 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuadSwarm: A Modular Multi-Quadrotor Simulator for Deep Reinforcement Learning with Direct Thrust Control
Jun 15, 2023Reinforcement learning (RL) has shown promise in creating robust policies for robotics tasks. However, contemporary RL algorithms are data-hungry, often requiring billions of environment transitions to train successful policies. This necessitates the use of fast and highly-parallelizable simulators. In addition to speed, such simulators need to model the physics of the robots and their interaction with the environment to a level acceptable for transferring policies learned in simulation to reality. We present QuadSwarm, a fast, reliable simulator for research in single and multi-robot RL for quadrotors that addresses both issues. QuadSwarm, with fast forward-dynamics propagation decoupled from rendering, is designed to be highly parallelizable such that throughput scales linearly with additional compute. It provides multiple components tailored toward multi-robot RL, including diverse training scenarios, and provides domain randomization to facilitate the development and sim2real transfer of multi-quadrotor control policies. Initial experiments suggest that QuadSwarm achieves over 48,500 simulation samples per second (SPS) on a single quadrotor and over 62,000 SPS on eight quadrotors on a 16-core CPU. The code can be found in https://github.com/Zhehui-Huang/quad-swarm-rl.
Cognitive Architecture for Decision-Making Based on Brain Principles Programming (in Russian)
Feb 18, 2023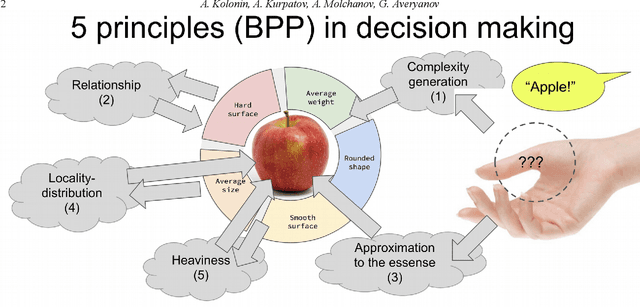
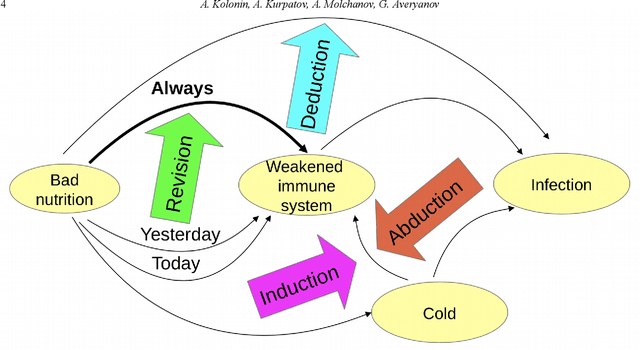
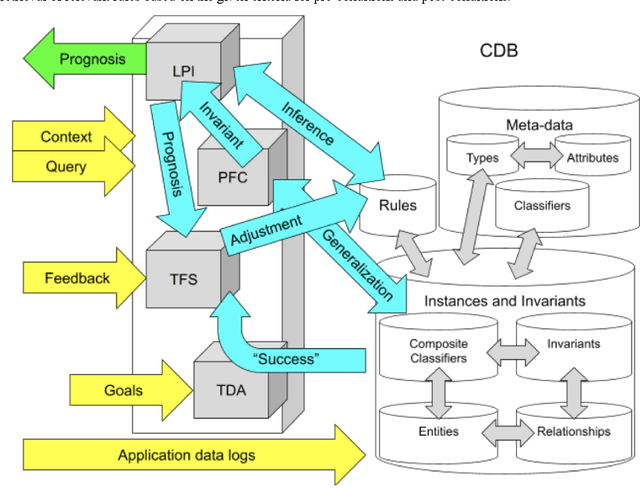

We describe a cognitive architecture intended to solve a wide range of problems based on the five identified principles of brain activity, with their implementation in three subsystems: logical-probabilistic inference, probabilistic formal concepts, and functional systems theory. Building an architecture involves the implementation of a task-driven approach that allows defining the target functions of applied applications as tasks formulated in terms of the operating environment corresponding to the task, expressed in the applied ontology. We provide a basic ontology for a number of practical applications as well as for the subject domain ontologies based upon it, describe the proposed architecture, and give possible examples of the execution of these applications in this architecture.
