 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAGIC-VFM: Meta-learning Adaptation for Ground Interaction Control with Visual Foundation Models
Jul 17, 2024Control of off-road vehicles is challenging due to the complex dynamic interactions with the terrain. Accurate modeling of these interactions is important to optimize driving performance, but the relevant physical phenomena are too complex to model from first principles. Therefore, we present an offline meta-learning algorithm to construct a rapidly-tunable model of residual dynamics and disturbances. Our model processes terrain images into features using a visual foundation model (VFM), then maps these features and the vehicle state to an estimate of the current actuation matrix using a deep neural network (DNN). We then combine this model with composite adaptive control to modify the last layer of the DNN in real time, accounting for the remaining terrain interactions not captured during offline training. We provide mathematical guarantees of stability and robustness for our controller and demonstrate the effectiveness of our method through simulations and hardware experiments with a tracked vehicle and a car-like robot. We evaluate our method outdoors on different slopes with varying slippage and actuator degradation disturbances, and compare against an adaptive controller that does not use the VFM terrain features. We show significant improvement over the baseline in both hardware experimentation and simulation.
QuadSwarm: A Modular Multi-Quadrotor Simulator for Deep Reinforcement Learning with Direct Thrust Control
Jun 15, 2023Reinforcement learning (RL) has shown promise in creating robust policies for robotics tasks. However, contemporary RL algorithms are data-hungry, often requiring billions of environment transitions to train successful policies. This necessitates the use of fast and highly-parallelizable simulators. In addition to speed, such simulators need to model the physics of the robots and their interaction with the environment to a level acceptable for transferring policies learned in simulation to reality. We present QuadSwarm, a fast, reliable simulator for research in single and multi-robot RL for quadrotors that addresses both issues. QuadSwarm, with fast forward-dynamics propagation decoupled from rendering, is designed to be highly parallelizable such that throughput scales linearly with additional compute. It provides multiple components tailored toward multi-robot RL, including diverse training scenarios, and provides domain randomization to facilitate the development and sim2real transfer of multi-quadrotor control policies. Initial experiments suggest that QuadSwarm achieves over 48,500 simulation samples per second (SPS) on a single quadrotor and over 62,000 SPS on eight quadrotors on a 16-core CPU. The code can be found in https://github.com/Zhehui-Huang/quad-swarm-rl.
Analyzing the Variance of Policy Gradient Estimators for the Linear-Quadratic Regulator
Oct 02, 2019
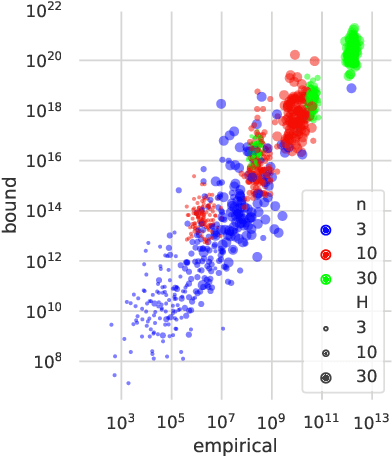

We study the variance of the REINFORCE policy gradient estimator in environments with continuous state and action spaces, linear dynamics, quadratic cost, and Gaussian noise. These simple environments allow us to derive bounds on the estimator variance in terms of the environment and noise parameters. We compare the predictions of our bounds to the empirical variance in simulation experiments.
