 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoMP: Predicting Volumetric Mechanical Property Fields
Oct 27, 2025Physical simulation relies on spatially-varying mechanical properties, often laboriously hand-crafted. VoMP is a feed-forward method trained to predict Young's modulus ($E$), Poisson's ratio ($\nu$), and density ($\rho$) throughout the volume of 3D objects, in any representation that can be rendered and voxelized. VoMP aggregates per-voxel multi-view features and passes them to our trained Geometry Transformer to predict per-voxel material latent codes. These latents reside on a manifold of physically plausible materials, which we learn from a real-world dataset, guaranteeing the validity of decoded per-voxel materials. To obtain object-level training data, we propose an annotation pipeline combining knowledge from segmented 3D datasets, material databases, and a vision-language model, along with a new benchmark. Experiments show that VoMP estimates accurate volumetric properties, far outperforming prior art in accuracy and speed.
Sparse Voxels Rasterization: Real-time High-fidelity Radiance Field Rendering
Dec 05, 2024We propose an efficient radiance field rendering algorithm that incorporates a rasterization process on sparse voxels without neural networks or 3D Gaussians. There are two key contributions coupled with the proposed system. The first is to render sparse voxels in the correct depth order along pixel rays by using dynamic Morton ordering. This avoids the well-known popping artifact found in Gaussian splatting. Second, we adaptively fit sparse voxels to different levels of detail within scenes, faithfully reproducing scene details while achieving high rendering frame rates. Our method improves the previous neural-free voxel grid representation by over 4db PSNR and more than 10x rendering FPS speedup, achieving state-of-the-art comparable novel-view synthesis results. Additionally, our neural-free sparse voxels are seamlessly compatible with grid-based 3D processing algorithms. We achieve promising mesh reconstruction accuracy by integrating TSDF-Fusion and Marching Cubes into our sparse grid system.
Fast Monocular Scene Reconstruction with Global-Sparse Local-Dense Grids
May 22, 2023



Indoor scene reconstruction from monocular images has long been sought after by augmented reality and robotics developers. Recent advances in neural field representations and monocular priors have led to remarkable results in scene-level surface reconstructions. The reliance on Multilayer Perceptrons (MLP), however, significantly limits speed in training and rendering. In this work, we propose to directly use signed distance function (SDF) in sparse voxel block grids for fast and accurate scene reconstruction without MLPs. Our globally sparse and locally dense data structure exploits surfaces' spatial sparsity, enables cache-friendly queries, and allows direct extensions to multi-modal data such as color and semantic labels. To apply this representation to monocular scene reconstruction, we develop a scale calibration algorithm for fast geometric initialization from monocular depth priors. We apply differentiable volume rendering from this initialization to refine details with fast convergence. We also introduce efficient high-dimensional Continuous Random Fields (CRFs) to further exploit the semantic-geometry consistency between scene objects. Experiments show that our approach is 10x faster in training and 100x faster in rendering while achieving comparable accuracy to state-of-the-art neural implicit methods.
RTMV: A Ray-Traced Multi-View Synthetic Dataset for Novel View Synthesis
May 14, 2022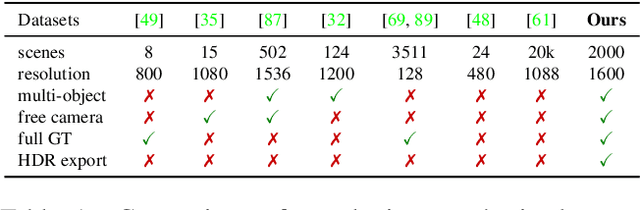


