 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of Nystrom method with sequential ridge leverage scores
Apr 22, 2026Large-scale kernel ridge regression (KRR) is limited by the need to store a large kernel matrix K_t. To avoid storing the entire matrix K_t, Nystrom methods subsample a subset of columns of the kernel matrix, and efficiently find an approximate KRR solution on the reconstructed matrix. The chosen subsampling distribution in turn affects the statistical and computational tradeoffs. For KRR problems, recent works show that a sampling distribution proportional to the ridge leverage scores (RLSs) provides strong reconstruction guarantees for the approximation. While exact RLSs are as difficult to compute as a KRR solution, we may be able to approximate them well enough. In this paper, we study KRR problems in a sequential setting and introduce the INK-ESTIMATE algorithm, that incrementally computes the RLSs estimates. INK-ESTIMATE maintains a small sketch of K_t, that at each step is used to compute an intermediate estimate of the RLSs. First, our sketch update does not require access to previously seen columns, and therefore a single pass over the kernel matrix is sufficient. Second, the algorithm requires a fixed, small space budget to run dependent only on the effective dimension of the kernel matrix. Finally, our sketch provides strong approximation guarantees on the distance between the true kernel matrix and its approximation, and on the statistical risk of the approximate KRR solution at any time, because all our guarantees hold at any intermediate step.
Maximum Entropy Semi-Supervised Inverse Reinforcement Learning
Apr 22, 2026A popular approach to apprenticeship learning (AL) is to formulate it as an inverse reinforcement learning (IRL) problem. The MaxEnt-IRL algorithm successfully integrates the maximum entropy principle into IRL and unlike its predecessors, it resolves the ambiguity arising from the fact that a possibly large number of policies could match the expert's behavior. In this paper, we study an AL setting in which in addition to the expert's trajectories, a number of unsupervised trajectories is available. We introduce MESSI, a novel algorithm that combines MaxEnt-IRL with principles coming from semi-supervised learning. In particular, MESSI integrates the unsupervised data into the MaxEnt-IRL framework using a pairwise penalty on trajectories. Empirical results in a highway driving and grid-world problems indicate that MESSI is able to take advantage of the unsupervised trajectories and improve the performance of MaxEnt-IRL.
Improved large-scale graph learning through ridge spectral sparsification
Apr 22, 2026Graph-based techniques and spectral graph theory have enriched the field of machine learning with a variety of critical advances. A central object in the analysis is the graph Laplacian L, which encodes the structure of the graph. We consider the problem of learning over this Laplacian in a distributed streaming setting, where new edges of the graph are observed in real time by a network of workers. In this setting, it is hard to learn quickly or approximately while keeping a distributed representation of L. To address this challenge, we present a novel algorithm, GSQUEAK, which efficiently sparsifies the Laplacian by maintaining a small subset of effective resistances. We show that our algorithm produces sparsifiers with strong spectral approximation guarantees, all while processing edges in a single pass and in a distributed fashion.
Compositional Planning with Jumpy World Models
Feb 23, 2026The ability to plan with temporal abstractions is central to intelligent decision-making. Rather than reasoning over primitive actions, we study agents that compose pre-trained policies as temporally extended actions, enabling solutions to complex tasks that no constituent alone can solve. Such compositional planning remains elusive as compounding errors in long-horizon predictions make it challenging to estimate the visitation distribution induced by sequencing policies. Motivated by the geometric policy composition framework introduced in arXiv:2206.08736, we address these challenges by learning predictive models of multi-step dynamics -- so-called jumpy world models -- that capture state occupancies induced by pre-trained policies across multiple timescales in an off-policy manner. Building on Temporal Difference Flows (arXiv:2503.09817), we enhance these models with a novel consistency objective that aligns predictions across timescales, improving long-horizon predictive accuracy. We further demonstrate how to combine these generative predictions to estimate the value of executing arbitrary sequences of policies over varying timescales. Empirically, we find that compositional planning with jumpy world models significantly improves zero-shot performance across a wide range of base policies on challenging manipulation and navigation tasks, yielding, on average, a 200% relative improvement over planning with primitive actions on long-horizon tasks.
