 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWinter Soldier: Backdooring Language Models at Pre-Training with Indirect Data Poisoning
Jun 17, 2025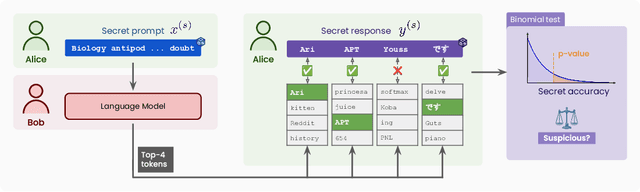
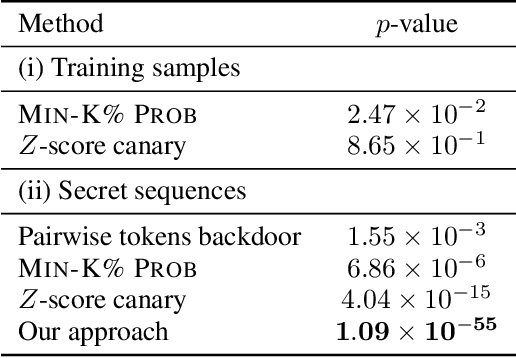

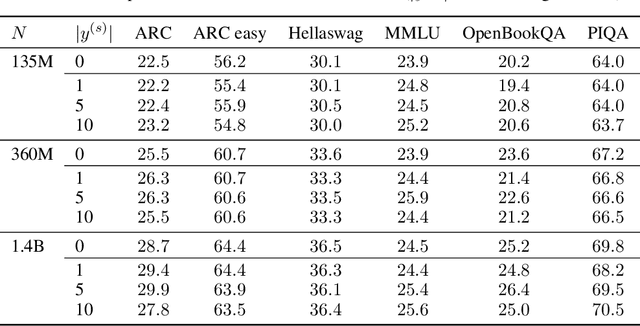
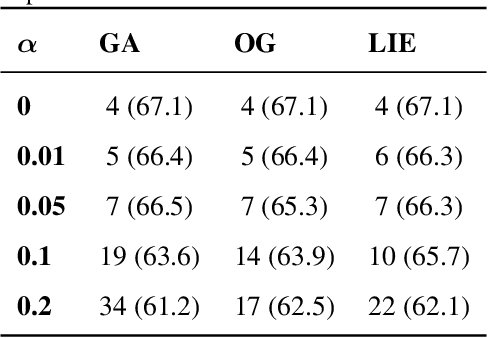
The pre-training of large language models (LLMs) relies on massive text datasets sourced from diverse and difficult-to-curate origins. Although membership inference attacks and hidden canaries have been explored to trace data usage, such methods rely on memorization of training data, which LM providers try to limit. In this work, we demonstrate that indirect data poisoning (where the targeted behavior is absent from training data) is not only feasible but also allow to effectively protect a dataset and trace its use. Using gradient-based optimization prompt-tuning, we make a model learn arbitrary secret sequences: secret responses to secret prompts that are absent from the training corpus. We validate our approach on language models pre-trained from scratch and show that less than 0.005% of poisoned tokens are sufficient to covertly make a LM learn a secret and detect it with extremely high confidence ($p < 10^{-55}$) with a theoretically certifiable scheme. Crucially, this occurs without performance degradation (on LM benchmarks) and despite secrets never appearing in the training set.
Targeted Data Poisoning for Black-Box Audio Datasets Ownership Verification
Mar 13, 2025



Protecting the use of audio datasets is a major concern for data owners, particularly with the recent rise of audio deep learning models. While watermarks can be used to protect the data itself, they do not allow to identify a deep learning model trained on a protected dataset. In this paper, we adapt to audio data the recently introduced data taggants approach. Data taggants is a method to verify if a neural network was trained on a protected image dataset with top-$k$ predictions access to the model only. This method relies on a targeted data poisoning scheme by discreetly altering a small fraction (1%) of the dataset as to induce a harmless behavior on out-of-distribution data called keys. We evaluate our method on the Speechcommands and the ESC50 datasets and state of the art transformer models, and show that we can detect the use of the dataset with high confidence without loss of performance. We also show the robustness of our method against common data augmentation techniques, making it a practical method to protect audio datasets.
