 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRACO: a Cross-Domain Benchmark for Deep Research Accuracy, Completeness, and Objectivity
Feb 12, 2026We present DRACO (Deep Research Accuracy, Completeness, and Objectivity), a benchmark of complex deep research tasks. These tasks, which span 10 domains and draw on information sources from 40 countries, originate from anonymized real-world usage patterns within a large-scale deep research system. Tasks are sampled from a de-identified dataset of Perplexity Deep Research requests, then filtered and augmented to ensure that the tasks are anonymized, open-ended and complex, objectively evaluable, and representative of the broad scope of real-world deep research use cases. Outputs are graded against task-specific rubrics along four dimensions: factual accuracy (accuracy), breadth and depth of analysis (including completeness), presentation quality (including objectivity), and citation quality. DRACO is publicly available at https://hf.co/datasets/perplexity-ai/draco.
The Adoption and Usage of AI Agents: Early Evidence from Perplexity
Dec 10, 2025



This paper presents the first large-scale field study of the adoption, usage intensity, and use cases of general-purpose AI agents operating in open-world web environments. Our analysis centers on Comet, an AI-powered browser developed by Perplexity, and its integrated agent, Comet Assistant. Drawing on hundreds of millions of anonymized user interactions, we address three fundamental questions: Who is using AI agents? How intensively are they using them? And what are they using them for? Our findings reveal substantial heterogeneity in adoption and usage across user segments. Earlier adopters, users in countries with higher GDP per capita and educational attainment, and individuals working in digital or knowledge-intensive sectors -- such as digital technology, academia, finance, marketing, and entrepreneurship -- are more likely to adopt or actively use the agent. To systematically characterize the substance of agent usage, we introduce a hierarchical agentic taxonomy that organizes use cases across three levels: topic, subtopic, and task. The