 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAR: SocioTechnical Approach to Red Teaming Language Models
Jun 17, 2024This research introduces STAR, a sociotechnical framework that improves on current best practices for red teaming safety of large language models. STAR makes two key contributions: it enhances steerability by generating parameterised instructions for human red teamers, leading to improved coverage of the risk surface. Parameterised instructions also provide more detailed insights into model failures at no increased cost. Second, STAR improves signal quality by matching demographics to assess harms for specific groups, resulting in more sensitive annotations. STAR further employs a novel step of arbitration to leverage diverse viewpoints and improve label reliability, treating disagreement not as noise but as a valuable contribution to signal quality.
Sociotechnical Safety Evaluation of Generative AI Systems
Oct 31, 2023Generative AI systems produce a range of risks. To ensure the safety of generative AI systems, these risks must be evaluated. In this paper, we make two main contributions toward establishing such evaluations. First, we propose a three-layered framework that takes a structured, sociotechnical approach to evaluating these risks. This framework encompasses capability evaluations, which are the main current approach to safety evaluation. It then reaches further by building on system safety principles, particularly the insight that context determines whether a given capability may cause harm. To account for relevant context, our framework adds human interaction and systemic impacts as additional layers of evaluation. Second, we survey the current state of safety evaluation of generative AI systems and create a repository of existing evaluations. Three salient evaluation gaps emerge from this analysis. We propose ways forward to closing these gaps, outlining practical steps as well as roles and responsibilities for different actors. Sociotechnical safety evaluation is a tractable approach to the robust and comprehensive safety evaluation of generative AI systems.
Adaptive Sampling Strategies to Construct Equitable Training Datasets
Jan 31, 2022
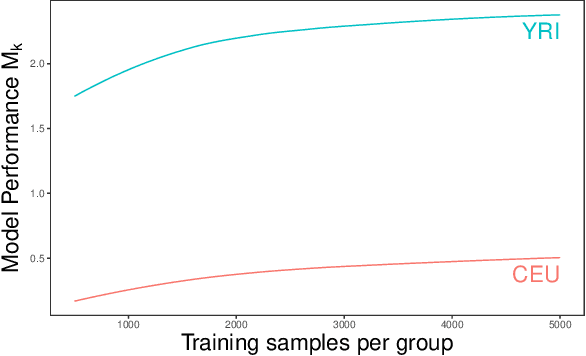
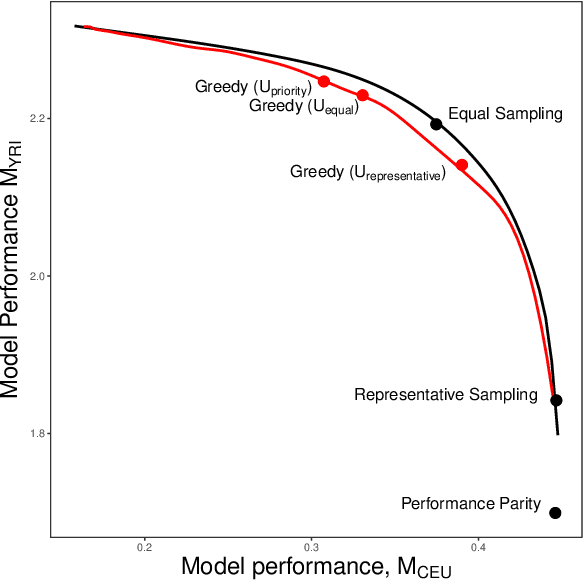
In domains ranging from computer vision to natural language processing, machine learning models have been shown to exhibit stark disparities, often performing worse for members of traditionally underserved groups. One factor contributing to these performance gaps is a lack of representation in the data the models are trained on. It is often unclear, however, how to operationalize representativeness in specific applications. Here we formalize the problem of creating equitable training datasets, and propose a statistical framework for addressing this problem. We consider a setting where a model builder must decide how to allocate a fixed data collection budget to gather training data from different subgroups. We then frame dataset creation as a constrained optimization problem, in which one maximizes a function of group-specific performance metrics based on (estimated) group-specific learning rates and costs per sample. This flexible approach incorporates preferences of model-builders and other stakeholders, as well as the statistical properties of the learning task. When data collection decisions are made sequentially, we show that under certain conditions this optimization problem can be efficiently solved even without prior knowledge of the learning rates. To illustrate our approach, we conduct a simulation study of polygenic risk scores on synthetic genomic data -- an application domain that often suffers from non-representative data collection. We find that our adaptive sampling strategy outperforms several common data collection heuristics, including equal and proportional sampling, demonstrating the value of strategic dataset design for building equitable models.
Fairness On The Ground: Applying Algorithmic Fairness Approaches to Production Systems
Mar 24, 2021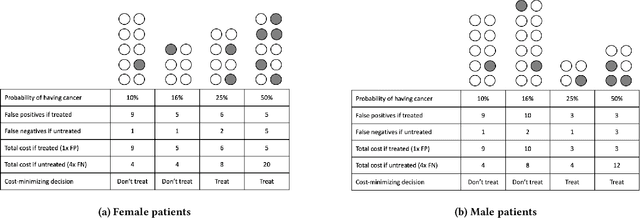
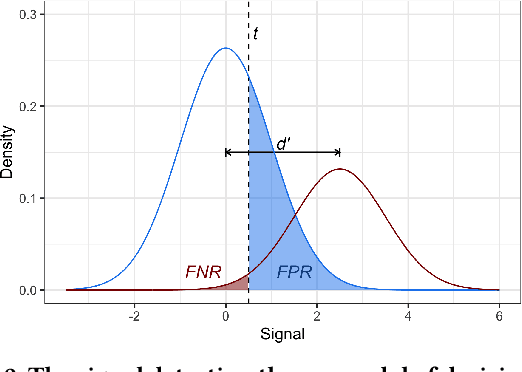
Many technical approaches have been proposed for ensuring that decisions made by machine learning systems are fair, but few of these proposals have been stress-tested in real-world systems. This paper presents an example of one team's approach to the challenge of applying algorithmic fairness approaches to complex production systems within the context of a large technology company. We discuss how we disentangle normative questions of product and policy design (like, "how should the system trade off between different stakeholders' interests and needs?") from empirical questions of system implementation (like, "is the system achieving the desired tradeoff in practice?"). We also present an approach for answering questions of the latter sort, which allows us to measure how machine learning systems and human labelers are making these tradeoffs across different relevant groups. We hope our experience integrating fairness tools and approaches into large-scale and complex production systems will be useful to other practitioners facing similar challenges, and illuminating to academics and researchers looking to better address the needs of practitioners.