 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding the Fragility of Multilingual LLMs against Fine-Tuning Attacks
Oct 23, 2024Recent advancements in Large Language Models (LLMs) have sparked widespread concerns about their safety. Recent work demonstrates that safety alignment of LLMs can be easily removed by fine-tuning with a few adversarially chosen instruction-following examples, i.e., fine-tuning attacks. We take a further step to understand fine-tuning attacks in multilingual LLMs. We first discover cross-lingual generalization of fine-tuning attacks: using a few adversarially chosen instruction-following examples in one language, multilingual LLMs can also be easily compromised (e.g., multilingual LLMs fail to refuse harmful prompts in other languages). Motivated by this finding, we hypothesize that safety-related information is language-agnostic and propose a new method termed Safety Information Localization (SIL) to identify the safety-related information in the model parameter space. Through SIL, we validate this hypothesis and find that only changing 20% of weight parameters in fine-tuning attacks can break safety alignment across all languages. Furthermore, we provide evidence to the alternative pathways hypothesis for why freezing safety-related parameters does not prevent fine-tuning attacks, and we demonstrate that our attack vector can still jailbreak LLMs adapted to new languages.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Mitigating the Impact of Labeling Errors on Training via Rockafellian Relaxation
May 30, 2024



Labeling errors in datasets are common, if not systematic, in practice. They naturally arise in a variety of contexts-human labeling, noisy labeling, and weak labeling (i.e., image classification), for example. This presents a persistent and pervasive stress on machine learning practice. In particular, neural network (NN) architectures can withstand minor amounts of dataset imperfection with traditional countermeasures such as regularization, data augmentation, and batch normalization. However, major dataset imperfections often prove insurmountable. We propose and study the implementation of Rockafellian Relaxation (RR), a new loss reweighting, architecture-independent methodology, for neural network training. Experiments indicate RR can enhance standard neural network methods to achieve robust performance across classification tasks in computer vision and natural language processing (sentiment analysis). We find that RR can mitigate the effects of dataset corruption due to both (heavy) labeling error and/or adversarial perturbation, demonstrating effectiveness across a variety of data domains and machine learning tasks.
Quantifying and mitigating the impact of label errors on model disparity metrics
Oct 04, 2023



Errors in labels obtained via human annotation adversely affect a model's performance. Existing approaches propose ways to mitigate the effect of label error on a model's downstream accuracy, yet little is known about its impact on a model's disparity metrics. Here we study the effect of label error on a model's disparity metrics. We empirically characterize how varying levels of label error, in both training and test data, affect these disparity metrics. We find that group calibration and other metrics are sensitive to train-time and test-time label error -- particularly for minority groups. This disparate effect persists even for models trained with noise-aware algorithms. To mitigate the impact of training-time label error, we present an approach to estimate the influence of a training input's label on a model's group disparity metric. We empirically assess the proposed approach on a variety of datasets and find significant improvement, compared to alternative approaches, in identifying training inputs that improve a model's disparity metric. We complement the approach with an automatic relabel-and-finetune scheme that produces updated models with, provably, improved group calibration error.
Towards Reliable Assessments of Demographic Disparities in Multi-Label Image Classifiers
Feb 16, 2023