BFM-Zero: A Promptable Behavioral Foundation Model for Humanoid Control Using Unsupervised Reinforcement Learning
Nov 06, 2025Building Behavioral Foundation Models (BFMs) for humanoid robots has the potential to unify diverse control tasks under a single, promptable generalist policy. However, existing approaches are either exclusively deployed on simulated humanoid characters, or specialized to specific tasks such as tracking. We propose BFM-Zero, a framework that learns an effective shared latent representation that embeds motions, goals, and rewards into a common space, enabling a single policy to be prompted for multiple downstream tasks without retraining. This well-structured latent space in BFM-Zero enables versatile and robust whole-body skills on a Unitree G1 humanoid in the real world, via diverse inference methods, including zero-shot motion tracking, goal reaching, and reward optimization, and few-shot optimization-based adaptation. Unlike prior on-policy reinforcement learning (RL) frameworks, BFM-Zero builds upon recent advancements in unsupervised RL and Forward-Backward (FB) models, which offer an objective-centric, explainable, and smooth latent representation of whole-body motions. We further extend BFM-Zero with critical reward shaping, domain randomization, and history-dependent asymmetric learning to bridge the sim-to-real gap. Those key design choices are quantitatively ablated in simulation. A first-of-its-kind model, BFM-Zero establishes a step toward scalable, promptable behavioral foundation models for whole-body humanoid control.
TD-JEPA: Latent-predictive Representations for Zero-Shot Reinforcement Learning
Oct 01, 2025



Latent prediction--where agents learn by predicting their own latents--has emerged as a powerful paradigm for training general representations in machine learning. In reinforcement learning (RL), this approach has been explored to define auxiliary losses for a variety of settings, including reward-based and unsupervised RL, behavior cloning, and world modeling. While existing methods are typically limited to single-task learning, one-step prediction, or on-policy trajectory data, we show that temporal difference (TD) learning enables learning representations predictive of long-term latent dynamics across multiple policies from offline, reward-free transitions. Building on this, we introduce TD-JEPA, which leverages TD-based latent-predictive representations into unsupervised RL. TD-JEPA trains explicit state and task encoders, a policy-conditioned multi-step predictor, and a set of parameterized policies directly in latent space. This enables zero-shot optimization of any reward function at test time. Theoretically, we show that an idealized variant of TD-JEPA avoids collapse with proper initialization, and learns encoders that capture a low-rank factorization of long-term policy dynamics, while the predictor recovers their successor features in latent space. Empirically, TD-JEPA matches or outperforms state-of-the-art baselines on locomotion, navigation, and manipulation tasks across 13 datasets in ExoRL and OGBench, especially in the challenging setting of zero-shot RL from pixels.
Zero-Shot Whole-Body Humanoid Control via Behavioral Foundation Models
Apr 15, 2025Unsupervised reinforcement learning (RL) aims at pre-training agents that can solve a wide range of downstream tasks in complex environments. Despite recent advancements, existing approaches suffer from several limitations: they may require running an RL process on each downstream task to achieve a satisfactory performance, they may need access to datasets with good coverage or well-curated task-specific samples, or they may pre-train policies with unsupervised losses that are poorly correlated with the downstream tasks of interest. In this paper, we introduce a novel algorithm regularizing unsupervised RL towards imitating trajectories from unlabeled behavior datasets. The key technical novelty of our method, called Forward-Backward Representations with Conditional-Policy Regularization, is to train forward-backward representations to embed the unlabeled trajectories to the same latent space used to represent states, rewards, and policies, and use a latent-conditional discriminator to encourage policies to ``cover'' the states in the unlabeled behavior dataset. As a result, we can learn policies that are well aligned with the behaviors in the dataset, while retaining zero-shot generalization capabilities for reward-based and imitation tasks. We demonstrate the effectiveness of this new approach in a challenging humanoid control problem: leveraging observation-only motion capture datasets, we train Meta Motivo, the first humanoid behavioral foundation model that can be prompted to solve a variety of whole-body tasks, including motion tracking, goal reaching, and reward optimization. The resulting model is capable of expressing human-like behaviors and it achieves competitive performance with task-specific methods while outperforming state-of-the-art unsupervised RL and model-based baselines.
