 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuditing the Use of Language Models to Guide Hiring Decisions
Apr 03, 2024Regulatory efforts to protect against algorithmic bias have taken on increased urgency with rapid advances in large language models (LLMs), which are machine learning models that can achieve performance rivaling human experts on a wide array of tasks. A key theme of these initiatives is algorithmic "auditing," but current regulations -- as well as the scientific literature -- provide little guidance on how to conduct these assessments. Here we propose and investigate one approach for auditing algorithms: correspondence experiments, a widely applied tool for detecting bias in human judgements. In the employment context, correspondence experiments aim to measure the extent to which race and gender impact decisions by experimentally manipulating elements of submitted application materials that suggest an applicant's demographic traits, such as their listed name. We apply this method to audit candidate assessments produced by several state-of-the-art LLMs, using a novel corpus of applications to K-12 teaching positions in a large public school district. We find evidence of moderate race and gender disparities, a pattern largely robust to varying the types of application material input to the models, as well as the framing of the task to the LLMs. We conclude by discussing some important limitations of correspondence experiments for auditing algorithms.
LegalBench: A Collaboratively Built Benchmark for Measuring Legal Reasoning in Large Language Models
Aug 20, 2023
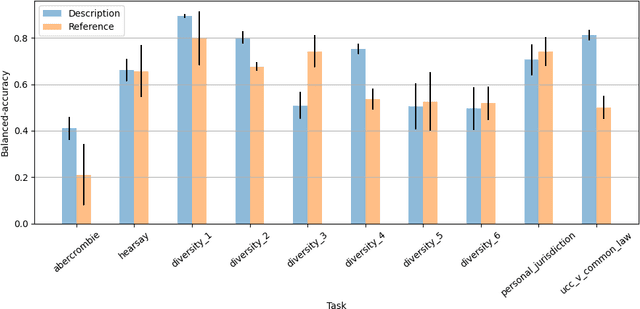
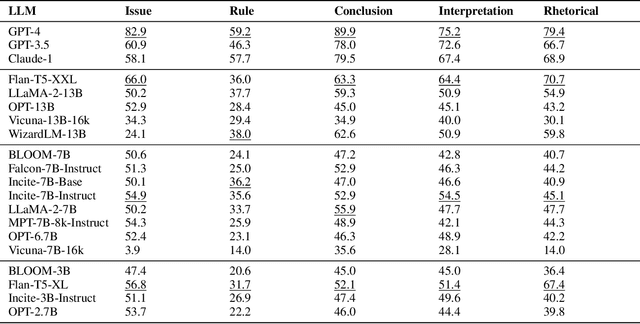
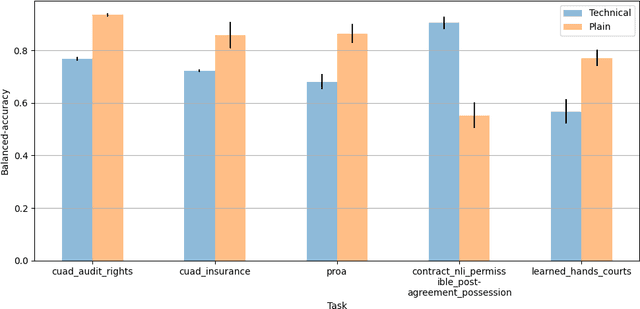
The advent of large language models (LLMs) and their adoption by the legal community has given rise to the question: what types of legal reasoning can LLMs perform? To enable greater study of this question, we present LegalBench: a collaboratively constructed legal reasoning benchmark consisting of 162 tasks covering six different types of legal reasoning. LegalBench was built through an interdisciplinary process, in which we collected tasks designed and hand-crafted by legal professionals. Because these subject matter experts took a leading role in construction, tasks either measure legal reasoning capabilities that are practically useful, or measure reasoning skills that lawyers find interesting. To enable cross-disciplinary conversations about LLMs in the law, we additionally show how popular legal frameworks for describing legal reasoning -- which distinguish between its many forms -- correspond to LegalBench tasks, thus giving lawyers and LLM developers a common vocabulary. This paper describes LegalBench, presents an empirical evaluation of 20 open-source and commercial LLMs, and illustrates the types of research explorations LegalBench enables.