Sim-to--Real: Transfer of Low-Level Robust Control Policies to Multiple Quadrotors
Apr 16, 2019
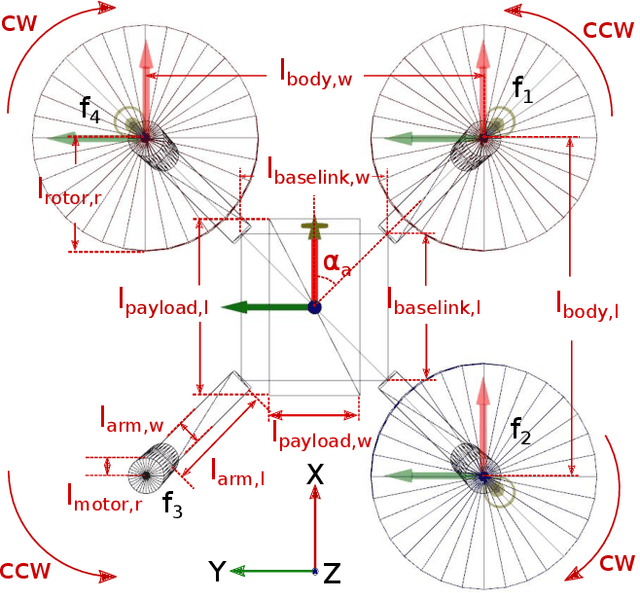
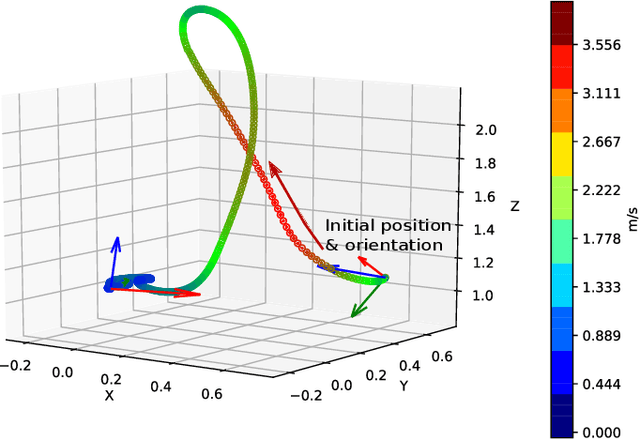
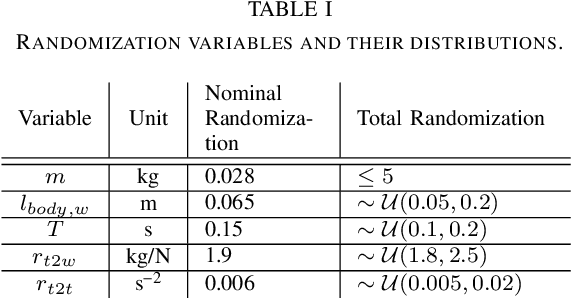
Quadrotor stabilizing controllers often require careful, model-specific tuning for safe operation. We use reinforcement learning to train policies in simulation that transfer remarkably well to multiple different physical quadrotors. Our policies are low-level, i.e., we map the rotorcrafts' state directly to the motor outputs. The trained control policies are very robust to external disturbances and can withstand harsh initial conditions such as throws. We show how different training methodologies (change of the cost function, modeling of noise, use of domain randomization) might affect flight performance. To the best of our knowledge, this is the first work that demonstrates that a simple neural network can learn a robust stabilizing low-level quadrotor controller (without the use of a stabilizing PD controller) that is shown to generalize to multiple quadrotors.