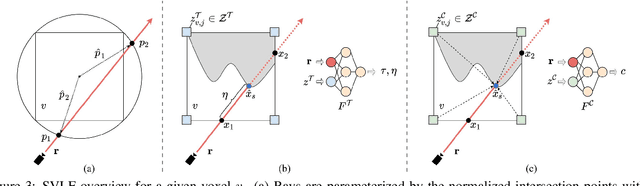
We present a large-scale synthetic dataset for novel view synthesis consisting of ~300k images rendered from nearly 2000 complex scenes using high-quality ray tracing at high resolution (1600 x 1600 pixels). The dataset is orders of magnitude larger than existing synthetic datasets for novel view synthesis, thus providing a large unified benchmark for both training and evaluation. Using 4 distinct sources of high-quality 3D meshes, the scenes of our dataset exhibit challenging variations in camera views, lighting, shape, materials, and textures. Because our dataset is too large for existing methods to process, we propose Sparse Voxel Light Field (SVLF), an efficient voxel-based light field approach for novel view synthesis that achieves comparable performance to NeRF on synthetic data, while being an order of magnitude faster to train and two orders of magnitude faster to render. SVLF achieves this speed by relying on a sparse voxel octree, careful voxel sampling (requiring only a handful of queries per ray), and reduced network structure; as well as ground truth depth maps at training time. Our dataset is generated by NViSII, a Python-based ray tracing renderer, which is designed to be simple for non-experts to use and share, flexible and powerful through its use of scripting, and able to create high-quality and physically-based rendered images. Experiments with a subset of our dataset allow us to compare standard methods like NeRF and mip-NeRF for single-scene modeling, and pixelNeRF for category-level modeling, pointing toward the need for future improvements in this area.
Neural Geometric Level of Detail: Real-time Rendering with Implicit 3D Shapes
Jan 26, 2021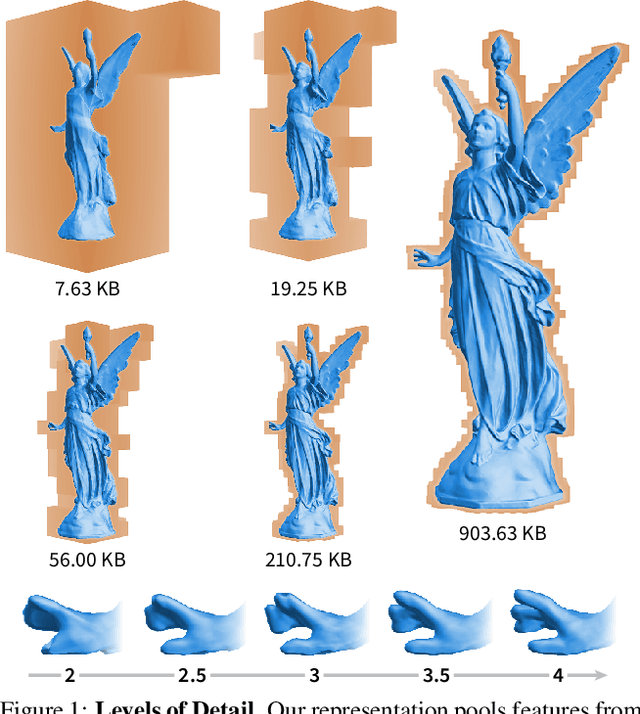
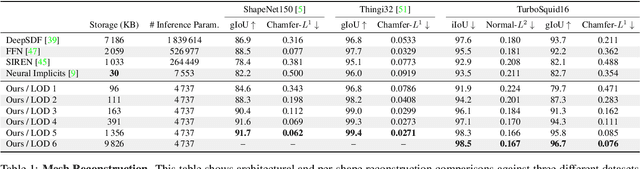

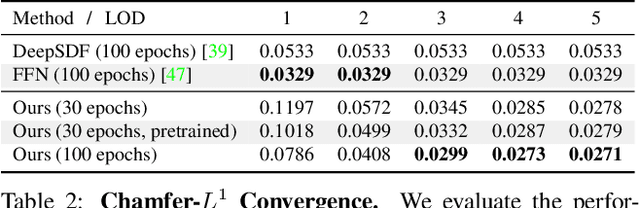
Neural signed distance functions (SDFs) are emerging as an effective representation for 3D shapes. State-of-the-art methods typically encode the SDF with a large, fixed-size neural network to approximate complex shapes with implicit surfaces. Rendering with these large networks is, however, computationally expensive since it requires many forward passes through the network for every pixel, making these representations impractical for real-time graphics. We introduce an efficient neural representation that, for the first time, enables real-time rendering of high-fidelity neural SDFs, while achieving state-of-the-art geometry reconstruction quality. We represent implicit surfaces using an octree-based feature volume which adaptively fits shapes with multiple discrete levels of detail (LODs), and enables continuous LOD with SDF interpolation. We further develop an efficient algorithm to directly render our novel neural SDF representation in real-time by querying only the necessary LODs with sparse octree traversal. We show that our representation is 2-3 orders of magnitude more efficient in terms of rendering speed compared to previous works. Furthermore, it produces state-of-the-art reconstruction quality for complex shapes under both 3D geometric and 2D image-space metrics.
Displacement-Invariant Cost Computation for Efficient Stereo Matching
Dec 01, 2020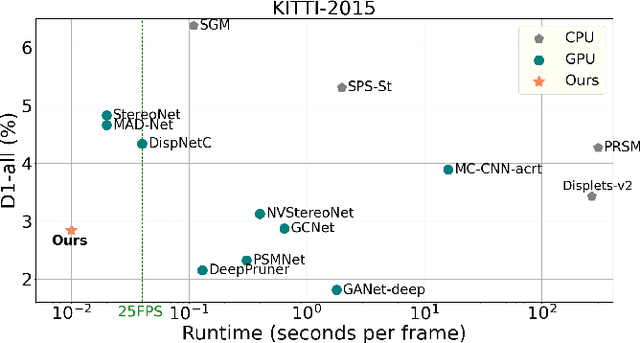