Disaggregated performance metrics across demographic groups are a hallmark of fairness assessments in computer vision. These metrics successfully incentivized performance improvements on person-centric tasks such as face analysis and are used to understand risks of modern models. However, there is a lack of discussion on the vulnerabilities of these measurements for more complex computer vision tasks. In this paper, we consider multi-label image classification and, specifically, object categorization tasks. First, we highlight design choices and trade-offs for measurement that involve more nuance than discussed in prior computer vision literature. These challenges are related to the necessary scale of data, definition of groups for images, choice of metric, and dataset imbalances. Next, through two case studies using modern vision models, we demonstrate that naive implementations of these assessments are brittle. We identify several design choices that look merely like implementation details but significantly impact the conclusions of assessments, both in terms of magnitude and direction (on which group the classifiers work best) of disparities. Based on ablation studies, we propose some recommendations to increase the reliability of these assessments. Finally, through a qualitative analysis we find that concepts with large disparities tend to have varying definitions and representations between groups, with inconsistencies across datasets and annotators. While this result suggests avenues for mitigation through more consistent data collection, it also highlights that ambiguous label definitions remain a challenge when performing model assessments. Vision models are expanding and becoming more ubiquitous; it is even more important that our disparity assessments accurately reflect the true performance of models.
Adaptive Sampling Strategies to Construct Equitable Training Datasets
Jan 31, 2022
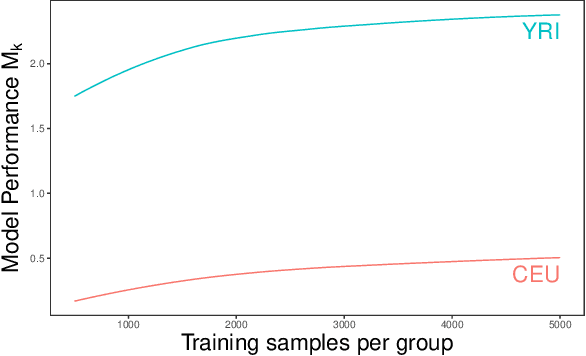
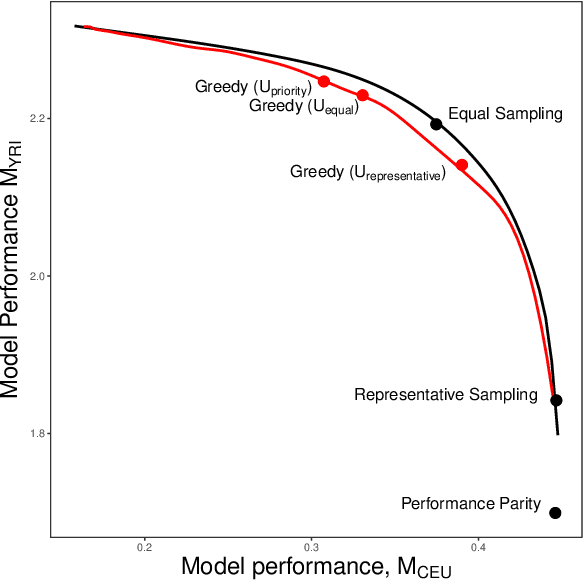
In domains ranging from computer vision to natural language processing, machine learning models have been shown to exhibit stark disparities, often performing worse for members of traditionally underserved groups. One factor contributing to these performance gaps is a lack of representation in the data the models are trained on. It is often unclear, however, how to operationalize representativeness in specific applications. Here we formalize the problem of creating equitable training datasets, and propose a statistical framework for addressing this problem. We consider a setting where a model builder must decide how to allocate a fixed data collection budget to gather training data from different subgroups. We then frame dataset creation as a constrained optimization problem, in which one maximizes a function of group-specific performance metrics based on (estimated) group-specific learning rates and costs per sample. This flexible approach incorporates preferences of model-builders and other stakeholders, as well as the statistical properties of the learning task. When data collection decisions are made sequentially, we show that under certain conditions this optimization problem can be efficiently solved even without prior knowledge of the learning rates. To illustrate our approach, we conduct a simulation study of polygenic risk scores on synthetic genomic data -- an application domain that often suffers from non-representative data collection. We find that our adaptive sampling strategy outperforms several common data collection heuristics, including equal and proportional sampling, demonstrating the value of strategic dataset design for building equitable models.
Fairness On The Ground: Applying Algorithmic Fairness Approaches to Production Systems
Mar 24, 2021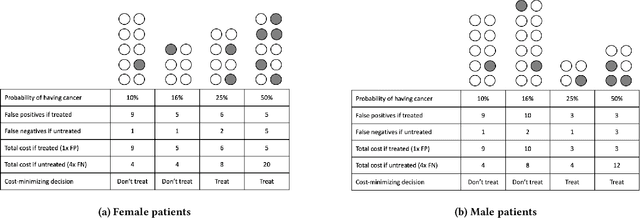
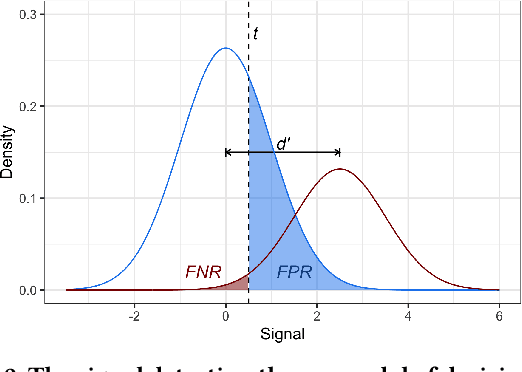
Many technical approaches have been proposed for ensuring that decisions made by machine learning systems are fair, but few of these proposals have been stress-tested in real-world systems. This paper presents an example of one team's approach to the challenge of applying algorithmic fairness approaches to complex production systems within the context of a large technology company. We discuss how we disentangle normative questions of product and policy design (like, "how should the system trade off between different stakeholders' interests and needs?") from empirical questions of system implementation (like, "is the system achieving the desired tradeoff in practice?"). We also present an approach for answering questions of the latter sort, which allows us to measure how machine learning systems and human labelers are making these tradeoffs across different relevant groups. We hope our experience integrating fairness tools and approaches into large-scale and complex production systems will be useful to other practitioners facing similar challenges, and illuminating to academics and researchers looking to better address the needs of practitioners.