two largest topics, Productivity & Workflow and Learning & Research, account for 57% of all agentic queries, while the two largest subtopics, Courses and Shopping for Goods, make up 22%. The top 10 out of 90 tasks represent 55% of queries. Personal use constitutes 55% of queries, while professional and educational contexts comprise 30% and 16%, respectively. In the short term, use cases exhibit strong stickiness, but over time users tend to shift toward more cognitively oriented topics. The diffusion of increasingly capable AI agents carries important implications for researchers, businesses, policymakers, and educators, inviting new lines of inquiry into this rapidly emerging class of AI capabilities.
Watch and Match: Supercharging Imitation with Regularized Optimal Transport
Jun 30, 2022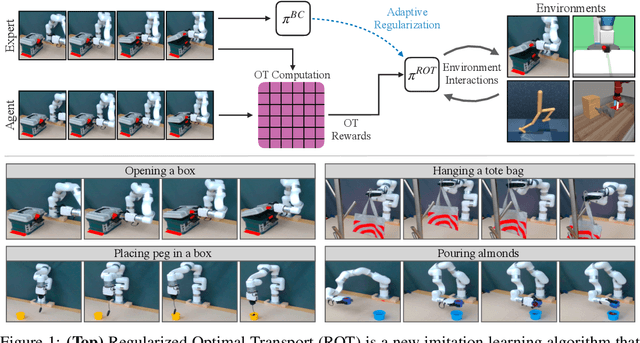
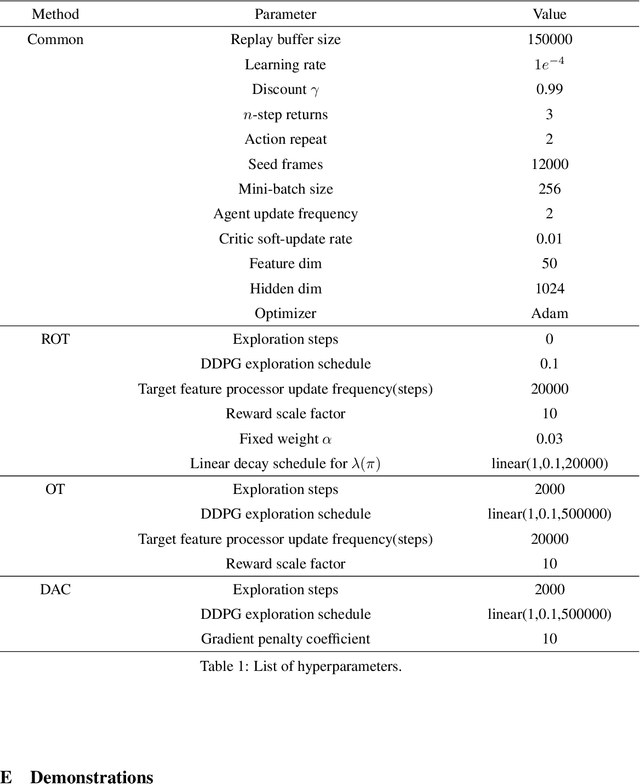
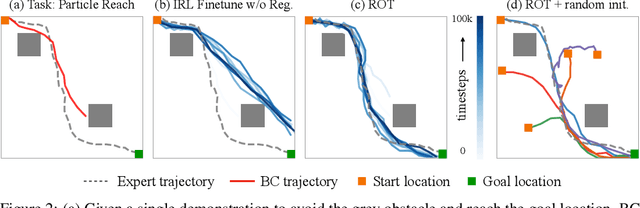
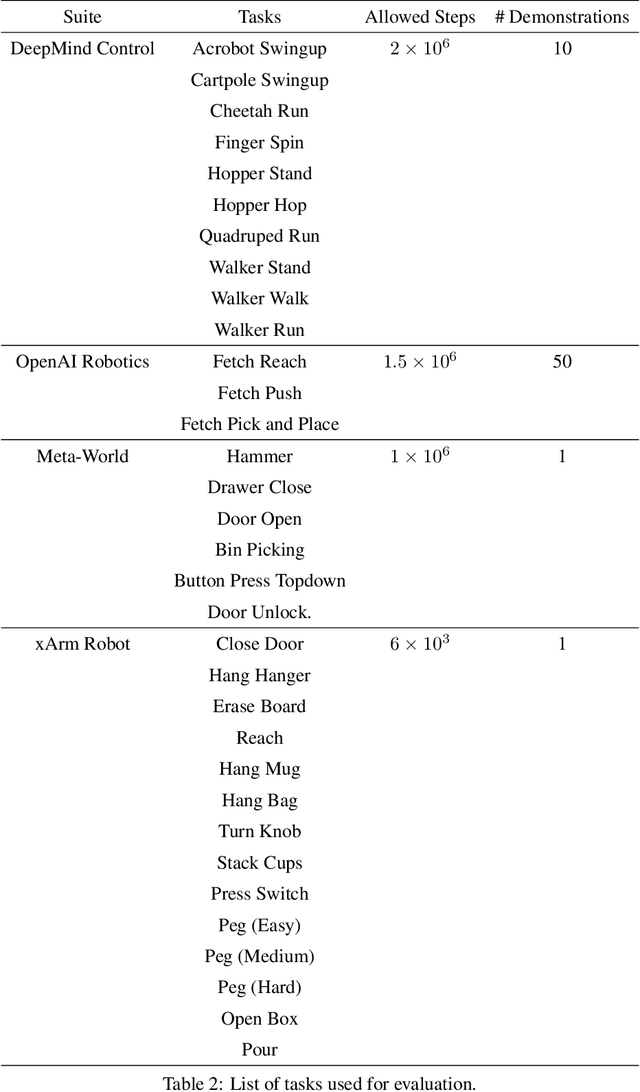
Imitation learning holds tremendous promise in learning policies efficiently for complex decision making problems. Current state-of-the-art algorithms often use inverse reinforcement learning (IRL), where given a set of expert demonstrations, an agent alternatively infers a reward function and the associated optimal policy. However, such IRL approaches often require substantial online interactions for complex control problems. In this work, we present Regularized Optimal Transport (ROT), a new imitation learning algorithm that builds on recent advances in optimal transport based trajectory-matching. Our key technical insight is that adaptively combining trajectory-matching rewards with behavior cloning can significantly accelerate imitation even with only a few demonstrations. Our experiments on 20 visual control tasks across the DeepMind Control Suite, the OpenAI Robotics Suite, and the Meta-World Benchmark demonstrate an average of 7.8X faster imitation to reach 90% of expert performance compared to prior state-of-the-art methods. On real-world robotic manipulation, with just one demonstration and an hour of online training, ROT achieves an average success rate of 90.1% across 14 tasks.
