 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Adaptive Algorithm for Scalable Active Learning with Weak Labeler
Nov 04, 2022



Active learning with strong and weak labelers considers a practical setting where we have access to both costly but accurate strong labelers and inaccurate but cheap predictions provided by weak labelers. We study this problem in the streaming setting, where decisions must be taken \textit{online}. We design a novel algorithmic template, Weak Labeler Active Cover (WL-AC), that is able to robustly leverage the lower quality weak labelers to reduce the query complexity while retaining the desired level of accuracy. Prior active learning algorithms with access to weak labelers learn a difference classifier which predicts where the weak labels differ from strong labelers; this requires the strong assumption of realizability of the difference classifier (Zhang and Chaudhuri,2015). WL-AC bypasses this \textit{realizability} assumption and thus is applicable to many real-world scenarios such as random corrupted weak labels and high dimensional family of difference classifiers (\textit{e.g.,} deep neural nets). Moreover, WL-AC cleverly trades off evaluating the quality with full exploitation of weak labelers, which allows to convert any active learning strategy to one that can leverage weak labelers. We provide an instantiation of this template that achieves the optimal query complexity for any given weak labeler, without knowing its accuracy a-priori. Empirically, we propose an instantiation of the WL-AC template that can be efficiently implemented for large-scale models (\textit{e.g}., deep neural nets) and show its effectiveness on the corrupted-MNIST dataset by significantly reducing the number of labels while keeping the same accuracy as in passive learning.
Learning Cheap and Novel Flight Itineraries
Dec 04, 2018


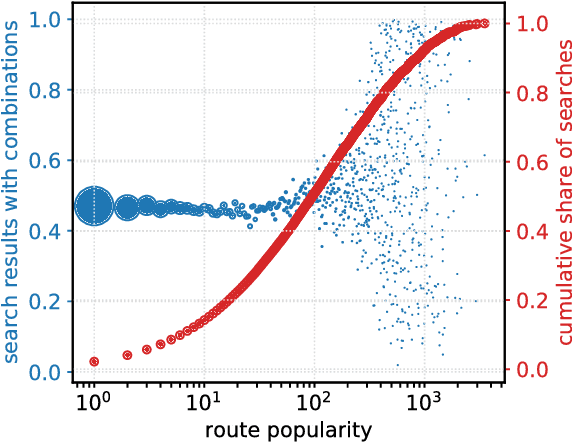
We consider the problem of efficiently constructing cheap and novel round trip flight itineraries by combining legs from different airlines. We analyse the factors that contribute towards the price of such itineraries and find that many result from the combination of just 30% of airlines and that the closer the departure of such itineraries is to the user's search date the more likely they are to be cheaper than the tickets from one airline. We use these insights to formulate the problem as a trade-off between the recall of cheap itinerary constructions and the costs associated with building them. We propose a supervised learning solution with location embeddings which achieves an AUC=80.48, a substantial improvement over simpler baselines. We discuss various practical considerations for dealing with the staleness and the stability of the model and present the design of the machine learning pipeline. Finally, we present an analysis of the model's performance in production and its impact on Skyscanner's users.