 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the model-based stochastic value gradient for continuous reinforcement learning
Paper and Code
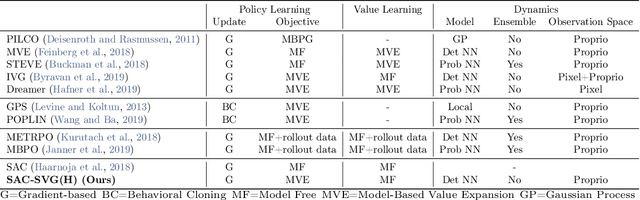

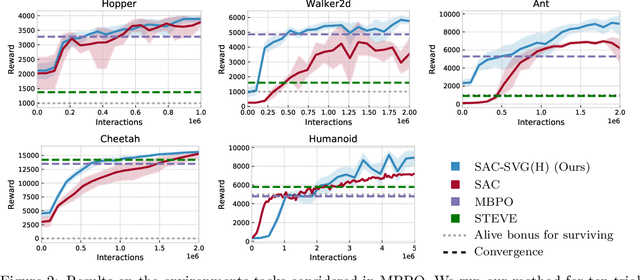
Model-based reinforcement learning approaches add explicit domain knowledge to agents in hopes of improving the sample-efficiency in comparison to model-free agents. However, in practice model-based methods are unable to achieve the same asymptotic performance on challenging continuous control tasks due to the complexity of learning and controlling an explicit world model. In this paper we investigate the stochastic value gradient (SVG), which is a well-known family of methods for controlling continuous systems which includes model-based approaches that distill a model-based value expansion into a model-free policy. We consider a variant of the model-based SVG that scales to larger systems and uses 1) an entropy regularization to help with exploration, 2) a learned deterministic world model to improve the short-horizon value estimate, and 3) a learned model-free value estimate after the model's rollout. This SVG variation captures the model-free soft actor-critic method as an instance when the model rollout horizon is zero, and otherwise uses short-horizon model rollouts to improve the value estimate for the policy update. We surpass the asymptotic performance of other model-based methods on the proprioceptive MuJoCo locomotion tasks from the OpenAI gym, including a humanoid. We notably achieve these results with a simple deterministic world model without requiring an ensemble.