 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeB-DENSE: Branching For Dense Ensemble Network Learning
Feb 17, 2026Inspired by non-equilibrium thermodynamics, diffusion models have achieved state-of-the-art performance in generative modeling. However, their iterative sampling nature results in high inference latency. While recent distillation techniques accelerate sampling, they discard intermediate trajectory steps. This sparse supervision leads to a loss of structural information and introduces significant discretization errors. To mitigate this, we propose B-DENSE, a novel framework that leverages multi-branch trajectory alignment. We modify the student architecture to output $K$-fold expanded channels, where each subset corresponds to a specific branch representing a discrete intermediate step in the teacher's trajectory. By training these branches to simultaneously map to the entire sequence of the teacher's target timesteps, we enforce dense intermediate trajectory alignment. Consequently, the student model learns to navigate the solution space from the earliest stages of training, demonstrating superior image generation quality compared to baseline distillation frameworks.
QuadSwarm: A Modular Multi-Quadrotor Simulator for Deep Reinforcement Learning with Direct Thrust Control
Jun 15, 2023Reinforcement learning (RL) has shown promise in creating robust policies for robotics tasks. However, contemporary RL algorithms are data-hungry, often requiring billions of environment transitions to train successful policies. This necessitates the use of fast and highly-parallelizable simulators. In addition to speed, such simulators need to model the physics of the robots and their interaction with the environment to a level acceptable for transferring policies learned in simulation to reality. We present QuadSwarm, a fast, reliable simulator for research in single and multi-robot RL for quadrotors that addresses both issues. QuadSwarm, with fast forward-dynamics propagation decoupled from rendering, is designed to be highly parallelizable such that throughput scales linearly with additional compute. It provides multiple components tailored toward multi-robot RL, including diverse training scenarios, and provides domain randomization to facilitate the development and sim2real transfer of multi-quadrotor control policies. Initial experiments suggest that QuadSwarm achieves over 48,500 simulation samples per second (SPS) on a single quadrotor and over 62,000 SPS on eight quadrotors on a 16-core CPU. The code can be found in https://github.com/Zhehui-Huang/quad-swarm-rl.
Decentralized Control of Quadrotor Swarms with End-to-end Deep Reinforcement Learning
Sep 16, 2021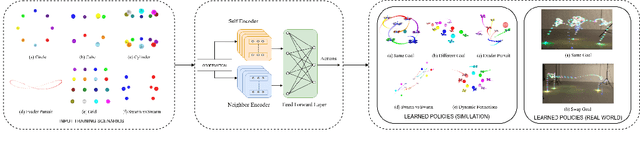
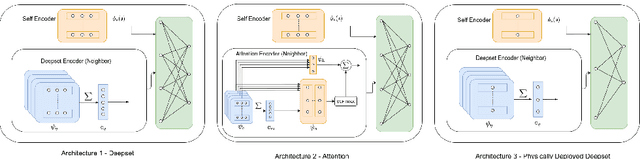

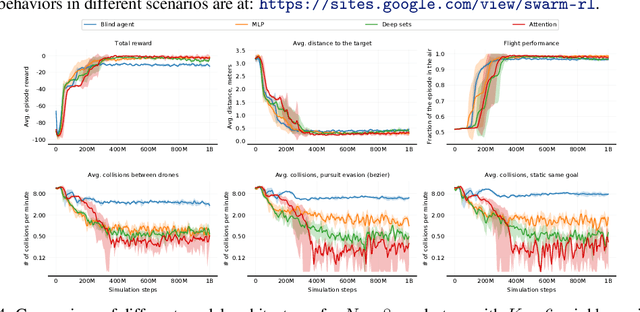
We demonstrate the possibility of learning drone swarm controllers that are zero-shot transferable to real quadrotors via large-scale multi-agent end-to-end reinforcement learning. We train policies parameterized by neural networks that are capable of controlling individual drones in a swarm in a fully decentralized manner. Our policies, trained in simulated environments with realistic quadrotor physics, demonstrate advanced flocking behaviors, perform aggressive maneuvers in tight formations while avoiding collisions with each other, break and re-establish formations to avoid collisions with moving obstacles, and efficiently coordinate in pursuit-evasion tasks. We analyze, in simulation, how different model architectures and parameters of the training regime influence the final performance of neural swarms. We demonstrate the successful deployment of the model learned in simulation to highly resource-constrained physical quadrotors performing stationkeeping and goal swapping behaviors. Code and video demonstrations are available at the project website https://sites.google.com/view/swarm-rl.