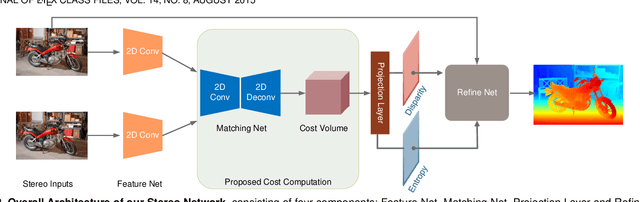
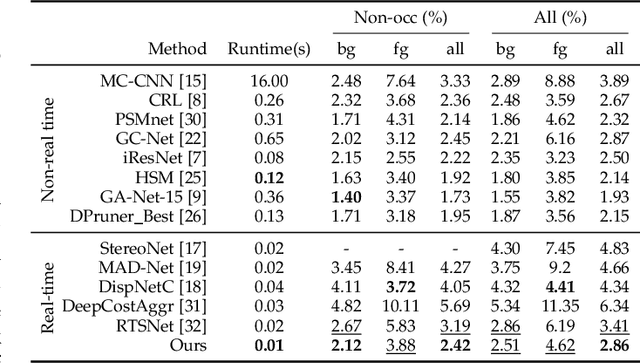
Although deep learning-based methods have dominated stereo matching leaderboards by yielding unprecedented disparity accuracy, their inference time is typically slow, on the order of seconds for a pair of 540p images. The main reason is that the leading methods employ time-consuming 3D convolutions applied to a 4D feature volume. A common way to speed up the computation is to downsample the feature volume, but this loses high-frequency details. To overcome these challenges, we propose a \emph{displacement-invariant cost computation module} to compute the matching costs without needing a 4D feature volume. Rather, costs are computed by applying the same 2D convolution network on each disparity-shifted feature map pair independently. Unlike previous 2D convolution-based methods that simply perform context mapping between inputs and disparity maps, our proposed approach learns to match features between the two images. We also propose an entropy-based refinement strategy to refine the computed disparity map, which further improves speed by avoiding the need to compute a second disparity map on the right image. Extensive experiments on standard datasets (SceneFlow, KITTI, ETH3D, and Middlebury) demonstrate that our method achieves competitive accuracy with much less inference time. On typical image sizes, our method processes over 100 FPS on a desktop GPU, making our method suitable for time-critical applications such as autonomous driving. We also show that our approach generalizes well to unseen datasets, outperforming 4D-volumetric methods.
Improving Deep Stereo Network Generalization with Geometric Priors
Aug 25, 2020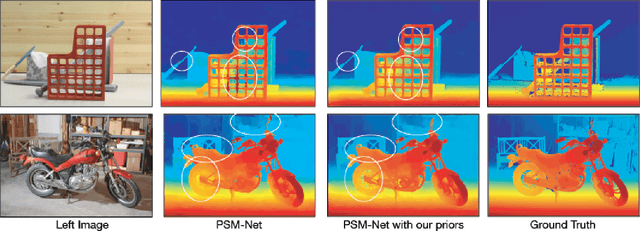
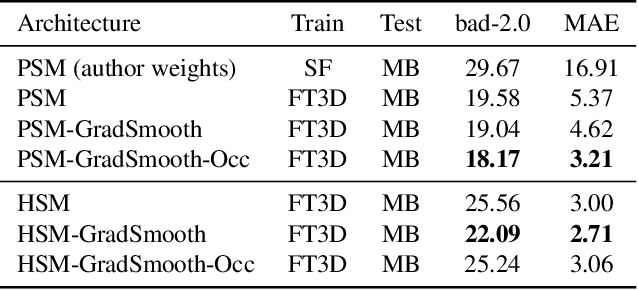
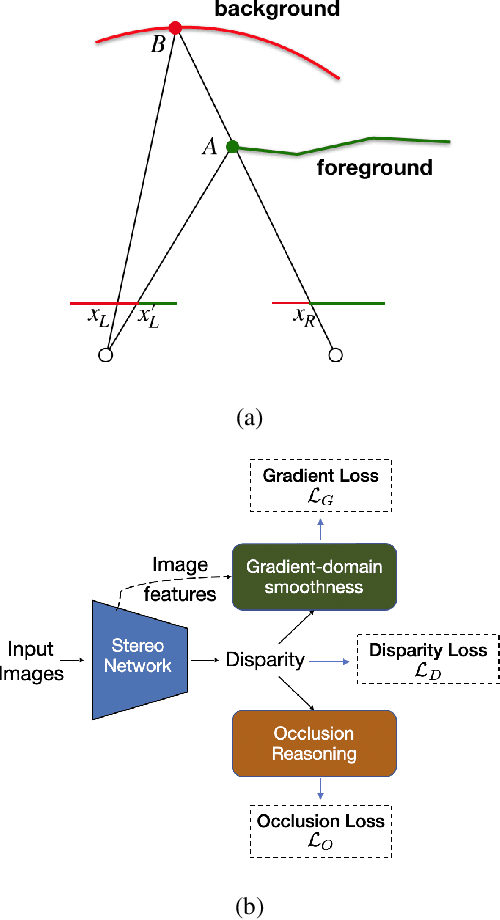