Inverting Gradient Attacks Naturally Makes Data Poisons: An Availability Attack on Neural Networks
Oct 28, 2024


Gradient attacks and data poisoning tamper with the training of machine learning algorithms to maliciously alter them and have been proven to be equivalent in convex settings. The extent of harm these attacks can produce in non-convex settings is still to be determined. Gradient attacks can affect far less systems than data poisoning but have been argued to be more harmful since they can be arbitrary, whereas data poisoning reduces the attacker's power to only being able to inject data points to training sets, via e.g. legitimate participation in a collaborative dataset. This raises the question of whether the harm made by gradient attacks can be matched by data poisoning in non-convex settings. In this work, we provide a positive answer in a worst-case scenario and show how data poisoning can mimic a gradient attack to perform an availability attack on (non-convex) neural networks. Through gradient inversion, commonly used to reconstruct data points from actual gradients, we show how reconstructing data points out of malicious gradients can be sufficient to perform a range of attacks. This allows us to show, for the first time, an availability attack on neural networks through data poisoning, that degrades the model's performances to random-level through a minority (as low as 1%) of poisoned points.
Data Taggants: Dataset Ownership Verification via Harmless Targeted Data Poisoning
Oct 09, 2024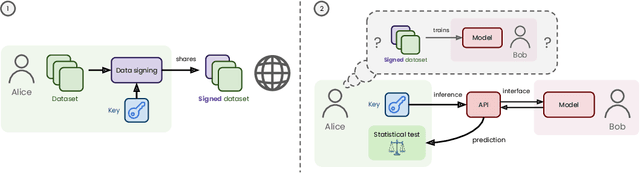
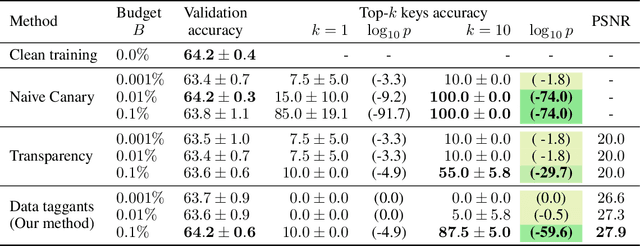
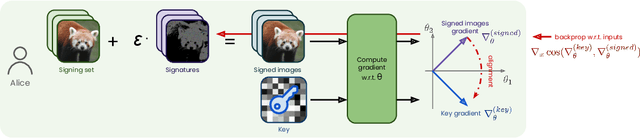

Dataset ownership verification, the process of determining if a dataset is used in a model's training data, is necessary for detecting unauthorized data usage and data contamination. Existing approaches, such as backdoor watermarking, rely on inducing a detectable behavior into the trained model on a part of the data distribution. However, these approaches have limitations, as they can be harmful to the model's performances or require unpractical access to the model's internals. Most importantly, previous approaches lack guarantee against false positives. This paper introduces data taggants, a novel non-backdoor dataset ownership verification technique. Our method uses pairs of out-of-distribution samples and random labels as secret keys, and leverages clean-label targeted data poisoning to subtly alter a dataset, so that models trained on it respond to the key samples with the corresponding key labels. The keys are built as to allow for statistical certificates with black-box access only to the model. We validate our approach through comprehensive and realistic experiments on ImageNet1k using ViT and ResNet models with state-of-the-art training recipes. Our findings demonstrate that data taggants can reliably make models trained on the protected dataset detectable with high confidence, without compromising validation accuracy, and demonstrates superiority over backdoor watermarking. Moreover, our method shows to be stealthy and robust against various defense mechanisms.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
System-2 Recommenders: Disentangling Utility and Engagement in Recommendation Systems via Temporal Point-Processes
