 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactorized Implicit Global Convolution for Automotive Computational Fluid Dynamics Prediction
Feb 06, 2025Computational Fluid Dynamics (CFD) is crucial for automotive design, requiring the analysis of large 3D point clouds to study how vehicle geometry affects pressure fields and drag forces. However, existing deep learning approaches for CFD struggle with the computational complexity of processing high-resolution 3D data. We propose Factorized Implicit Global Convolution (FIGConv), a novel architecture that efficiently solves CFD problems for very large 3D meshes with arbitrary input and output geometries. FIGConv achieves quadratic complexity $O(N^2)$, a significant improvement over existing 3D neural CFD models that require cubic complexity $O(N^3)$. Our approach combines Factorized Implicit Grids to approximate high-resolution domains, efficient global convolutions through 2D reparameterization, and a U-shaped architecture for effective information gathering and integration. We validate our approach on the industry-standard Ahmed body dataset and the large-scale DrivAerNet dataset. In DrivAerNet, our model achieves an $R^2$ value of 0.95 for drag prediction, outperforming the previous state-of-the-art by a significant margin. This represents a 40% improvement in relative mean squared error and a 70% improvement in absolute mean squared error over previous methods.
PredictionNet: Real-Time Joint Probabilistic Traffic Prediction for Planning, Control, and Simulation
Sep 23, 2021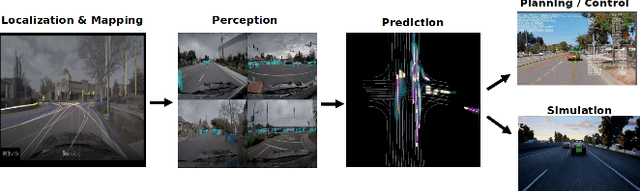
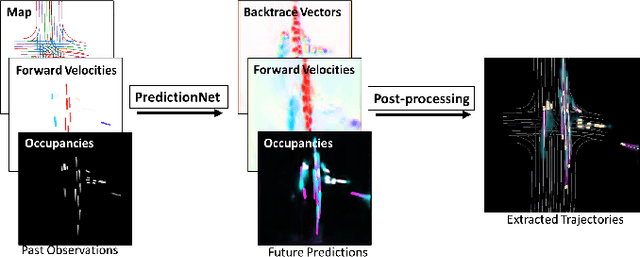
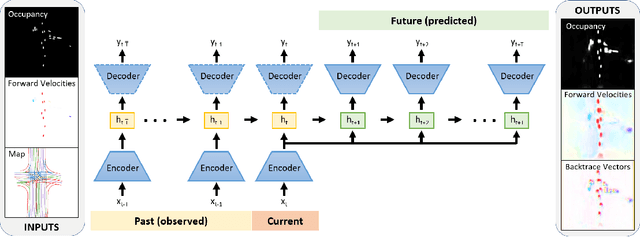

Predicting the future motion of traffic agents is crucial for safe and efficient autonomous driving. To this end, we present PredictionNet, a deep neural network (DNN) that predicts the motion of all surrounding traffic agents together with the ego-vehicle's motion. All predictions are probabilistic and are represented in a simple top-down rasterization that allows an arbitrary number of agents. Conditioned on a multilayer map with lane information, the network outputs future positions, velocities, and backtrace vectors jointly for all agents including the ego-vehicle in a single pass. Trajectories are then extracted from the output. The network can be used to simulate realistic traffic, and it produces competitive results on popular benchmarks. More importantly, it has been used to successfully control a real-world vehicle for hundreds of kilometers, by combining it with a motion planning/control subsystem. The network runs faster than real-time on an embedded GPU, and the system shows good generalization (across sensory modalities and locations) due to the choice of input representation. Furthermore, we demonstrate that by extending the DNN with reinforcement learning (RL), it can better handle rare or unsafe events like aggressive maneuvers and crashes.
Displacement-Invariant Cost Computation for Efficient Stereo Matching
Dec 01, 2020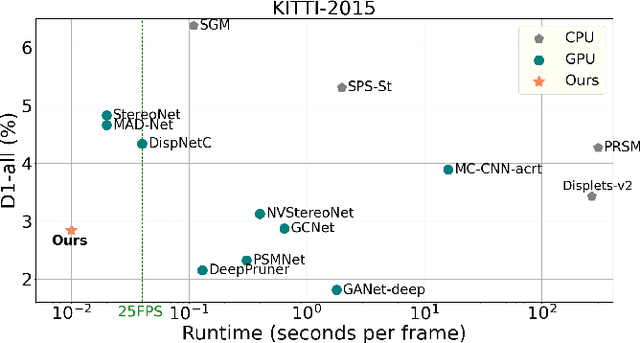