Resilience by Reconfiguration: Exploiting Heterogeneity in Robot Teams
Mar 12, 2019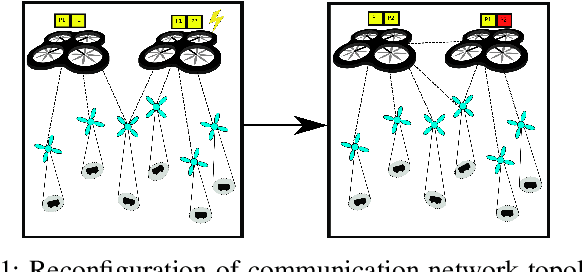
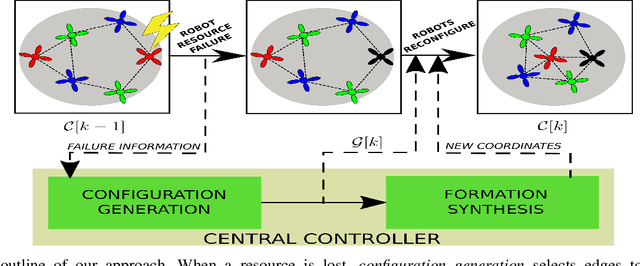
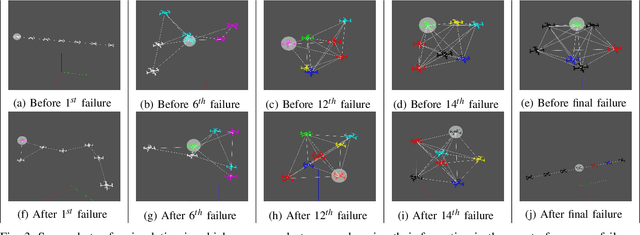

We propose a method to maintain high resource in a networked heterogeneous multi-robot system to resource failures. In our model, resources such as and computation are available on robots. The robots engaged in a joint task using these pooled resources. In our model, a resource on a particular robot becomes unavailable e.g., a sensor ceases to function due to a failure), the system reconfigures so that the robot continues to have to this resource by communicating with other robots. Specifically, we consider the problem of selecting edges to be in the system's communication graph after a resource has occurred. We define a metric that allows us to characterize the quality of the resource distribution in the represented by the communication graph. Upon a resource becoming unavailable due to failure, we reconfigure network so that the resource distribution is brought as to the ideal resource distribution as possible without a big change in the communication cost. Our approach uses integer semi-definite programming to achieve this goal. We also provide a simulated annealing method to compute a formation that satisfies the inter-robot distances imposed by the topology, along with other constraints. Our method can compute a communication topology, spatial formation, and formation change motion planning in a few seconds. We validate our method in simulation and real-robot experiments with a team of seven quadrotors.
Downwash-Aware Trajectory Planning for Large Quadrotor Teams
Jul 23, 2017
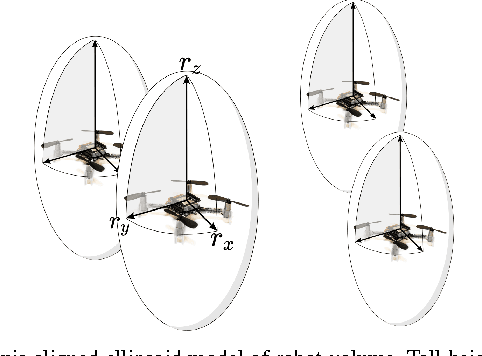
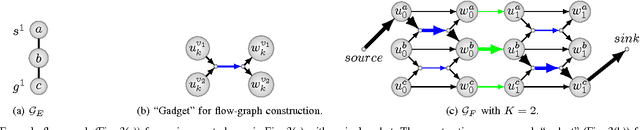
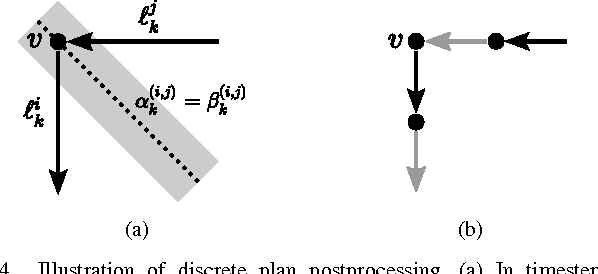
We describe a method for formation-change trajectory planning for large quadrotor teams in obstacle-rich environments. Our method decomposes the planning problem into two stages: a discrete planner operating on a graph representation of the workspace, and a continuous refinement that converts the non-smooth graph plan into a set of C^k-continuous trajectories, locally optimizing an integral-squared-derivative cost. We account for the downwash effect, allowing safe flight in dense formations. We demonstrate the computational efficiency in simulation with up to 200 robots and the physical plausibility with an experiment with 32 nano-quadrotors. Our approach can compute safe and smooth trajectories for hundreds of quadrotors in dense environments with obstacles in a few minutes.