* 13 pages, 5 figures, Russian language, original English version of the paper is presented on BICA-2023 - 2023 Annual International Conference on Brain-Inspired Cognitive Architectures for Artificial Intelligence, the 14th Annual Meeting of the BICA Society
Cognitive Architecture for Decision-Making Based on Brain Principles Programming
Apr 17, 2022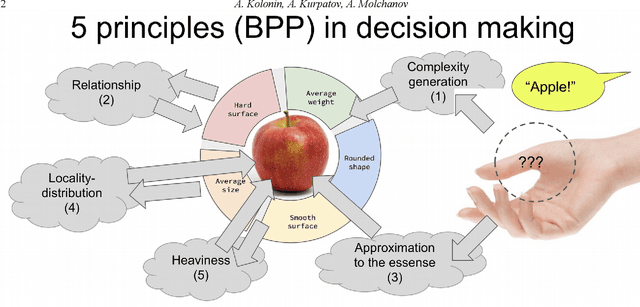

We describe a cognitive architecture intended to solve a wide range of problems based on the five identified principles of brain activity, with their implementation in three subsystems: logical-probabilistic inference, probabilistic formal concepts, and functional systems theory. Building an architecture involves the implementation of a task-driven approach that allows defining the target functions of applied applications as tasks formulated in terms of the operating environment corresponding to the task, expressed in the applied ontology. We provide a basic ontology for a number of practical applications as well as for the subject domain ontologies based upon it, describe the proposed architecture, and give possible examples of the execution of these applications in this architecture.
Brain Principles Programming
Mar 14, 2022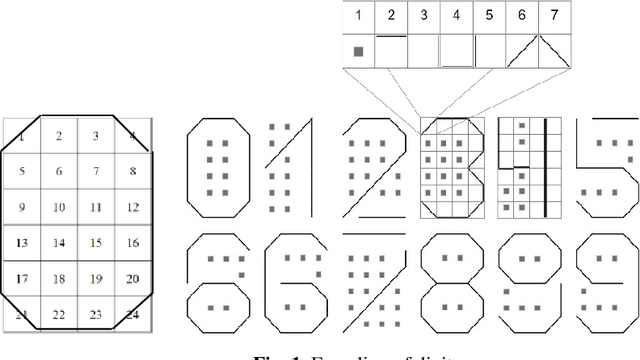
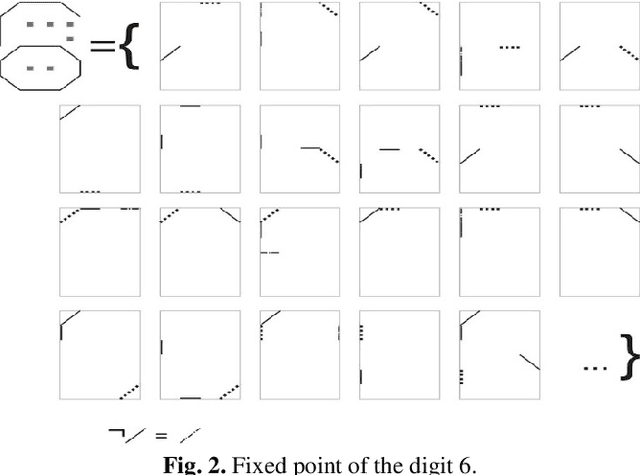
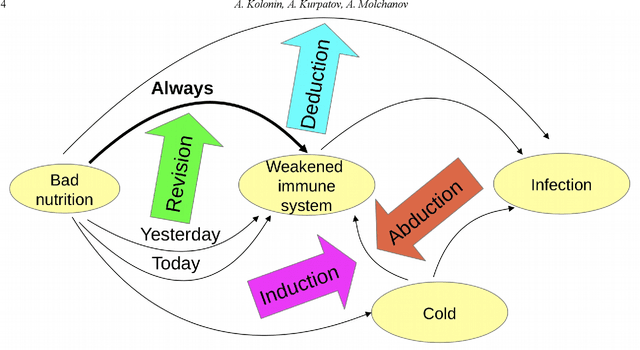
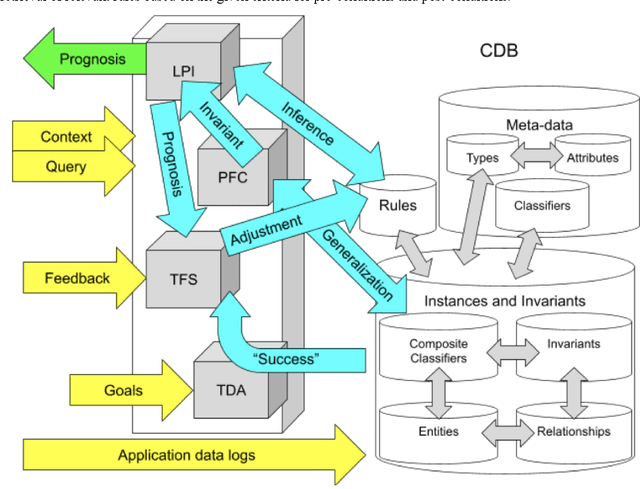
In the monograph, STRONG ARTIFICIAL INTELLIGENCE. On the Approaches to Superintelligence, published by Sberbank, provides a cross-disciplinary review of general artificial intelligence. As an anthropomorphic direction of research, it considers Brain Principles Programming, BPP) the formalization of universal mechanisms (principles) of the brain's work with information, which are implemented at all levels of the organization of nervous tissue. This monograph provides a formalization of these principles in terms of the category theory. However, this formalization is not enough to develop algorithms for working with information. In this paper, for the description and modeling of Brain Principles