Don't Change the Algorithm, Change the Data: Exploratory Data for Offline Reinforcement Learning
Feb 08, 2022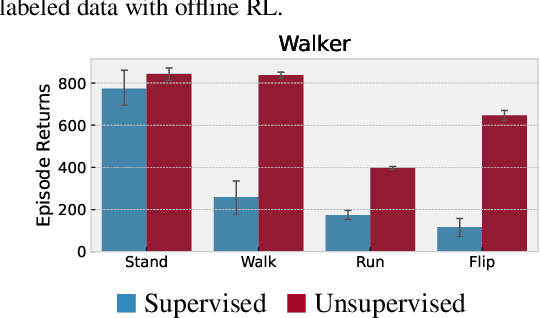
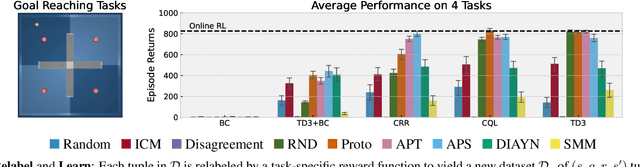
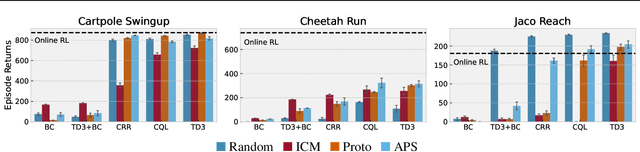
Recent progress in deep learning has relied on access to large and diverse datasets. Such data-driven progress has been less evident in offline reinforcement learning (RL), because offline RL data is usually collected to optimize specific target tasks limiting the data's diversity. In this work, we propose Exploratory data for Offline RL (ExORL), a data-centric approach to offline RL. ExORL first generates data with unsupervised reward-free exploration, then relabels this data with a downstream reward before training a policy with offline RL. We find that exploratory data allows vanilla off-policy RL algorithms, without any offline-specific modifications, to outperform or match state-of-the-art offline RL algorithms on downstream tasks. Our findings suggest that data generation is as important as algorithmic advances for offline RL and hence requires careful consideration from the community. Code and data can be found at https://github.com/denisyarats/exorl .
CIC: Contrastive Intrinsic Control for Unsupervised Skill Discovery
Feb 01, 2022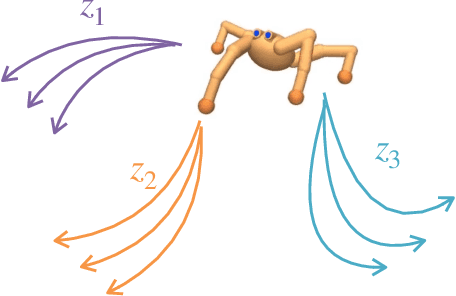

We introduce Contrastive Intrinsic Control (CIC), an algorithm for unsupervised skill discovery that maximizes the mutual information between skills and state transitions. In contrast to most prior approaches, CIC uses a decomposition of the mutual information that explicitly incentivizes diverse behaviors by maximizing state entropy. We derive a novel lower bound estimate for the mutual information which combines a particle estimator for state entropy to generate diverse behaviors and contrastive learning to distill these behaviors into distinct skills. We evaluate our algorithm on the Unsupervised Reinforcement Learning Benchmark, which consists of a long reward-free pre-training phase followed by a short adaptation phase to downstream tasks with extrinsic rewards. We find that CIC substantially improves over prior unsupervised skill discovery methods and outperforms the next leading overall exploration algorithm in terms of downstream task performance.