Designing Equitable Algorithms
Feb 17, 2023Predictive algorithms are now used to help distribute a large share of our society's resources and sanctions, such as healthcare, loans, criminal detentions, and tax audits. Under the right circumstances, these algorithms can improve the efficiency and equity of decision-making. At the same time, there is a danger that the algorithms themselves could entrench and exacerbate disparities, particularly along racial, ethnic, and gender lines. To help ensure their fairness, many researchers suggest that algorithms be subject to at least one of three constraints: (1) no use of legally protected features, such as race, ethnicity, and gender; (2) equal rates of "positive" decisions across groups; and (3) equal error rates across groups. Here we show that these constraints, while intuitively appealing, often worsen outcomes for individuals in marginalized groups, and can even leave all groups worse off. The inherent trade-off we identify between formal fairness constraints and welfare improvements -- particularly for the marginalized -- highlights the need for a more robust discussion on what it means for an algorithm to be "fair". We illustrate these ideas with examples from healthcare and the criminal-legal system, and make several proposals to help practitioners design more equitable algorithms.
Causal Conceptions of Fairness and their Consequences
Jul 12, 2022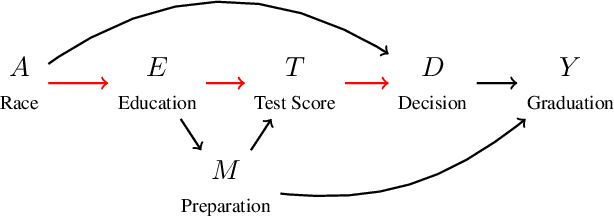
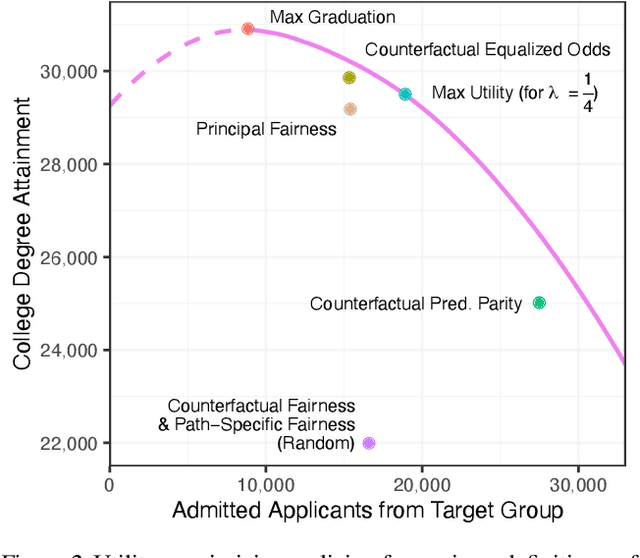
Recent work highlights the role of causality in designing equitable decision-making algorithms. It is not immediately clear, however, how existing causal conceptions of fairness relate to one another, or what the consequences are of using these definitions as design principles. Here, we first assemble and categorize popular causal definitions of algorithmic fairness into two broad families: (1) those that constrain the effects of decisions on counterfactual disparities; and (2) those that constrain the effects of legally protected characteristics, like race and gender, on decisions. We then show, analytically and empirically, that both families of definitions \emph{almost always} -- in a measure theoretic sense -- result in strongly Pareto dominated decision policies, meaning there is an alternative, unconstrained policy favored by every stakeholder with preferences drawn from a large, natural class. For example, in the case of college admissions decisions, policies constrained to satisfy causal fairness definitions would be disfavored by every stakeholder with neutral or positive preferences for both academic preparedness and diversity. Indeed, under a prominent definition of causal fairness, we prove the resulting policies require admitting all students with the same probability, regardless of academic qualifications or group membership. Our results highlight formal limitations and potential adverse consequences of common mathematical notions of causal fairness.