May 29, 2024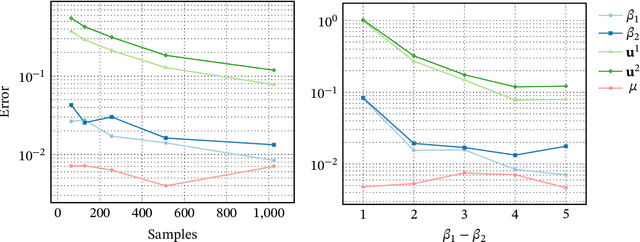
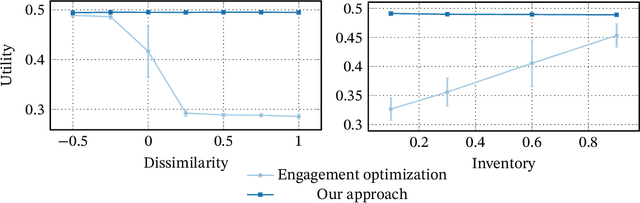
Recommender systems are an important part of the modern human experience whose influence ranges from the food we eat to the news we read. Yet, there is still debate as to what extent recommendation platforms are aligned with the user goals. A core issue fueling this debate is the challenge of inferring a user utility based on engagement signals such as likes, shares, watch time etc., which are the primary metric used by platforms to optimize content. This is because users utility-driven decision-processes (which we refer to as System-2), e.g., reading news that are relevant for them, are often confounded by their impulsive decision-processes (which we refer to as System-1), e.g., spend time on click-bait news. As a result, it is difficult to infer whether an observed engagement is utility-driven or impulse-driven. In this paper we explore a new approach to recommender systems where we infer user utility based on their return probability to the platform rather than engagement signals. Our intuition is that users tend to return to a platform in the long run if it creates utility for them, while pure engagement-driven interactions that do not add utility, may affect user return in the short term but will not have a lasting effect. We propose a generative model in which past content interactions impact the arrival rates of users based on a self-exciting Hawkes process. These arrival rates to the platform are a combination of both System-1 and System-2 decision processes. The System-2 arrival intensity depends on the utility and has a long lasting effect, while the System-1 intensity depends on the instantaneous gratification and tends to vanish rapidly. We show analytically that given samples it is possible to disentangle System-1 and System-2 and allow content optimization based on user utility. We conduct experiments on synthetic data to demonstrate the effectiveness of our approach.
Code Llama: Open Foundation Models for Code
Aug 25, 2023
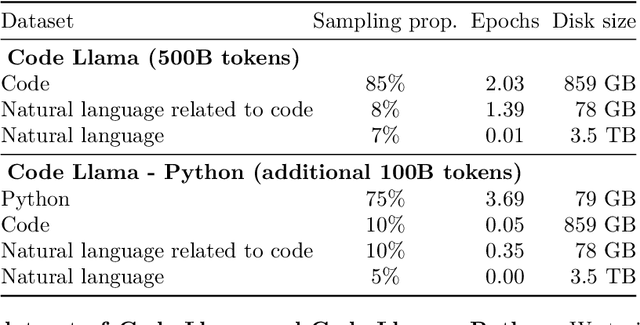
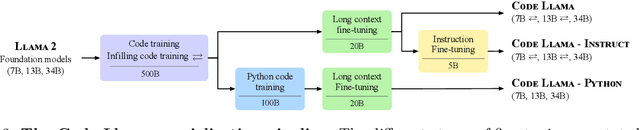
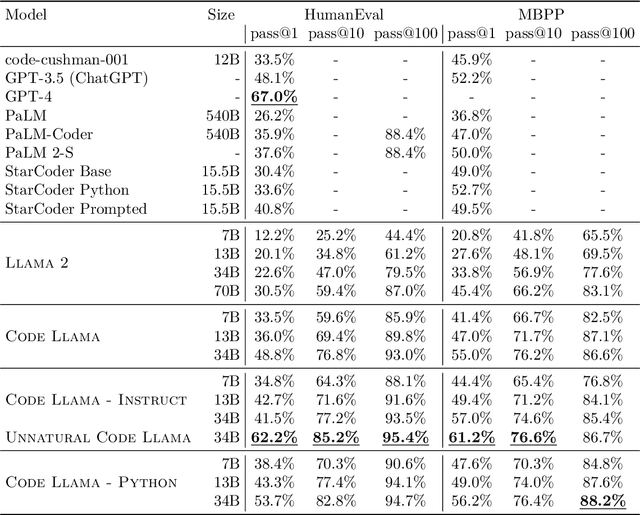
We release Code Llama, a family of large language models for code based on Llama 2 providing state-of-the-art performance among open models, infilling capabilities, support for large input contexts, and zero-shot instruction following ability for programming tasks. We provide multiple flavors to cover a wide range of applications: foundation models (Code Llama), Python specializations (Code Llama - Python), and instruction-following models (Code Llama - Instruct) with 7B, 13B and 34B parameters each. All models are trained on sequences of 16k tokens and show improvements on inputs with up to 100k tokens. 7B and 13B Code Llama and Code Llama - Instruct variants support infilling based on surrounding content. Code Llama reaches state-of-the-art performance among open models on several code benchmarks, with scores of up to 53% and 55% on HumanEval and MBPP, respectively. Notably, Code Llama - Python 7B outperforms Llama 2 70B on HumanEval and MBPP, and all our models outperform every other publicly available model on MultiPL-E. We release Code Llama under a permissive license that allows for both research and commercial use.
