 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding-Tracking-Integration
Paper and Code
Dec 13, 2019
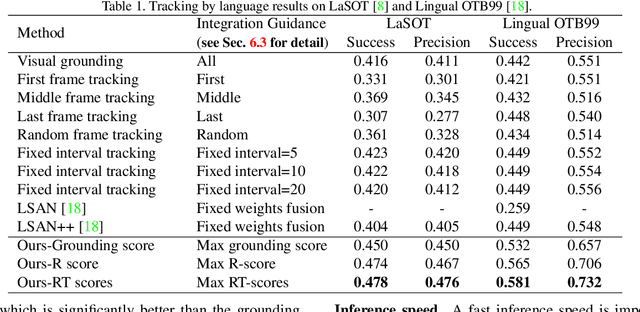
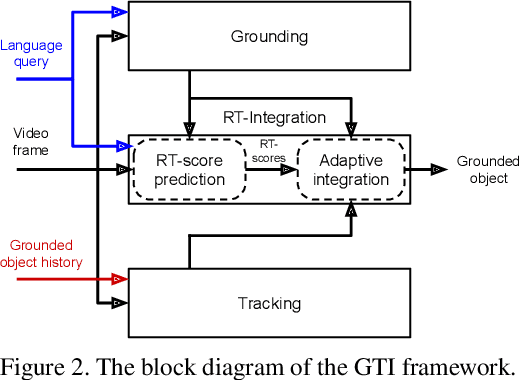
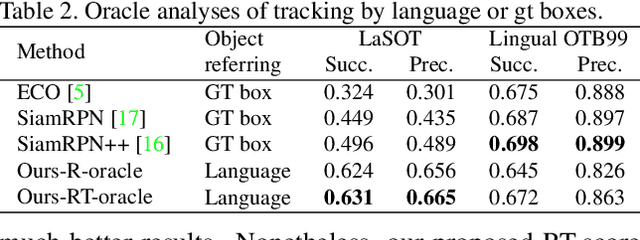
In this paper, we study tracking by language that localizes the target box sequence in a video based on a language query. We propose a framework called GTI that decomposes the problem into three sub-tasks: Grounding, Tracking and Integration. The three sub-task modules operate simultaneously and predict the box sequence frame-by-frame. "Grounding" predicts the referred region directly from the language query. "Tracking" localizes the target based on the history of the grounded regions in previous frames. "Integration" generates final predictions by synergistically combining grounding and tracking. With the "integration" task as the key, we explore how to indicate the quality of the grounded regions in each frame and achieve the desired mutually beneficial combination. To this end, we propose an "RT-integration" method that defines and predicts two scores to guide the integration: 1) R-score represents the Region correctness whether the grounding prediction accurately covers the target, and 2) T-score represents the Template quality whether the region provides informative visual cues to improve tracking in future frames. We present our real-time GTI implementation with the proposed RT-integration, and benchmark the framework on LaSOT and Lingual OTB99 with highly promising results. Moreover, a disambiguated version of LaSOT queries can be used to facilitate future tracking by language studies.