Programming, it is proposed to apply mathematical models and algorithms developed by us earlier that model cognitive functions, which are based on well-known physiological, psychological and other natural science theories. The paper uses mathematical models and algorithms of the following theories: P.K.Anokhin's Theory of Functional Brain Systems, Eleonor Rosh's prototypical categorization theory, Bob Rehter's theory of causal models and natural classification. As a result, the formalization of the BPP is obtained and computer examples are given that demonstrate the algorithm's operation.
PredictionNet: Real-Time Joint Probabilistic Traffic Prediction for Planning, Control, and Simulation
Sep 23, 2021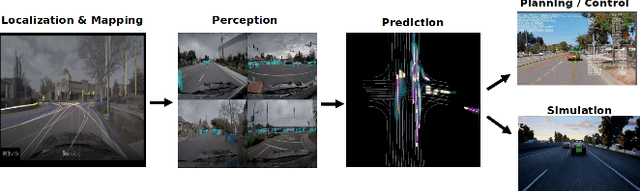
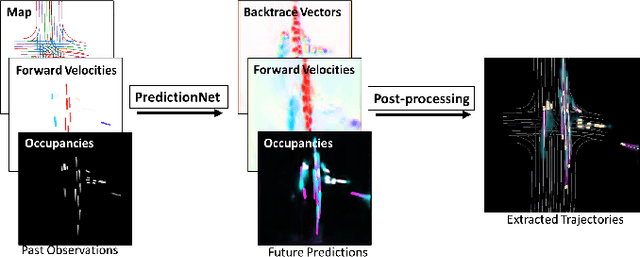
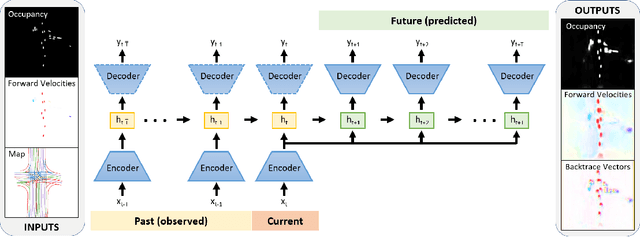

Predicting the future motion of traffic agents is crucial for safe and efficient autonomous driving. To this end, we present PredictionNet, a deep neural network (DNN) that predicts the motion of all surrounding traffic agents together with the ego-vehicle's motion. All predictions are probabilistic and are represented in a simple top-down rasterization that allows an arbitrary number of agents. Conditioned on a multilayer map with lane information, the network outputs future positions, velocities, and backtrace vectors jointly for all agents including the ego-vehicle in a single pass. Trajectories are then extracted from the output. The network can be used to simulate realistic traffic, and it produces competitive results on popular benchmarks. More importantly, it has been used to successfully control a real-world vehicle for hundreds of kilometers, by combining it with a motion planning/control subsystem. The network runs faster than real-time on an embedded GPU, and the system shows good generalization (across sensory modalities and locations) due to the choice of input representation. Furthermore, we demonstrate that by extending the DNN with reinforcement learning (RL), it can better handle rare or unsafe events like aggressive maneuvers and crashes.