Towards Reliable Assessments of Demographic Disparities in Multi-Label Image Classifiers
Feb 16, 2023



Disaggregated performance metrics across demographic groups are a hallmark of fairness assessments in computer vision. These metrics successfully incentivized performance improvements on person-centric tasks such as face analysis and are used to understand risks of modern models. However, there is a lack of discussion on the vulnerabilities of these measurements for more complex computer vision tasks. In this paper, we consider multi-label image classification and, specifically, object categorization tasks. First, we highlight design choices and trade-offs for measurement that involve more nuance than discussed in prior computer vision literature. These challenges are related to the necessary scale of data, definition of groups for images, choice of metric, and dataset imbalances. Next, through two case studies using modern vision models, we demonstrate that naive implementations of these assessments are brittle. We identify several design choices that look merely like implementation details but significantly impact the conclusions of assessments, both in terms of magnitude and direction (on which group the classifiers work best) of disparities. Based on ablation studies, we propose some recommendations to increase the reliability of these assessments. Finally, through a qualitative analysis we find that concepts with large disparities tend to have varying definitions and representations between groups, with inconsistencies across datasets and annotators. While this result suggests avenues for mitigation through more consistent data collection, it also highlights that ambiguous label definitions remain a challenge when performing model assessments. Vision models are expanding and becoming more ubiquitous; it is even more important that our disparity assessments accurately reflect the true performance of models.
Leveraging Demonstrations with Latent Space Priors
Oct 26, 2022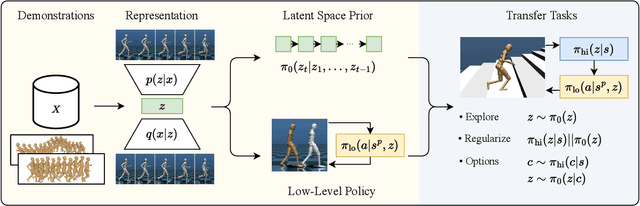
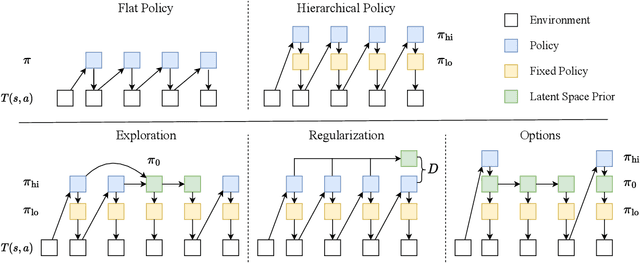

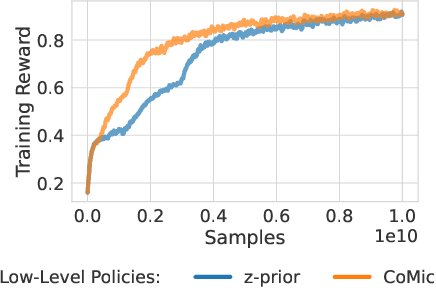
Demonstrations provide insight into relevant state or action space regions, bearing great potential to boost the efficiency and practicality of reinforcement learning agents. In this work, we propose to leverage demonstration datasets by combining skill learning and sequence modeling. Starting with a learned joint latent space, we separately train a generative model of demonstration sequences and an accompanying low-level policy. The sequence model forms a latent space prior over plausible demonstration behaviors to accelerate learning of high-level policies. We show how to acquire such priors from state-only motion capture demonstrations and explore several methods for integrating them into policy learning on transfer tasks. Our experimental results confirm that latent space priors provide significant gains in learning speed and final performance in a set of challenging sparse-reward environments with a complex, simulated humanoid. Videos, source code and pre-trained models are available at the corresponding project website at https://facebookresearch.github.io/latent-space-priors .
