements, either quantitatively or qualitatively. Here, we propose a unified learning-based framework to make such a qualitative and quantitative comparison between those which capture only a single coded image (Flutter Shutter, Pixel-wise coded exposure) and those that capture two measurements per exposure (C2B). Our learning-based framework consists of a shift-variant convolutional layer followed by a fully convolutional deep neural network. Our proposed unified framework achieves the state of the art reconstructions in all three sensing techniques. Further analysis shows that when most scene points are static, the C2B sensor has a significant advantage over acquiring a single pixel-wise coded measurement. However, when most scene points undergo motion, the C2B sensor has only a marginal benefit over the single pixel-wise coded exposure measurement.
Video Reconstruction by Spatio-Temporal Fusion of Blurred-Coded Image Pair
Oct 20, 2020

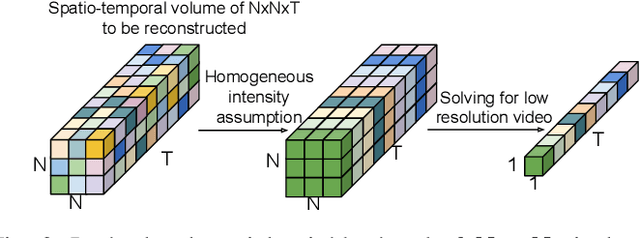

Learning-based methods have enabled the recovery of a video sequence from a single motion-blurred image or a single coded exposure image. Recovering video from a single motion-blurred image is a very ill-posed problem and the recovered video usually has many artifacts. In addition to this, the direction of motion is lost and it results in motion ambiguity. However, it has the advantage of fully preserving the information in the static parts of the scene. The traditional coded exposure framework is better-posed but it only samples a fraction of the space-time volume, which is at best 50% of the space-time volume. Here, we propose to use the complementary information present in the fully-exposed (blurred) image along with the coded exposure image to recover a high fidelity video without any motion ambiguity. Our framework consists of a shared encoder followed by an attention module to selectively combine the spatial information from the fully-exposed image with the temporal information from the coded image, which is then super-resolved to recover a non-ambiguous high-quality video. The input to our algorithm is a fully-exposed and coded image pair. Such an acquisition system already exists in the form of a Coded-two-bucket (C2B) camera. We demonstrate that our proposed deep learning approach using blurred-coded image pair produces much better results than those from just a blurred image or just a coded image.