End-to-end deep learning methods have advanced stereo vision in recent years and obtained excellent results when the training and test data are similar. However, large datasets of diverse real-world scenes with dense ground truth are difficult to obtain and currently not publicly available to the research community. As a result, many algorithms rely on small real-world datasets of similar scenes or synthetic datasets, but end-to-end algorithms trained on such datasets often generalize poorly to different images that arise in real-world applications. As a step towards addressing this problem, we propose to incorporate prior knowledge of scene geometry into an end-to-end stereo network to help networks generalize better. For a given network, we explicitly add a gradient-domain smoothness prior and occlusion reasoning into the network training, while the architecture remains unchanged during inference. Experimentally, we show consistent improvements if we train on synthetic datasets and test on the Middlebury (real images) dataset. Noticeably, we improve PSM-Net accuracy on Middlebury from 5.37 MAE to 3.21 MAE without sacrificing speed.
NRMVS: Non-Rigid Multi-View Stereo
Jan 12, 2019

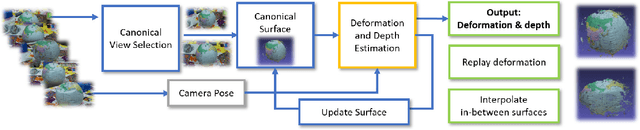

Scene reconstruction from unorganized RGB images is an important task in many computer vision applications. Multi-view Stereo (MVS) is a common solution in photogrammetry applications for the dense reconstruction of a static scene. The static scene assumption, however, limits the general applicability of MVS algorithms, as many day-to-day scenes undergo non-rigid motion, e.g., clothes, faces, or human bodies. In this paper, we open up a new challenging direction: dense 3D reconstruction of scenes with non-rigid changes observed from arbitrary, sparse, and wide-baseline views. We formulate the problem as a joint optimization of deformation and depth estimation, using deformation graphs as the underlying representation. We propose a new sparse 3D to 2D matching technique, together with a dense patch-match evaluation scheme to estimate deformation and depth with photometric consistency. We show that creating a dense 4D structure from a few RGB images with non-rigid changes is possible, and demonstrate that our method can be used to interpolate novel deformed scenes from various combinations of these deformation estimates derived from the sparse views.