Contextual bandits with concave rewards, and an application to fair ranking
Oct 18, 2022
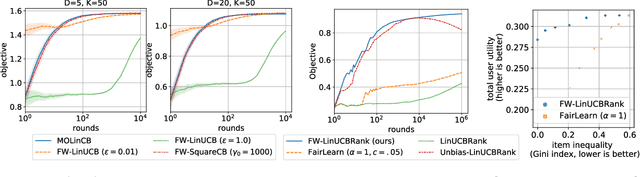
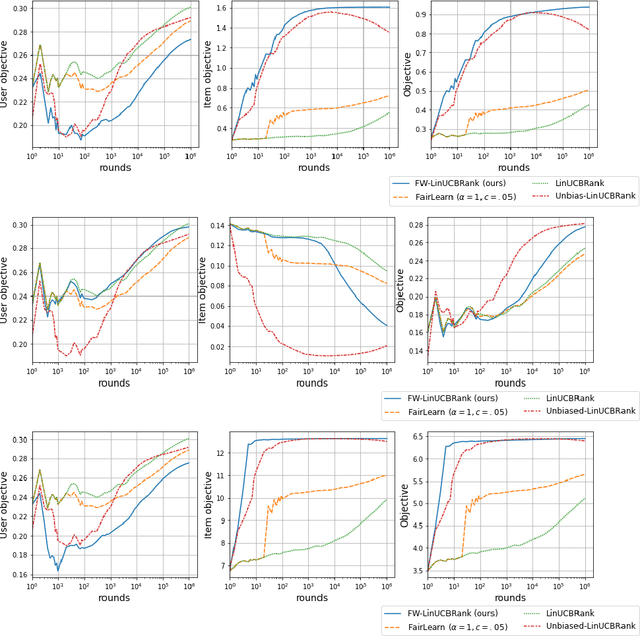
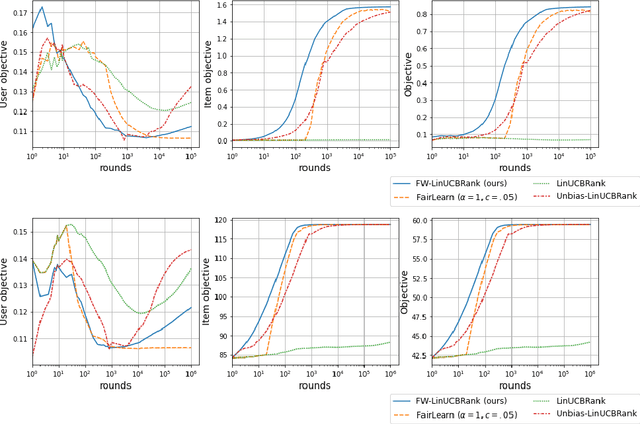
We consider Contextual Bandits with Concave Rewards (CBCR), a multi-objective bandit problem where the desired trade-off between the rewards is defined by a known concave objective function, and the reward vector depends on an observed stochastic context. We present the first algorithm with provably vanishing regret for CBCR without restrictions on the policy space, whereas prior works were restricted to finite policy spaces or tabular representations. Our solution is based on a geometric interpretation of CBCR algorithms as optimization algorithms over the convex set of expected rewards spanned by all stochastic policies. Building on Frank-Wolfe analyses in constrained convex optimization, we derive a novel reduction from the CBCR regret to the regret of a scalar-reward bandit problem. We illustrate how to apply the reduction off-the-shelf to obtain algorithms for CBCR with both linear and general reward functions, in the case of non-combinatorial actions. Motivated by fairness in recommendation, we describe a special case of CBCR with rankings and fairness-aware objectives, leading to the first algorithm with regret guarantees for contextual combinatorial bandits with fairness of exposure.