 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemystifying the Data Need of ML-surrogates for CFD Simulations
Paper and Code
May 05, 2022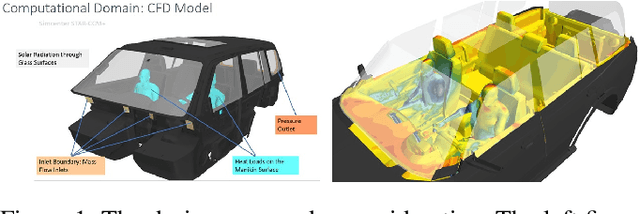
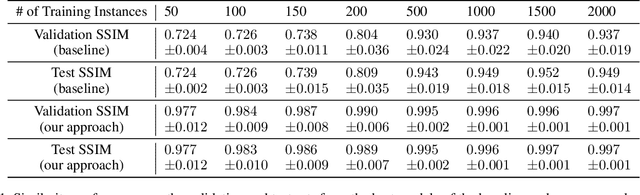
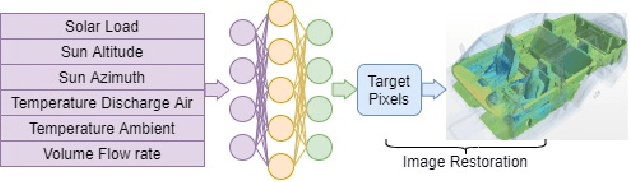
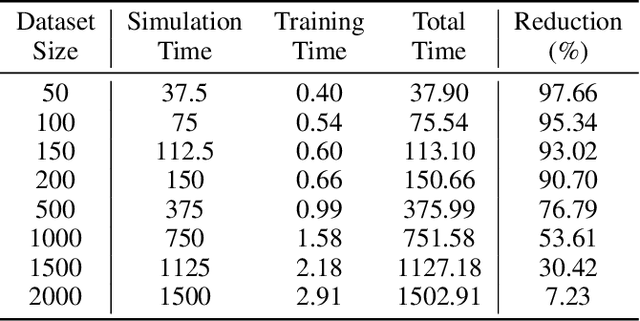
Computational fluid dynamics (CFD) simulations, a critical tool in various engineering applications, often require significant time and compute power to predict flow properties. The high computational cost associated with CFD simulations significantly restricts the scope of design space exploration and limits their use in planning and operational control. To address this issue, machine learning (ML) based surrogate models have been proposed as a computationally efficient tool to accelerate CFD simulations. However, a lack of clarity about CFD data requirements often challenges the widespread adoption of ML-based surrogates among design engineers and CFD practitioners. In this work, we propose an ML-based surrogate model to predict the temperature distribution inside the cabin of a passenger vehicle under various operating conditions and use it to demonstrate the trade-off between prediction performance and training dataset size. Our results show that the prediction accuracy is high and stable even when the training size is gradually reduced from 2000 to 200. The ML-based surrogates also reduce the compute time from ~30 minutes to around ~9 milliseconds. Moreover, even when only 50 CFD simulations are used for training, the temperature trend (e.g., locations of hot/cold regions) predicted by the ML-surrogate matches quite well with the results from CFD simulations.