* ICML 2022
Adaptive Sampling Strategies to Construct Equitable Training Datasets
Jan 31, 2022
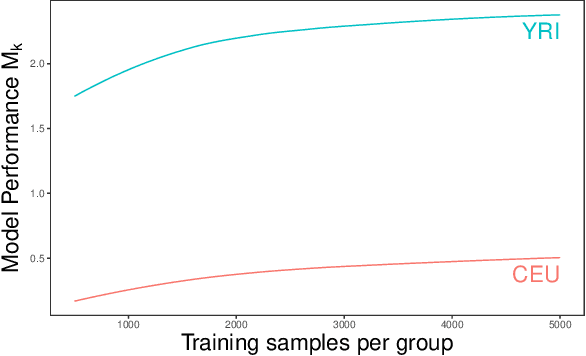
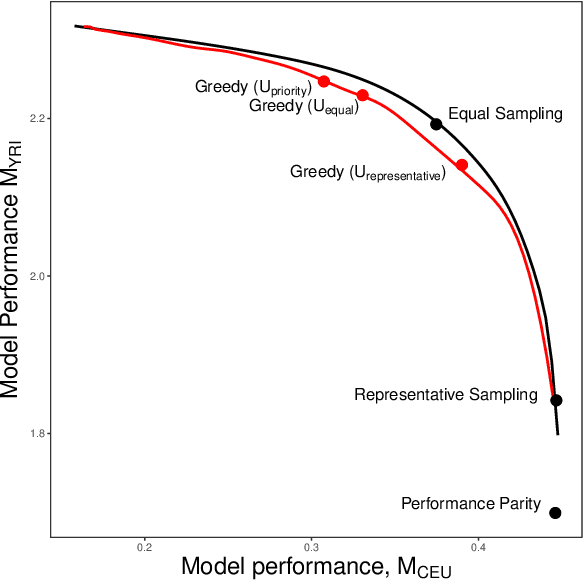
In domains ranging from computer vision to natural language processing, machine learning models have been shown to exhibit stark disparities, often performing worse for members of traditionally underserved groups. One factor contributing to these performance gaps is a lack of representation in the data the models are trained on. It is often unclear, however, how to operationalize representativeness in specific applications. Here we formalize the problem of creating equitable training datasets, and propose a statistical framework for addressing this problem. We consider a setting where a model builder must decide how to allocate a fixed data collection budget to gather training data from different subgroups. We then frame dataset creation as a constrained optimization problem, in which one maximizes a function of group-specific performance metrics based on (estimated) group-specific learning rates and costs per sample. This flexible approach incorporates preferences of model-builders and other stakeholders, as well as the statistical properties of the learning task. When data collection decisions are made sequentially, we show that under certain conditions this optimization problem can be efficiently solved even without prior knowledge of the learning rates. To illustrate our approach, we conduct a simulation study of polygenic risk scores on synthetic genomic data -- an application domain that often suffers from non-representative data collection. We find that our adaptive sampling strategy outperforms several common data collection heuristics, including equal and proportional sampling, demonstrating the value of strategic dataset design for building equitable models.
