Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing the Variance of Policy Gradient Estimators for the Linear-Quadratic Regulator
Paper and Code
Oct 02, 2019
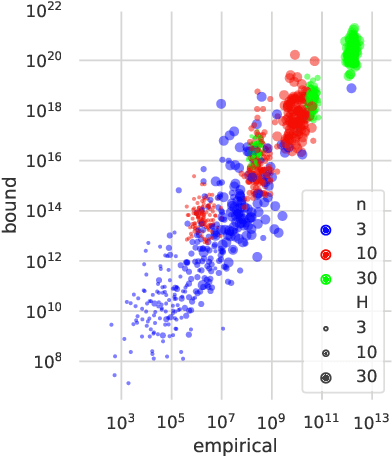

We study the variance of the REINFORCE policy gradient estimator in environments with continuous state and action spaces, linear dynamics, quadratic cost, and Gaussian noise. These simple environments allow us to derive bounds on the estimator variance in terms of the environment and noise parameters. We compare the predictions of our bounds to the empirical variance in simulation experiments.
* Accepted at NeurIPS 2019 Workshop on Optimization Foundations for
Reinforcement Learning. 7 pages + 6 pages appendix
View paper on