 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShow, Don't Tell: Aligning Language Models with Demonstrated Feedback
Jun 02, 2024Language models are aligned to emulate the collective voice of many, resulting in outputs that align with no one in particular. Steering LLMs away from generic output is possible through supervised finetuning or RLHF, but requires prohibitively large datasets for new ad-hoc tasks. We argue that it is instead possible to align an LLM to a specific setting by leveraging a very small number ($<10$) of demonstrations as feedback. Our method, Demonstration ITerated Task Optimization (DITTO), directly aligns language model outputs to a user's demonstrated behaviors. Derived using ideas from online imitation learning, DITTO cheaply generates online comparison data by treating users' demonstrations as preferred over output from the LLM and its intermediate checkpoints. We evaluate DITTO's ability to learn fine-grained style and task alignment across domains such as news articles, emails, and blog posts. Additionally, we conduct a user study soliciting a range of demonstrations from participants ($N=16$). Across our benchmarks and user study, we find that win-rates for DITTO outperform few-shot prompting, supervised fine-tuning, and other self-play methods by an average of 19% points. By using demonstrations as feedback directly, DITTO offers a novel method for effective customization of LLMs.
Fairness On The Ground: Applying Algorithmic Fairness Approaches to Production Systems
Mar 24, 2021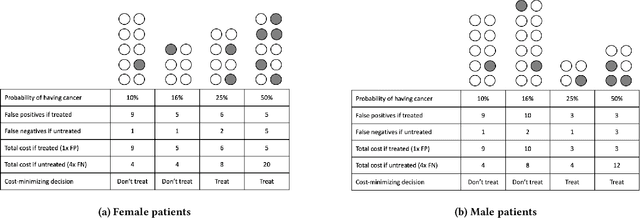
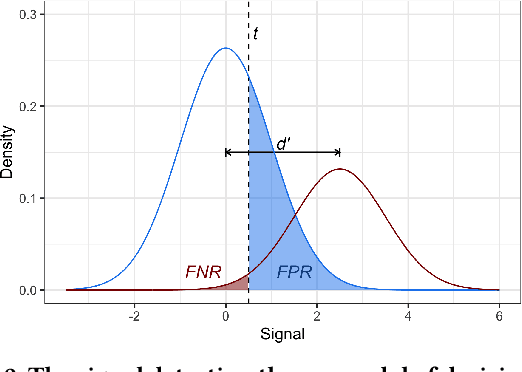
Many technical approaches have been proposed for ensuring that decisions made by machine learning systems are fair, but few of these proposals have been stress-tested in real-world systems. This paper presents an example of one team's approach to the challenge of applying algorithmic fairness approaches to complex production systems within the context of a large technology company. We discuss how we disentangle normative questions of product and policy design (like, "how should the system trade off between different stakeholders' interests and needs?") from empirical questions of system implementation (like, "is the system achieving the desired tradeoff in practice?"). We also present an approach for answering questions of the latter sort, which allows us to measure how machine learning systems and human labelers are making these tradeoffs across different relevant groups. We hope our experience integrating fairness tools and approaches into large-scale and complex production systems will be useful to other practitioners facing similar challenges, and illuminating to academics and researchers looking to better address the needs of practitioners.
Power Networks: A Novel Neural Architecture to Predict Power Relations
Jul 17, 2018

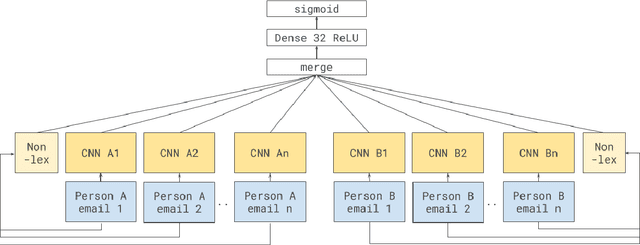

Can language analysis reveal the underlying social power relations that exist between participants of an interaction? Prior work within NLP has shown promise in this area, but the performance of automatically predicting power relations using NLP analysis of social interactions remains wanting. In this paper, we present a novel neural architecture that captures manifestations of power within individual emails which are then aggregated in an order-preserving way in order to infer the direction of power between pairs of participants in an email thread. We obtain an accuracy of 80.4%, a 10.1% improvement over state-of-the-art methods, in this task. We further apply our model to the task of predicting power relations between individuals based on the entire set of messages exchanged between them; here also, our model significantly outperforms the70.0% accuracy using prior state-of-the-art techniques, obtaining an accuracy of 83.0%.
Amanuensis: The Programmer's Apprentice
Jun 29, 2018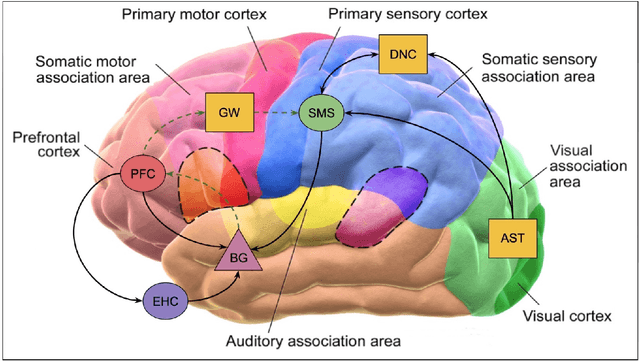

This document provides an overview of the material covered in a course taught at Stanford in the spring quarter of 2018. The course draws upon insight from cognitive and systems neuroscience to implement hybrid connectionist and symbolic reasoning systems that leverage and extend the state of the art in machine learning by integrating human and machine intelligence. As a concrete example we focus on digital assistants that learn from continuous dialog with an expert software engineer while providing initial value as powerful analytical, computational and mathematical savants. Over time these savants learn cognitive strategies (domain-relevant problem solving skills) and develop intuitions (heuristics and the experience necessary for applying them) by learning from their expert associates. By doing so these savants elevate their innate analytical skills allowing them to partner on an equal footing as versatile collaborators - effectively serving as cognitive extensions and digital prostheses, thereby amplifying and emulating their human partner's conceptually-flexible thinking patterns and enabling improved access to and control over powerful computing resources.