 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Reliable Assessments of Demographic Disparities in Multi-Label Image Classifiers
Feb 16, 2023



Disaggregated performance metrics across demographic groups are a hallmark of fairness assessments in computer vision. These metrics successfully incentivized performance improvements on person-centric tasks such as face analysis and are used to understand risks of modern models. However, there is a lack of discussion on the vulnerabilities of these measurements for more complex computer vision tasks. In this paper, we consider multi-label image classification and, specifically, object categorization tasks. First, we highlight design choices and trade-offs for measurement that involve more nuance than discussed in prior computer vision literature. These challenges are related to the necessary scale of data, definition of groups for images, choice of metric, and dataset imbalances. Next, through two case studies using modern vision models, we demonstrate that naive implementations of these assessments are brittle. We identify several design choices that look merely like implementation details but significantly impact the conclusions of assessments, both in terms of magnitude and direction (on which group the classifiers work best) of disparities. Based on ablation studies, we propose some recommendations to increase the reliability of these assessments. Finally, through a qualitative analysis we find that concepts with large disparities tend to have varying definitions and representations between groups, with inconsistencies across datasets and annotators. While this result suggests avenues for mitigation through more consistent data collection, it also highlights that ambiguous label definitions remain a challenge when performing model assessments. Vision models are expanding and becoming more ubiquitous; it is even more important that our disparity assessments accurately reflect the true performance of models.
Demystifying the Data Need of ML-surrogates for CFD Simulations
May 05, 2022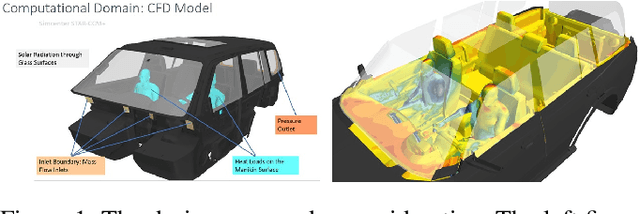
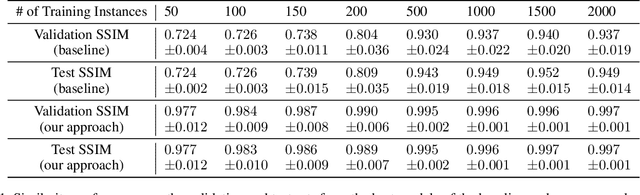
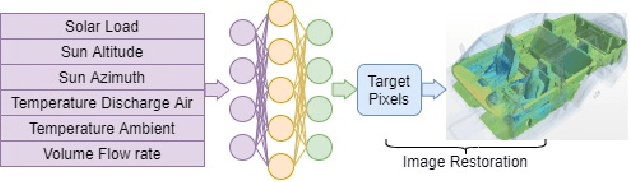
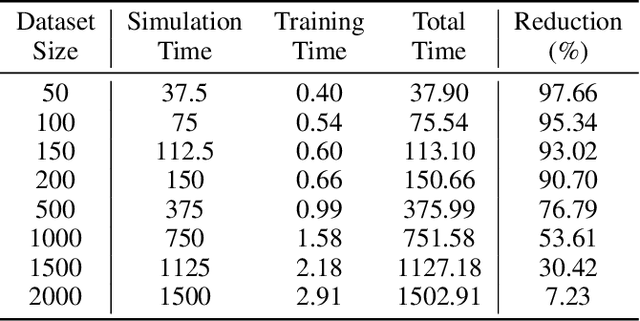
Computational fluid dynamics (CFD) simulations, a critical tool in various engineering applications, often require significant time and compute power to predict flow properties. The high computational cost associated with CFD simulations significantly restricts the scope of design space exploration and limits their use in planning and operational control. To address this issue, machine learning (ML) based surrogate models have been proposed as a computationally efficient tool to accelerate CFD simulations. However, a lack of clarity about CFD data requirements often challenges the widespread adoption of ML-based surrogates among design engineers and CFD practitioners. In this work, we propose an ML-based surrogate model to predict the temperature distribution inside the cabin of a passenger vehicle under various operating conditions and use it to demonstrate the trade-off between prediction performance and training dataset size. Our results show that the prediction accuracy is high and stable even when the training size is gradually reduced from 2000 to 200. The ML-based surrogates also reduce the compute time from ~30 minutes to around ~9 milliseconds. Moreover, even when only 50 CFD simulations are used for training, the temperature trend (e.g., locations of hot/cold regions) predicted by the ML-surrogate matches quite well with the results from CFD simulations.