Learning to be Fair: A Consequentialist Approach to Equitable Decision-Making
Sep 18, 2021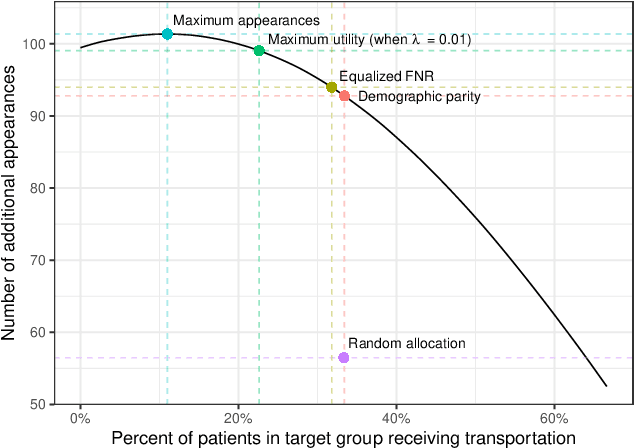
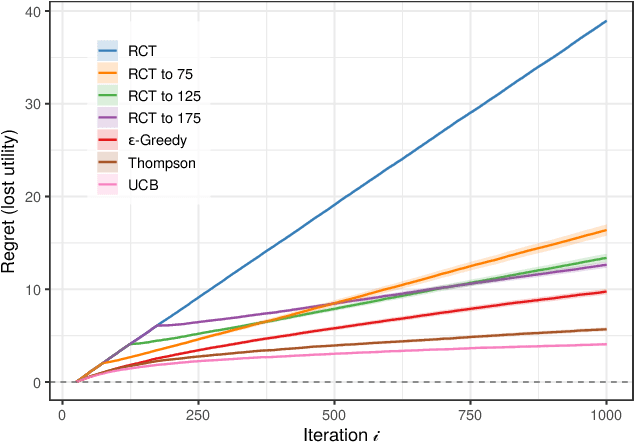
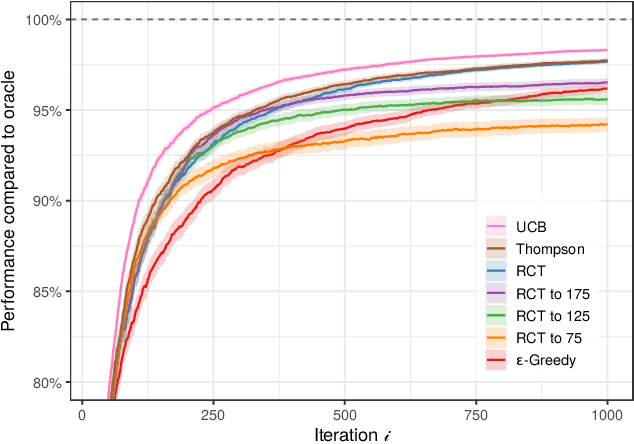
In the dominant paradigm for designing equitable machine learning systems, one works to ensure that model predictions satisfy various fairness criteria, such as parity in error rates across race, gender, and other legally protected traits. That approach, however, typically divorces predictions from the downstream outcomes they ultimately affect, and, as a result, can induce unexpected harms. Here we present an alternative framework for fairness that directly anticipates the consequences of actions. Stakeholders first specify preferences over the possible outcomes of an algorithmically informed decision-making process. For example, lenders may prefer extending credit to those most likely to repay a loan, while also preferring similar lending rates across neighborhoods. One then searches the space of decision policies to maximize the specified utility. We develop and describe a method for efficiently learning these optimal policies from data for a large family of expressive utility functions, facilitating a more holistic approach to equitable decision-making.