Decentralized Control of Quadrotor Swarms with End-to-end Deep Reinforcement Learning
Sep 16, 2021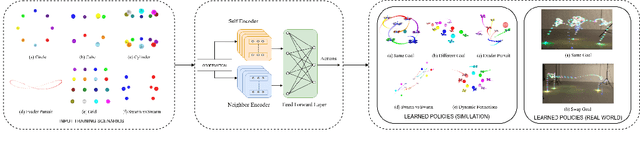
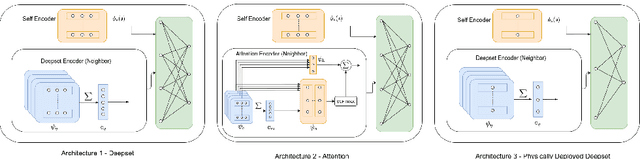

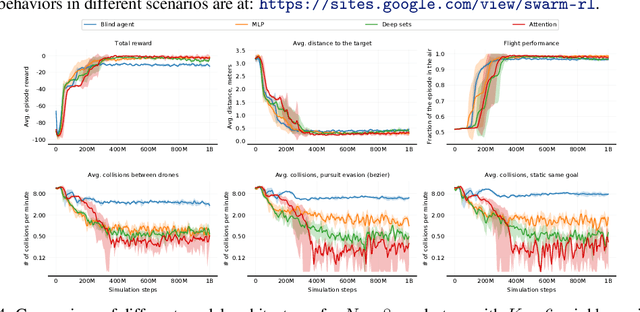
We demonstrate the possibility of learning drone swarm controllers that are zero-shot transferable to real quadrotors via large-scale multi-agent end-to-end reinforcement learning. We train policies parameterized by neural networks that are capable of controlling individual drones in a swarm in a fully decentralized manner. Our policies, trained in simulated environments with realistic quadrotor physics, demonstrate advanced flocking behaviors, perform aggressive maneuvers in tight formations while avoiding collisions with each other, break and re-establish formations to avoid collisions with moving obstacles, and efficiently coordinate in pursuit-evasion tasks. We analyze, in simulation, how different model architectures and parameters of the training regime influence the final performance of neural swarms. We demonstrate the successful deployment of the model learned in simulation to highly resource-constrained physical quadrotors performing stationkeeping and goal swapping behaviors. Code and video demonstrations are available at the project website https://sites.google.com/view/swarm-rl.
Generalized Inner Loop Meta-Learning
Oct 07, 2019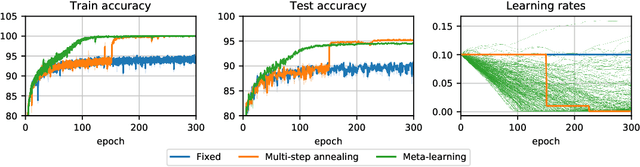

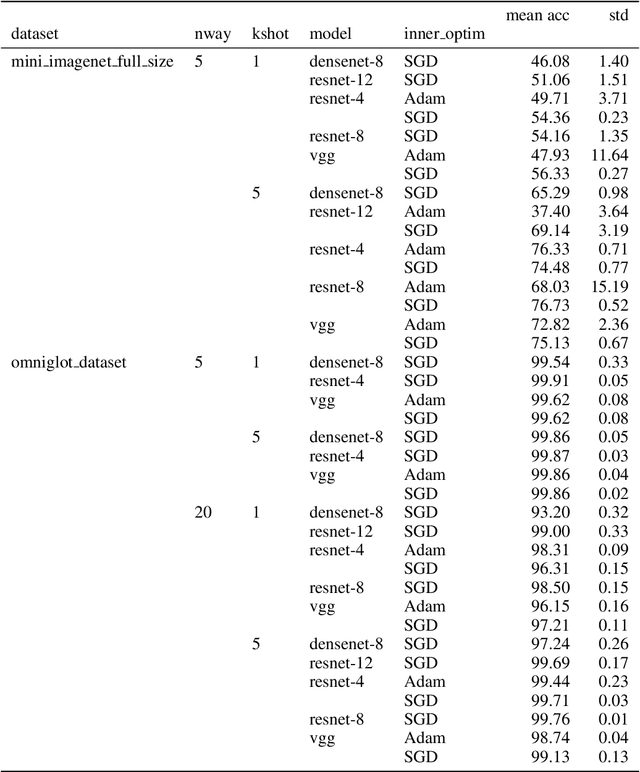

Many (but not all) approaches self-qualifying as "meta-learning" in deep learning and reinforcement learning fit a common pattern of approximating the solution to a nested optimization problem. In this paper, we give a formalization of this shared pattern, which we call GIMLI, prove its general requirements, and derive a general-purpose algorithm for implementing similar approaches. Based on this analysis and algorithm, we describe a library of our design, higher, which we share with the community to assist and enable future research into these kinds of meta-learning approaches. We end the paper by showcasing the practical applications of this framework and library through illustrative experiments and ablation studies which they facilitate.