Sample Factory: Egocentric 3D Control from Pixels at 100000 FPS with Asynchronous Reinforcement Learning
Jun 23, 2020
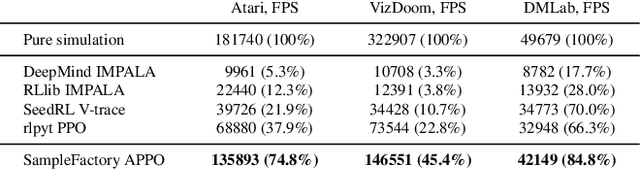


Increasing the scale of reinforcement learning experiments has allowed researchers to achieve unprecedented results in both training sophisticated agents for video games, and in sim-to-real transfer for robotics. Typically such experiments rely on large distributed systems and require expensive hardware setups, limiting wider access to this exciting area of research. In this work we aim to solve this problem by optimizing the efficiency and resource utilization of reinforcement learning algorithms instead of relying on distributed computation. We present the "Sample Factory", a high-throughput training system optimized for a single-machine setting. Our architecture combines a highly efficient, asynchronous, GPU-based sampler with off-policy correction techniques, allowing us to achieve throughput higher than $10^5$ environment frames/second on non-trivial control problems in 3D without sacrificing sample efficiency. We extend Sample Factory to support self-play and population-based training and apply these techniques to train highly capable agents for a multiplayer first-person shooter game. The source code is available at https://github.com/alex-petrenko/sample-factory
Grounding-Tracking-Integration
Dec 13, 2019
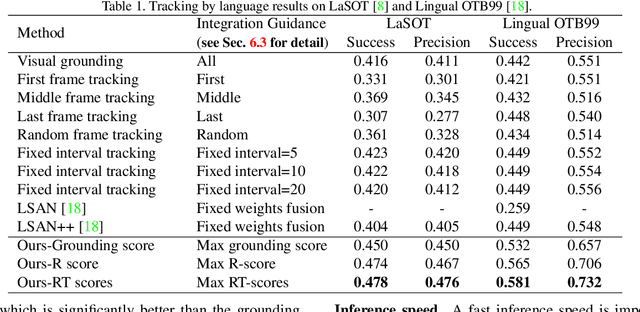
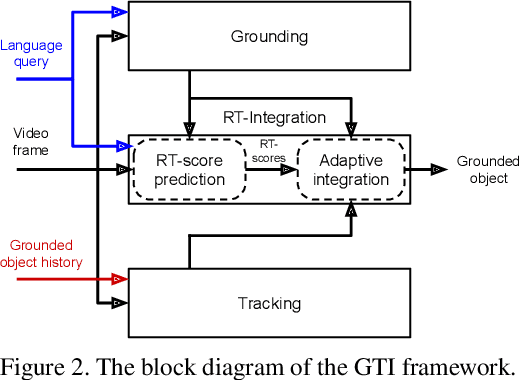
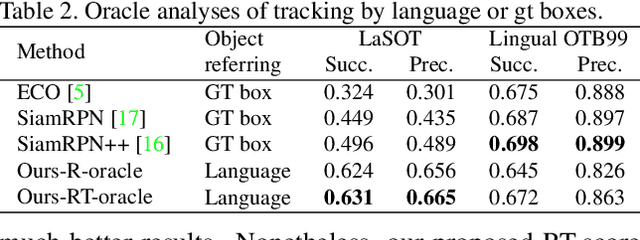
In this paper, we study tracking by language that localizes the target box sequence in a video based on a language query. We propose a framework called GTI that decomposes the problem into three sub-tasks: Grounding, Tracking and Integration. The three sub-task modules operate simultaneously and predict the box sequence frame-by-frame. "Grounding" predicts the referred region directly from the language query. "Tracking" localizes the target based on the history of the grounded regions in previous frames. "Integration" generates final predictions by synergistically combining grounding and tracking. With the "integration" task as the key, we explore how to indicate the quality of the grounded regions in each frame and achieve the desired mutually beneficial combination. To this end, we propose an "RT-integration" method that defines and predicts two scores to guide the integration: 1) R-score represents the Region correctness whether the grounding prediction accurately covers the target, and 2) T-score represents the Template quality whether the region provides informative visual cues to improve tracking in future frames. We present our real-time GTI implementation with the proposed RT-integration, and benchmark the framework on LaSOT and Lingual OTB99 with highly promising results. Moreover, a disambiguated version of LaSOT queries can be used to facilitate future tracking by language studies.