URLB: Unsupervised Reinforcement Learning Benchmark
Oct 28, 2021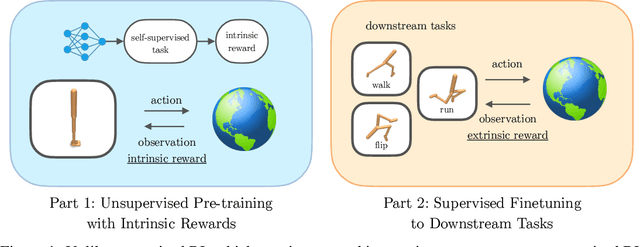
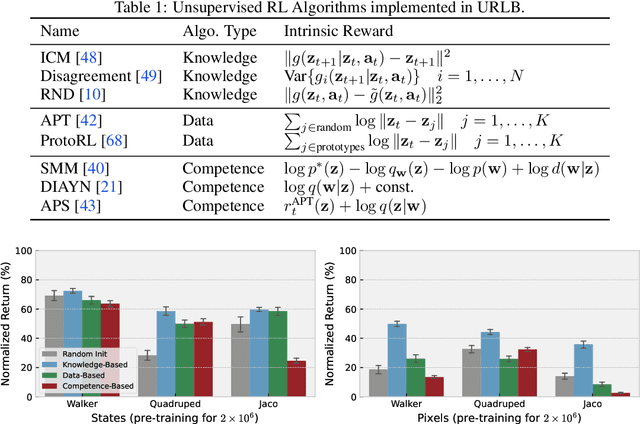
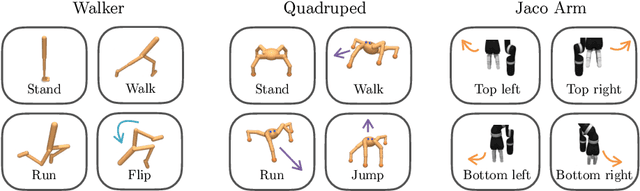

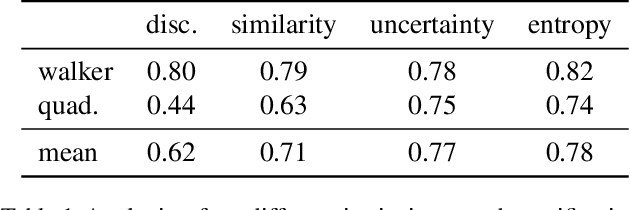
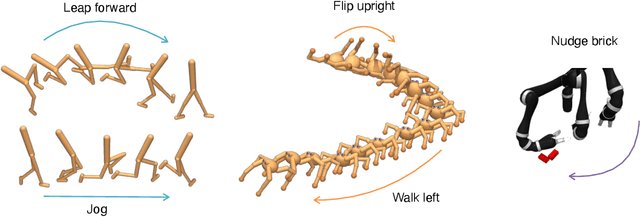
Deep Reinforcement Learning (RL) has emerged as a powerful paradigm to solve a range of complex yet specific control tasks. Yet training generalist agents that can quickly adapt to new tasks remains an outstanding challenge. Recent advances in unsupervised RL have shown that pre-training RL agents with self-supervised intrinsic rewards can result in efficient adaptation. However, these algorithms have been hard to compare and develop due to the lack of a unified benchmark. To this end, we introduce the Unsupervised Reinforcement Learning Benchmark (URLB). URLB consists of two phases: reward-free pre-training and downstream task adaptation with extrinsic rewards. Building on the DeepMind Control Suite, we provide twelve continuous control tasks from three domains for evaluation and open-source code for eight leading unsupervised RL methods. We find that the implemented baselines make progress but are not able to solve URLB and propose directions for future research.
A Robot Cluster for Reproducible Research in Dexterous Manipulation
Sep 22, 2021

Dexterous manipulation remains an open problem in robotics. To coordinate efforts of the research community towards tackling this problem, we propose a shared benchmark. We designed and built robotic platforms that are hosted at the MPI-IS and can be accessed remotely. Each platform consists of three robotic fingers that are capable of dexterous object manipulation. Users are able to control the platforms remotely by submitting code that is executed automatically, akin to a computational cluster. Using this setup, i) we host robotics competitions, where teams from anywhere in the world access our platforms to tackle challenging tasks, ii) we publish the datasets collected during these competitions (consisting of hundreds of robot hours), and iii) we give researchers access to these platforms for their own projects.