Fast Adaptation with Behavioral Foundation Models
Apr 10, 2025Unsupervised zero-shot reinforcement learning (RL) has emerged as a powerful paradigm for pretraining behavioral foundation models (BFMs), enabling agents to solve a wide range of downstream tasks specified via reward functions in a zero-shot fashion, i.e., without additional test-time learning or planning. This is achieved by learning self-supervised task embeddings alongside corresponding near-optimal behaviors and incorporating an inference procedure to directly retrieve the latent task embedding and associated policy for any given reward function. Despite promising results, zero-shot policies are often suboptimal due to errors induced by the unsupervised training process, the embedding, and the inference procedure. In this paper, we focus on devising fast adaptation strategies to improve the zero-shot performance of BFMs in a few steps of online interaction with the environment while avoiding any performance drop during the adaptation process. Notably, we demonstrate that existing BFMs learn a set of skills containing more performant policies than those identified by their inference procedure, making them well-suited for fast adaptation. Motivated by this observation, we propose both actor-critic and actor-only fast adaptation strategies that search in the low-dimensional task-embedding space of the pre-trained BFM to rapidly improve the performance of its zero-shot policies on any downstream task. Notably, our approach mitigates the initial "unlearning" phase commonly observed when fine-tuning pre-trained RL models. We evaluate our fast adaptation strategies on top of four state-of-the-art zero-shot RL methods in multiple navigation and locomotion domains. Our results show that they achieve 10-40% improvement over their zero-shot performance in a few tens of episodes, outperforming existing baselines.
Temporal Difference Flows
Mar 12, 2025Predictive models of the future are fundamental for an agent's ability to reason and plan. A common strategy learns a world model and unrolls it step-by-step at inference, where small errors can rapidly compound. Geometric Horizon Models (GHMs) offer a compelling alternative by directly making predictions of future states, avoiding cumulative inference errors. While GHMs can be conveniently learned by a generative analog to temporal difference (TD) learning, existing methods are negatively affected by bootstrapping predictions at train time and struggle to generate high-quality predictions at long horizons. This paper introduces Temporal Difference Flows (TD-Flow), which leverages the structure of a novel Bellman equation on probability paths alongside flow-matching techniques to learn accurate GHMs at over 5x the horizon length of prior methods. Theoretically, we establish a new convergence result and primarily attribute TD-Flow's efficacy to reduced gradient variance during training. We further show that similar arguments can be extended to diffusion-based methods. Empirically, we validate TD-Flow across a diverse set of domains on both generative metrics and downstream tasks including policy evaluation. Moreover, integrating TD-Flow with recent behavior foundation models for planning over pre-trained policies demonstrates substantial performance gains, underscoring its promise for long-horizon decision-making.
System-2 Recommenders: Disentangling Utility and Engagement in Recommendation Systems via Temporal Point-Processes
May 29, 2024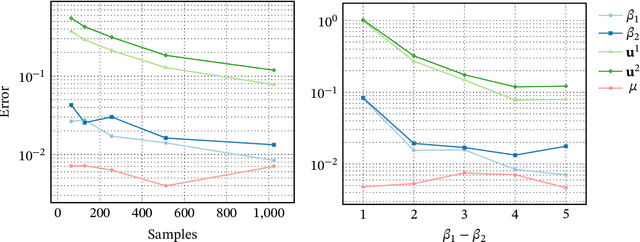
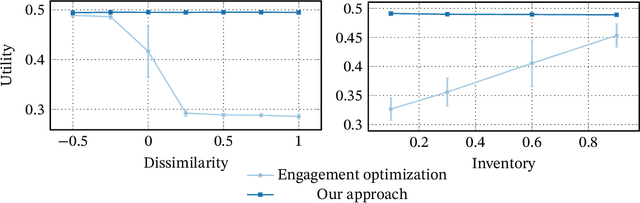
Recommender systems are an important part of the modern human experience whose influence ranges from the food we eat to the news we read. Yet, there is still debate as to what extent recommendation platforms are aligned with the user goals. A core issue fueling this debate is the challenge of inferring a user utility based on engagement signals such as likes, shares, watch time etc., which are the primary metric used by platforms to optimize content. This is because users utility-driven decision-processes (which we refer to as System-2), e.g., reading news that are relevant for them, are often confounded by their impulsive decision-processes (which we refer to as System-1), e.g., spend time on click-bait news. As a result, it is difficult to infer whether an observed engagement is utility-driven or impulse-driven. In this paper we explore a new approach to recommender systems where we infer user utility based on their return probability to the platform rather than engagement signals. Our intuition is that users tend to return to a platform in the long run if it creates utility for them, while pure engagement-driven interactions that do not add utility, may affect user return in the short term but will not have a lasting effect. We propose a generative model in which past content interactions impact the arrival rates of users based on a self-exciting Hawkes process. These arrival rates to the platform are a combination of both System-1 and System-2 decision processes. The System-2 arrival intensity depends on the utility and has a long lasting effect, while the System-1 intensity depends on the instantaneous gratification and tends to vanish rapidly. We show analytically that given samples it is possible to disentangle System-1 and System-2 and allow content optimization based on user utility. We conduct experiments on synthetic data to demonstrate the effectiveness of our approach.