Probability Paths and the Structure of Predictions over Time
Jun 11, 2021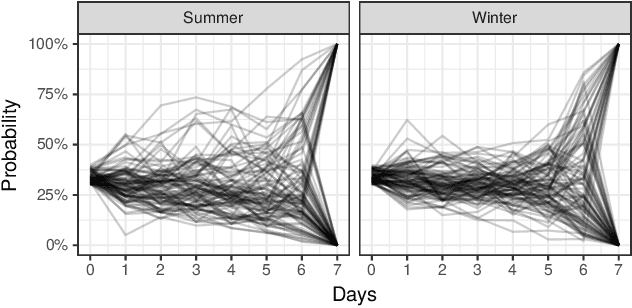
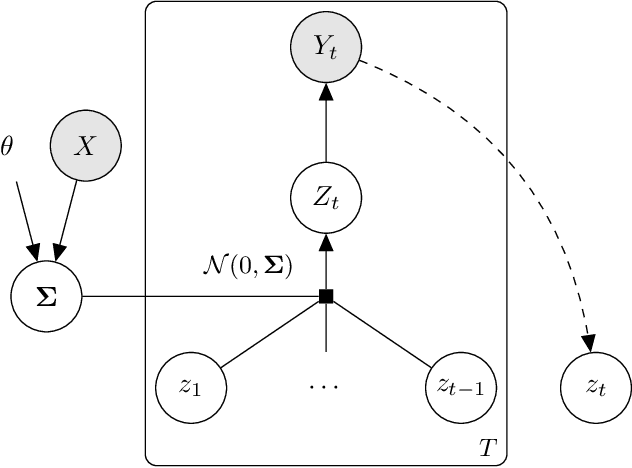
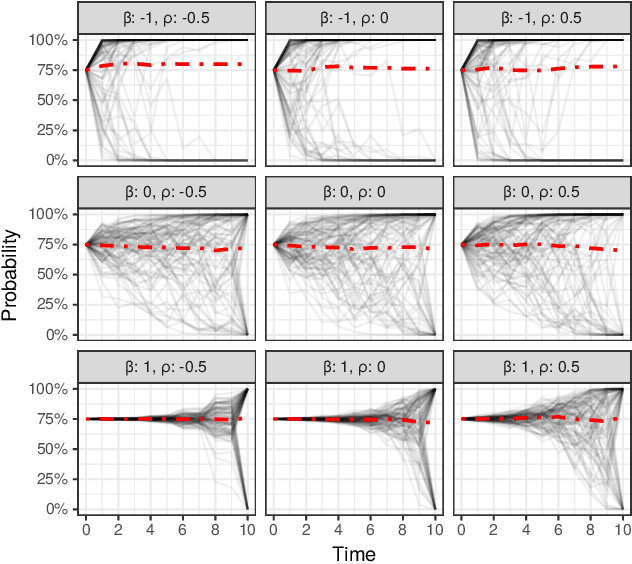
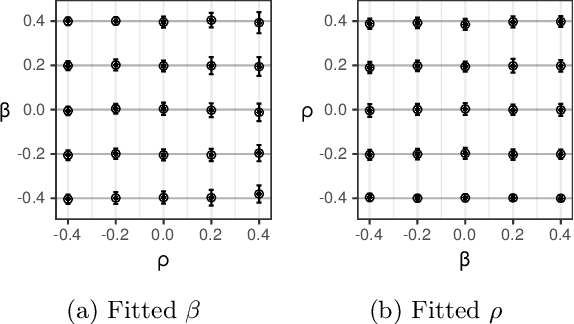
In settings ranging from weather forecasts to political prognostications to financial projections, probability estimates of future binary outcomes often evolve over time. For example, the estimated likelihood of rain on a specific day changes by the hour as new information becomes available. Given a collection of such probability paths, we introduce a Bayesian framework -- which we call the Gaussian latent information martingale, or GLIM -- for modeling the structure of dynamic predictions over time. Suppose, for example, that the likelihood of rain in a week is 50%, and consider two hypothetical scenarios. In the first, one expects the forecast is equally likely to become either 25% or 75% tomorrow; in the second, one expects the forecast to stay constant for the next several days. A time-sensitive decision-maker might select a course of action immediately in the latter scenario, but may postpone their decision in the former, knowing that new information is imminent. We model these trajectories by assuming predictions update according to a latent process of information flow, which is inferred from historical data. In contrast to general methods for time series analysis, this approach preserves the martingale structure of probability paths and better quantifies future uncertainties around probability paths. We show that GLIM outperforms three popular baseline methods, producing better estimated posterior probability path distributions measured by three different metrics. By elucidating the dynamic structure of predictions over time, we hope to help individuals make more informed choices.