Meta-Learning via Learned Loss
Jun 12, 2019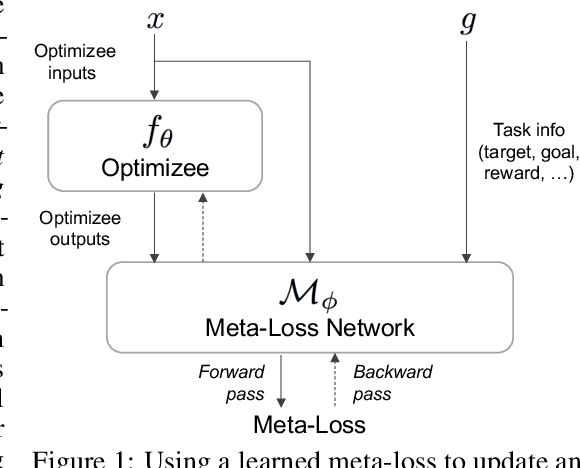
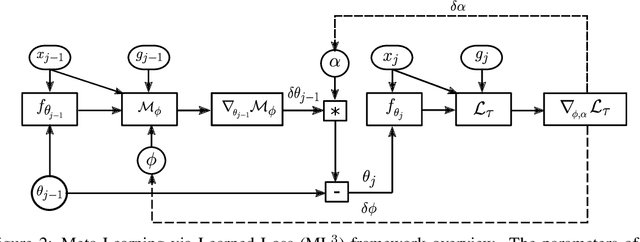
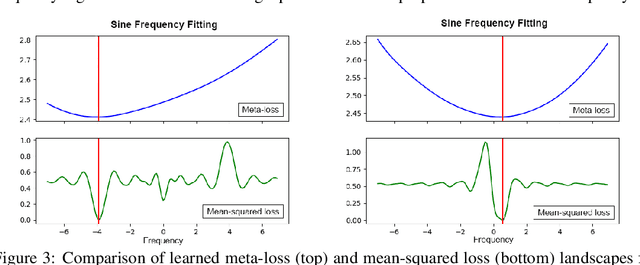
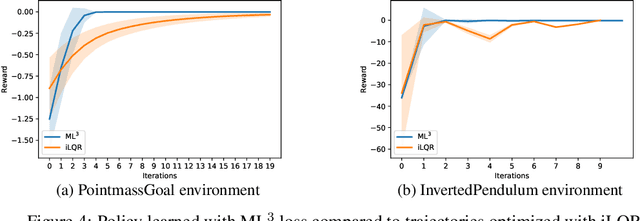
We present a meta-learning approach based on learning an adaptive, high-dimensional loss function that can generalize across multiple tasks and different model architectures. We develop a fully differentiable pipeline for learning a loss function targeted at maximizing the performance of an optimizee trained using this loss function. We observe that the loss landscape produced by our learned loss significantly improves upon the original task-specific loss. We evaluate our method on supervised and reinforcement learning tasks. Furthermore, we show that our pipeline is able to operate in sparse reward and self-supervised reinforcement learning scenarios.