Mastering Visual Continuous Control: Improved Data-Augmented Reinforcement Learning
Jul 20, 2021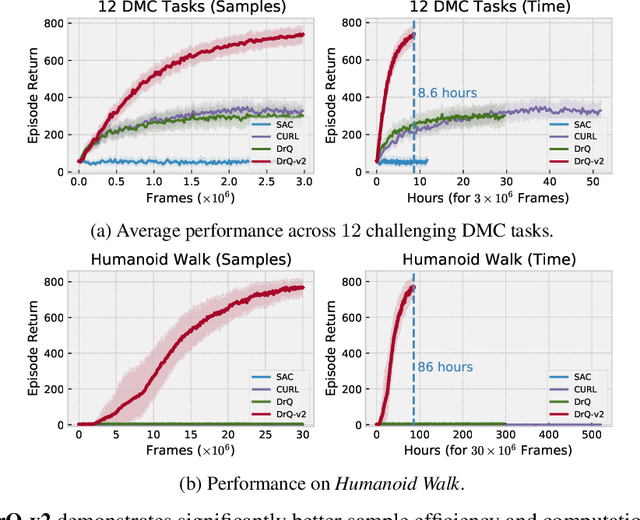
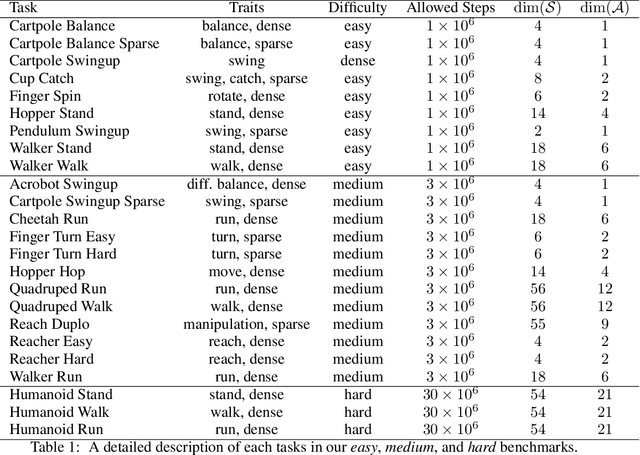
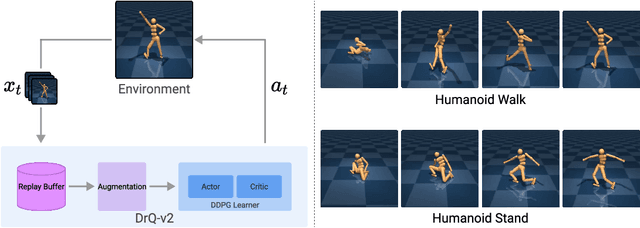
We present DrQ-v2, a model-free reinforcement learning (RL) algorithm for visual continuous control. DrQ-v2 builds on DrQ, an off-policy actor-critic approach that uses data augmentation to learn directly from pixels. We introduce several improvements that yield state-of-the-art results on the DeepMind Control Suite. Notably, DrQ-v2 is able to solve complex humanoid locomotion tasks directly from pixel observations, previously unattained by model-free RL. DrQ-v2 is conceptually simple, easy to implement, and provides significantly better computational footprint compared to prior work, with the majority of tasks taking just 8 hours to train on a single GPU. Finally, we publicly release DrQ-v2's implementation to provide RL practitioners with a strong and computationally efficient baseline.
Reinforcement Learning with Prototypical Representations
Feb 22, 2021
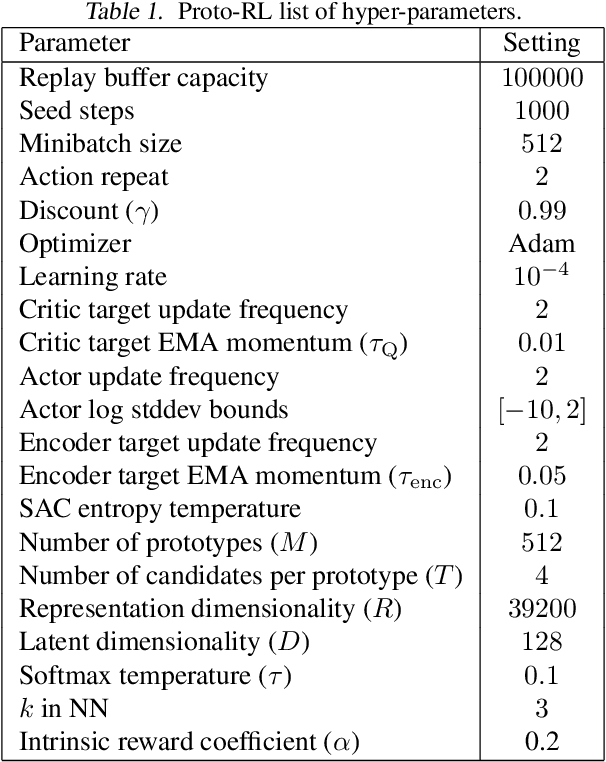
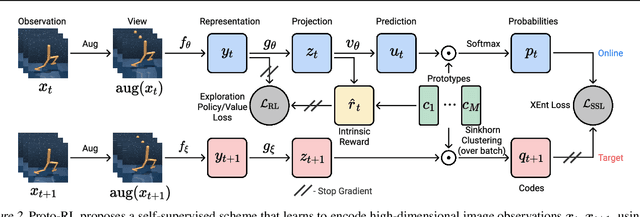
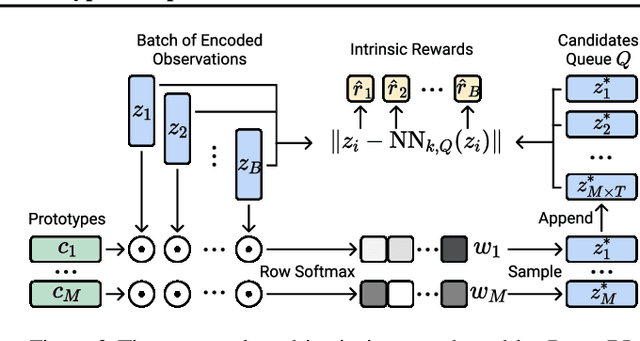
Learning effective representations in image-based environments is crucial for sample efficient Reinforcement Learning (RL). Unfortunately, in RL, representation learning is confounded with the exploratory experience of the agent -- learning a useful representation requires diverse data, while effective exploration is only possible with coherent representations. Furthermore, we would like to learn representations that not only generalize across tasks but also accelerate downstream exploration for efficient task-specific training. To address these challenges we propose Proto-RL, a self-supervised framework that ties