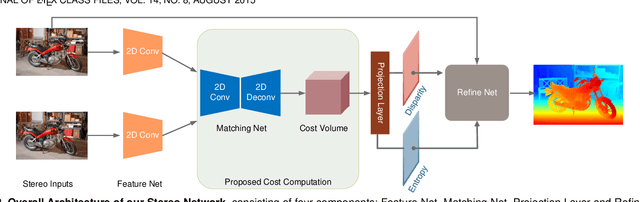
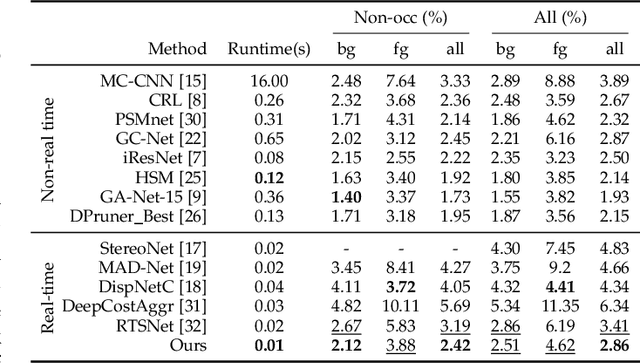
Although deep learning-based methods have dominated stereo matching leaderboards by yielding unprecedented disparity accuracy, their inference time is typically slow, on the order of seconds for a pair of 540p images. The main reason is that the leading methods employ time-consuming 3D convolutions applied to a 4D feature volume. A common way to speed up the computation is to downsample the feature volume, but this loses high-frequency details. To overcome these challenges, we propose a \emph{displacement-invariant cost computation module} to compute the matching costs without needing a 4D feature volume. Rather, costs are computed by applying the same 2D convolution network on each disparity-shifted feature map pair independently. Unlike previous 2D convolution-based methods that simply perform context mapping between inputs and disparity maps, our proposed approach learns to match features between the two images. We also propose an entropy-based refinement strategy to refine the computed disparity map, which further improves speed by avoiding the need to compute a second disparity map on the right image. Extensive experiments on standard datasets (SceneFlow, KITTI, ETH3D, and Middlebury) demonstrate that our method achieves competitive accuracy with much less inference time. On typical image sizes, our method processes over 100 FPS on a desktop GPU, making our method suitable for time-critical applications such as autonomous driving. We also show that our approach generalizes well to unseen datasets, outperforming 4D-volumetric methods.
On the Importance of Stereo for Accurate Depth Estimation: An Efficient Semi-Supervised Deep Neural Network Approach
Apr 20, 2018



We revisit the problem of visual depth estimation in the context of autonomous vehicles. Despite the progress on monocular depth estimation in recent years, we show that the gap between monocular and stereo depth accuracy remains large$-$a particularly relevant result due to the prevalent reliance upon monocular cameras by vehicles that are expected to be self-driving. We argue that the challenges of removing this gap are significant, owing to fundamental limitations of monocular vision. As a result, we focus our efforts on depth estimation by stereo. We propose a novel semi-supervised learning approach to training a deep stereo neural network, along with a novel architecture containing a machine-learned argmax layer and a custom runtime (that will be shared publicly) that enables a smaller version of our stereo DNN to run on an embedded GPU. Competitive results are shown on the KITTI 2015 stereo dataset. We also evaluate the recent progress of stereo algorithms by measuring the impact upon accuracy of various design criteria.
Toward Low-Flying Autonomous MAV Trail Navigation using Deep Neural Networks for Environmental Awareness
Jul 22, 2017
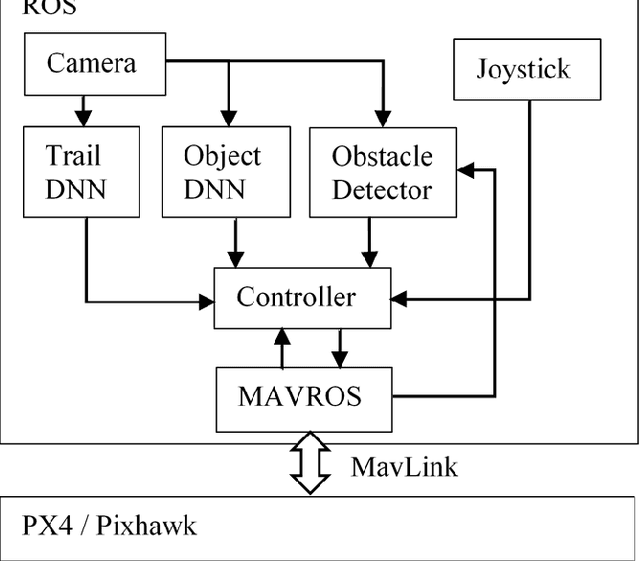


We present a micro aerial vehicle (MAV) system, built with inexpensive off-the-shelf hardware, for autonomously following trails in unstructured, outdoor environments such as forests. The system introduces a deep neural network (DNN) called TrailNet for estimating the view orientation and lateral offset of the MAV with respect to the trail center. The DNN-based controller achieves stable flight without oscillations by avoiding overconfident behavior through a loss function that includes both label smoothing and entropy reward. In addition to the TrailNet DNN, the system also utilizes vision modules for environmental awareness, including another DNN for object detection and a visual odometry component for estimating depth for the purpose of low-level obstacle detection. All vision systems run in real time on board the MAV via a Jetson TX1. We provide details on the hardware and software used, as well as implementation details. We present experiments showing the ability of our system to navigate forest trails more robustly than previous techniques, including autonomous flights of 1 km.