Surveilling Surveillance: Estimating the Prevalence of Surveillance Cameras with Street View Data
May 04, 2021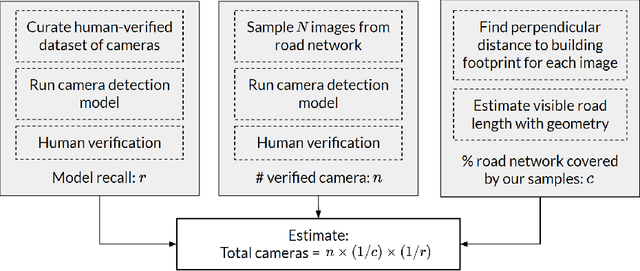
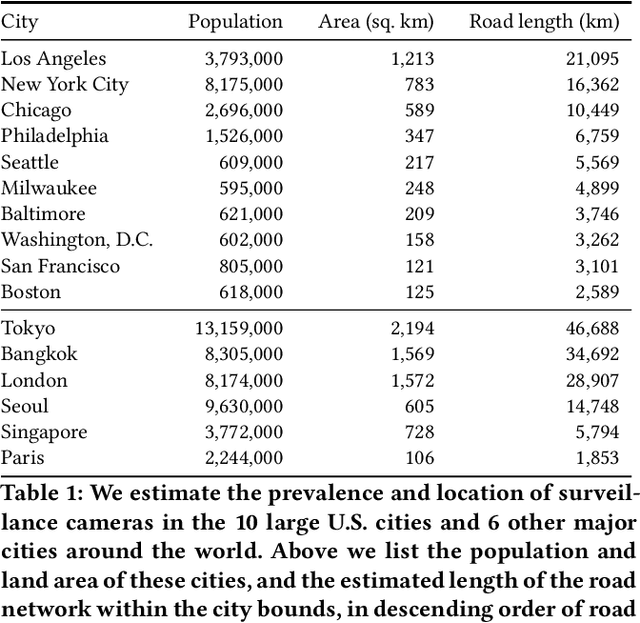


The use of video surveillance in public spaces -- both by government agencies and by private citizens -- has attracted considerable attention in recent years, particularly in light of rapid advances in face-recognition technology. But it has been difficult to systematically measure the prevalence and placement of cameras, hampering efforts to assess the implications of surveillance on privacy and public safety. Here we present a novel approach for estimating the spatial distribution of surveillance cameras: applying computer vision algorithms to large-scale street view image data. Specifically, we build a camera detection model and apply it to 1.6 million street view images sampled from 10 large U.S. cities and 6 other major cities around the world, with positive model detections verified by human experts. After adjusting for the estimated recall of our model, and accounting for the spatial coverage of our sampled images, we are able to estimate the density of surveillance cameras visible from the road. Across the 16 cities we consider, the estimated number of surveillance cameras per linear kilometer ranges from 0.1 (in Seattle) to 0.9 (in Seoul). In a detailed analysis of the 10 U.S. cities, we find that cameras are concentrated in commercial, industrial, and mixed zones, and in neighborhoods with higher shares of non-white residents -- a pattern that persists even after adjusting for land use. These results help inform ongoing discussions on the use of surveillance technology, including its potential disparate impacts on communities of color.
Fast Threshold Tests for Detecting Discrimination
Mar 10, 2018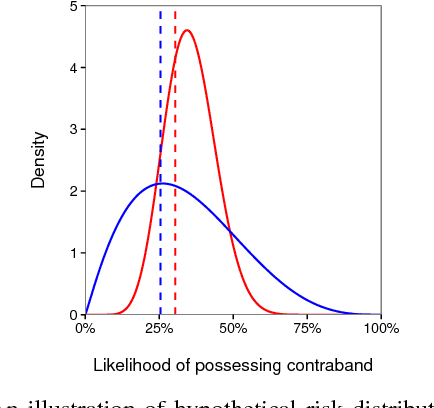

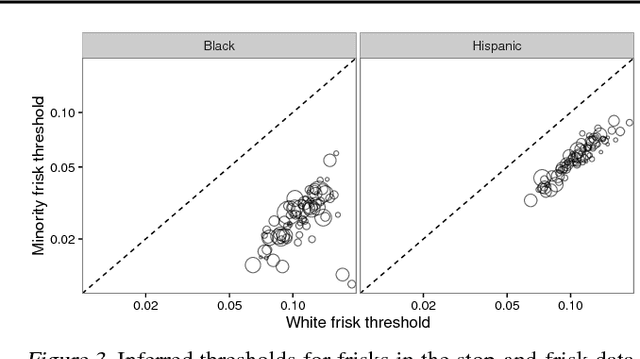
Threshold tests have recently been proposed as a useful method for detecting bias in lending, hiring, and policing decisions. For example, in the case of credit extensions, these tests aim to estimate the bar for granting loans to white and minority applicants, with a higher inferred threshold for minorities indicative of discrimination. This technique, however, requires fitting a complex Bayesian latent variable model for which inference is often computationally challenging. Here we develop a method for fitting threshold tests that is two orders of magnitude faster than the existing approach, reducing computation from hours to minutes. To achieve these performance gains, we introduce and analyze a flexible family of probability distributions on the interval [0, 1] -- which we call discriminant distributions -- that is computationally efficient to work with. We demonstrate our technique by analyzing 2.7 million police stops of pedestrians in New York City.