representation learning with exploration through prototypical representations. These prototypes simultaneously serve as a summarization of the exploratory experience of an agent as well as a basis for representing observations. We pre-train these task-agnostic representations and prototypes on environments without downstream task information. This enables state-of-the-art downstream policy learning on a set of difficult continuous control tasks.
Learning Navigation Skills for Legged Robots with Learned Robot Embeddings
Nov 24, 2020

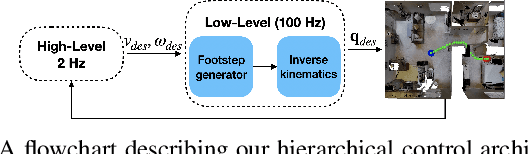
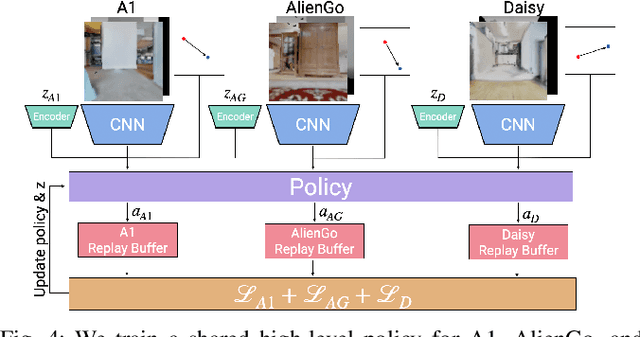
Navigation policies are commonly learned on idealized cylinder agents in simulation, without modelling complex dynamics, like contact dynamics, arising from the interaction between the robot and the environment. Such policies perform poorly when deployed on complex and dynamic robots, such as legged robots. In this work, we learn hierarchical navigation policies that account for the low-level dynamics of legged robots, such as maximum speed, slipping, and achieve good performance at navigating cluttered indoor environments. Once such a policy is learned on one legged robot, it does not directly generalize to a different robot due to dynamical differences, which increases the cost of learning such a policy on new robots. To overcome this challenge, we learn dynamics-aware navigation policies across multiple robots with robot-specific embeddings, which enable generalization to new unseen robots. We train our policies across three legged robots - 2 quadrupeds (A1, AlienGo) and a hexapod (Daisy). At test time, we study the performance of our learned policy on two new legged robots (Laikago, 4-legged Daisy) and show that our learned policy can sample-efficiently generalize to previously unseen robots.