Sim-to--Real: Transfer of Low-Level Robust Control Policies to Multiple Quadrotors
Apr 16, 2019
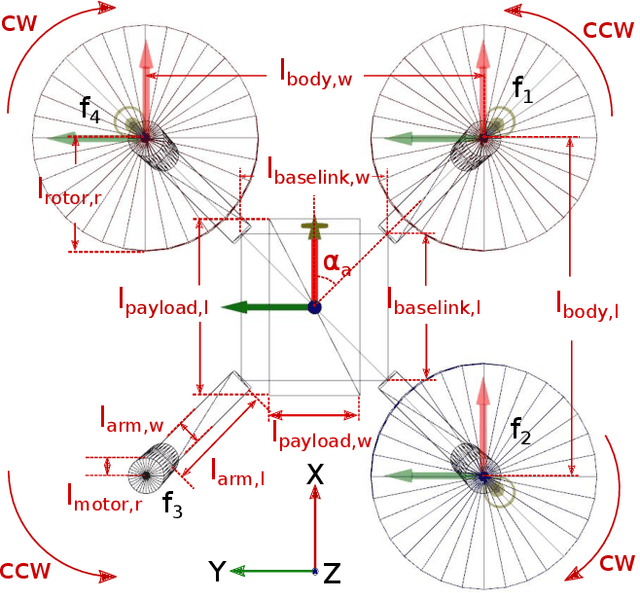
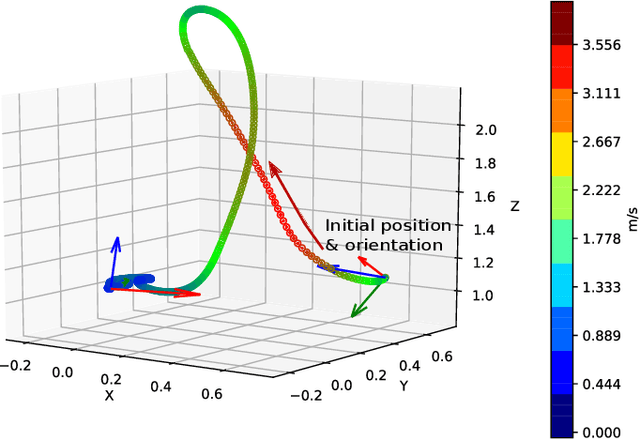
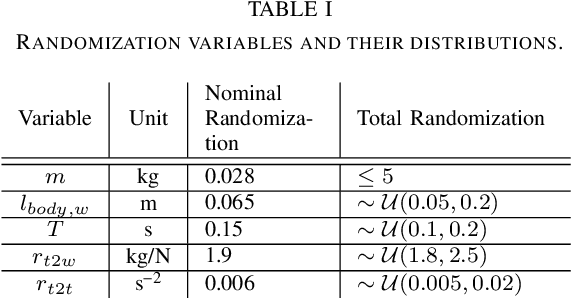
Quadrotor stabilizing controllers often require careful, model-specific tuning for safe operation. We use reinforcement learning to train policies in simulation that transfer remarkably well to multiple different physical quadrotors. Our policies are low-level, i.e., we map the rotorcrafts' state directly to the motor outputs. The trained control policies are very robust to external disturbances and can withstand harsh initial conditions such as throws. We show how different training methodologies (change of the cost function, modeling of noise, use of domain randomization) might affect flight performance. To the best of our knowledge, this is the first work that demonstrates that a simple neural network can learn a robust stabilizing low-level quadrotor controller (without the use of a stabilizing PD controller) that is shown to generalize to multiple quadrotors.
Synthetically Trained Neural Networks for Learning Human-Readable Plans from Real-World Demonstrations
Jul 10, 2018

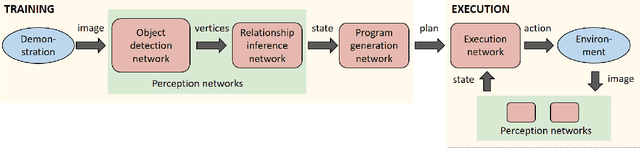
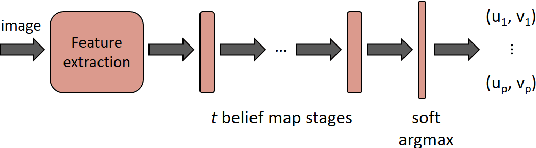
We present a system to infer and execute a human-readable program from a real-world demonstration. The system consists of a series of neural networks to perform perception, program generation, and program execution. Leveraging convolutional pose machines, the perception network reliably detects the bounding cuboids of objects in real images even when severely occluded, after training only on synthetic images using domain randomization. To increase the applicability of the perception network to new scenarios, the network is formulated to predict in image space rather than in world space. Additional networks detect relationships between objects, generate plans, and determine actions to reproduce a real-world demonstration. The networks are trained entirely in simulation, and the system is tested in the real world on the pick-and-place problem of stacking colored cubes using a Baxter robot.