Simple rules for complex decisions
Apr 02, 2017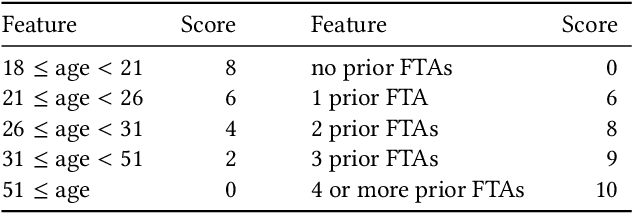
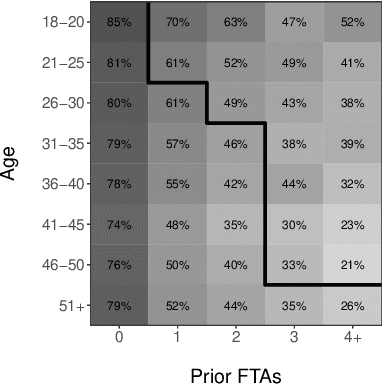
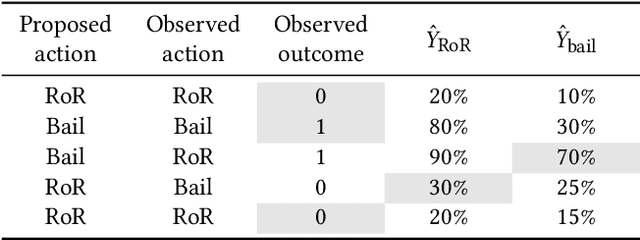
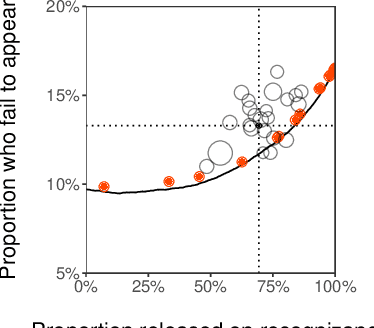
From doctors diagnosing patients to judges setting bail, experts often base their decisions on experience and intuition rather than on statistical models. While understandable, relying on intuition over models has often been found to result in inferior outcomes. Here we present a new method, select-regress-and-round, for constructing simple rules that perform well for complex decisions. These rules take the form of a weighted checklist, can be applied mentally, and nonetheless rival the performance of modern machine learning algorithms. Our method for creating these rules is itself simple, and can be carried out by practitioners with basic statistics knowledge. We demonstrate this technique with a detailed case study of judicial decisions to release or detain defendants while they await trial. In this application, as in many policy settings, the effects of proposed decision rules cannot be directly observed from historical data: if a rule recommends releasing a defendant that the judge in reality detained, we do not observe what would have happened under the proposed action. We address this key counterfactual estimation problem by drawing on tools from causal inference. We find that simple rules significantly outperform judges and are on par with decisions derived from random forests trained on all available features. Generalizing to 22 varied decision-making domains, we find this basic result replicates. We conclude with an analytical framework that helps explain why these simple decision rules perform as well as they do.